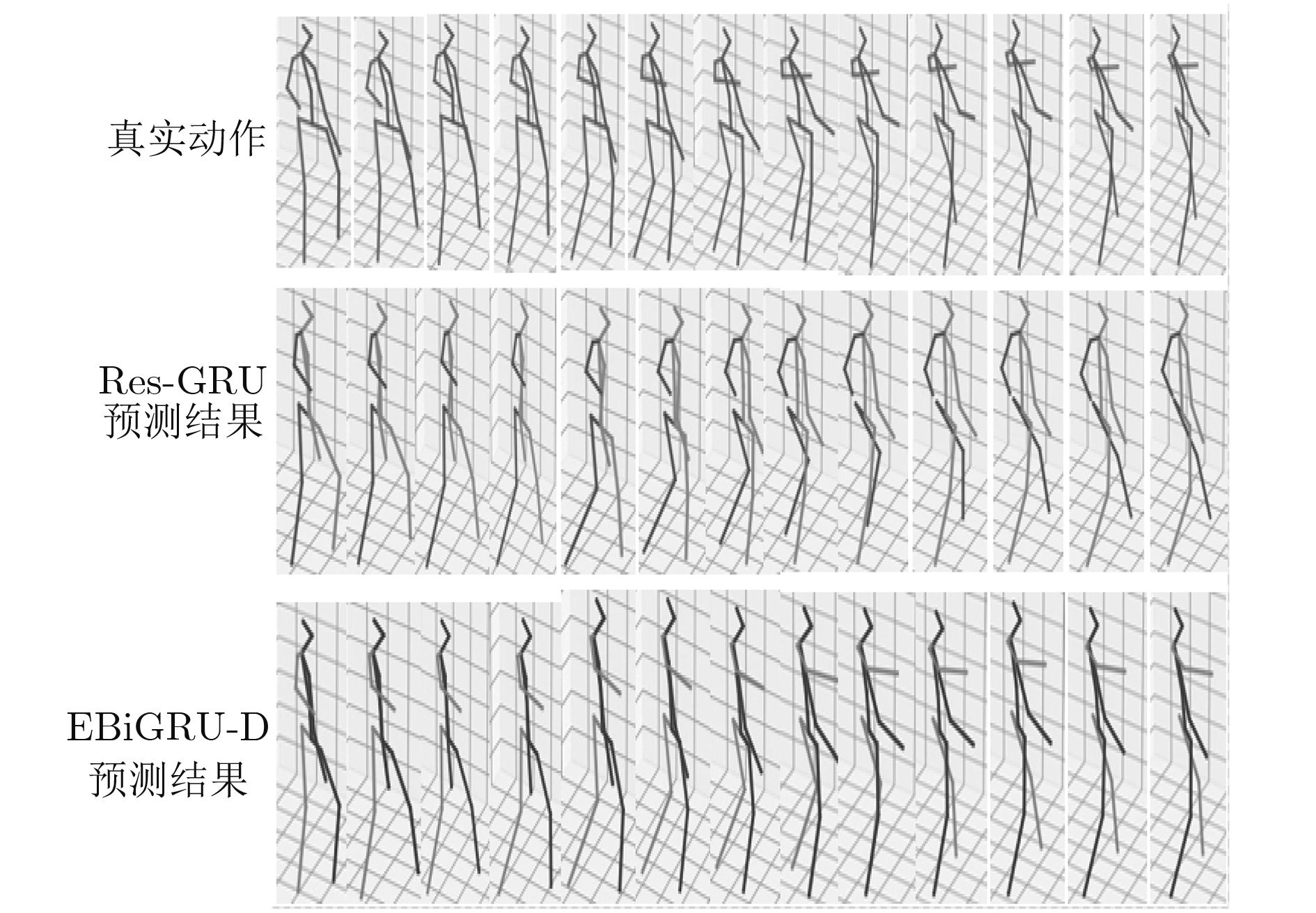
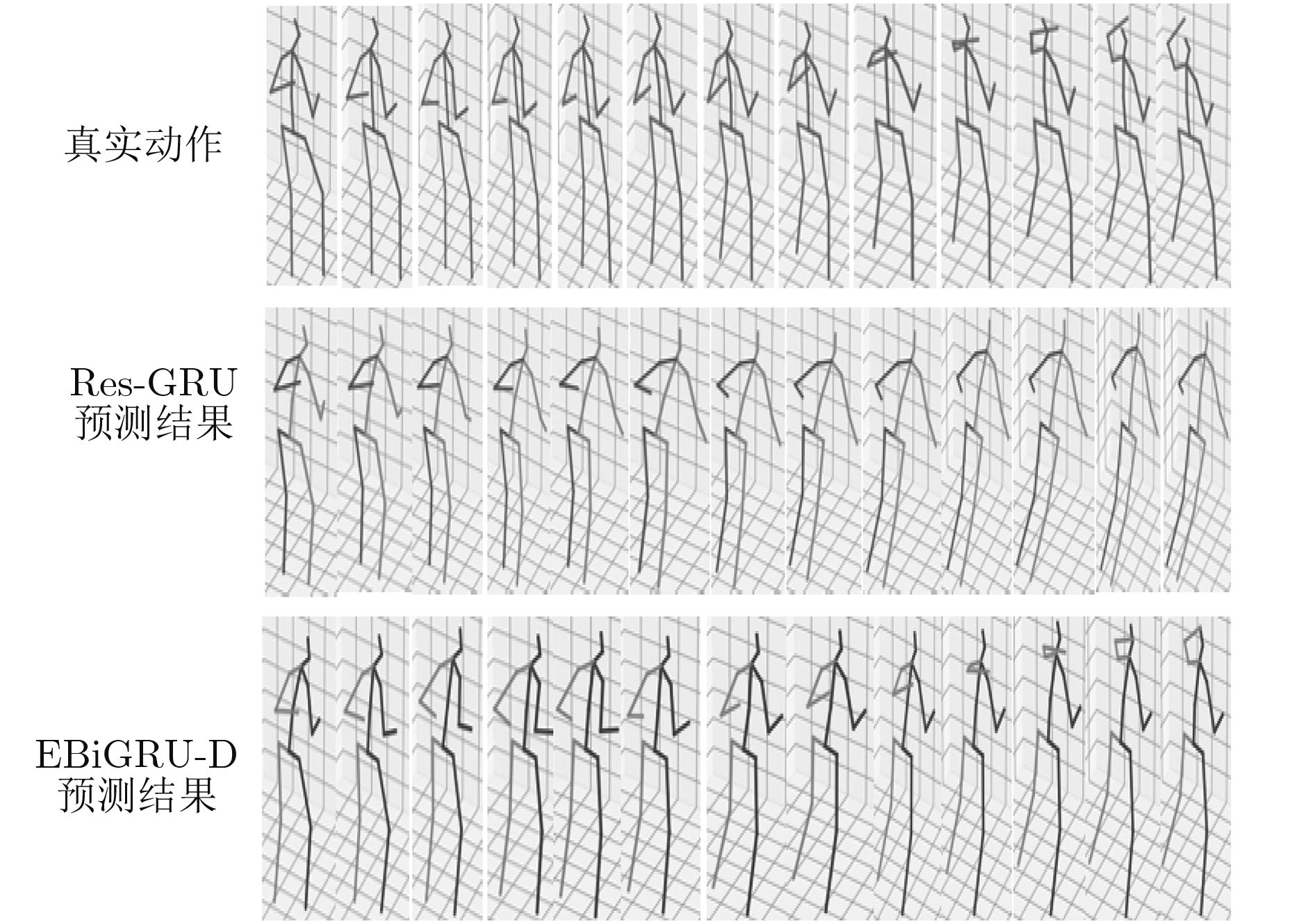
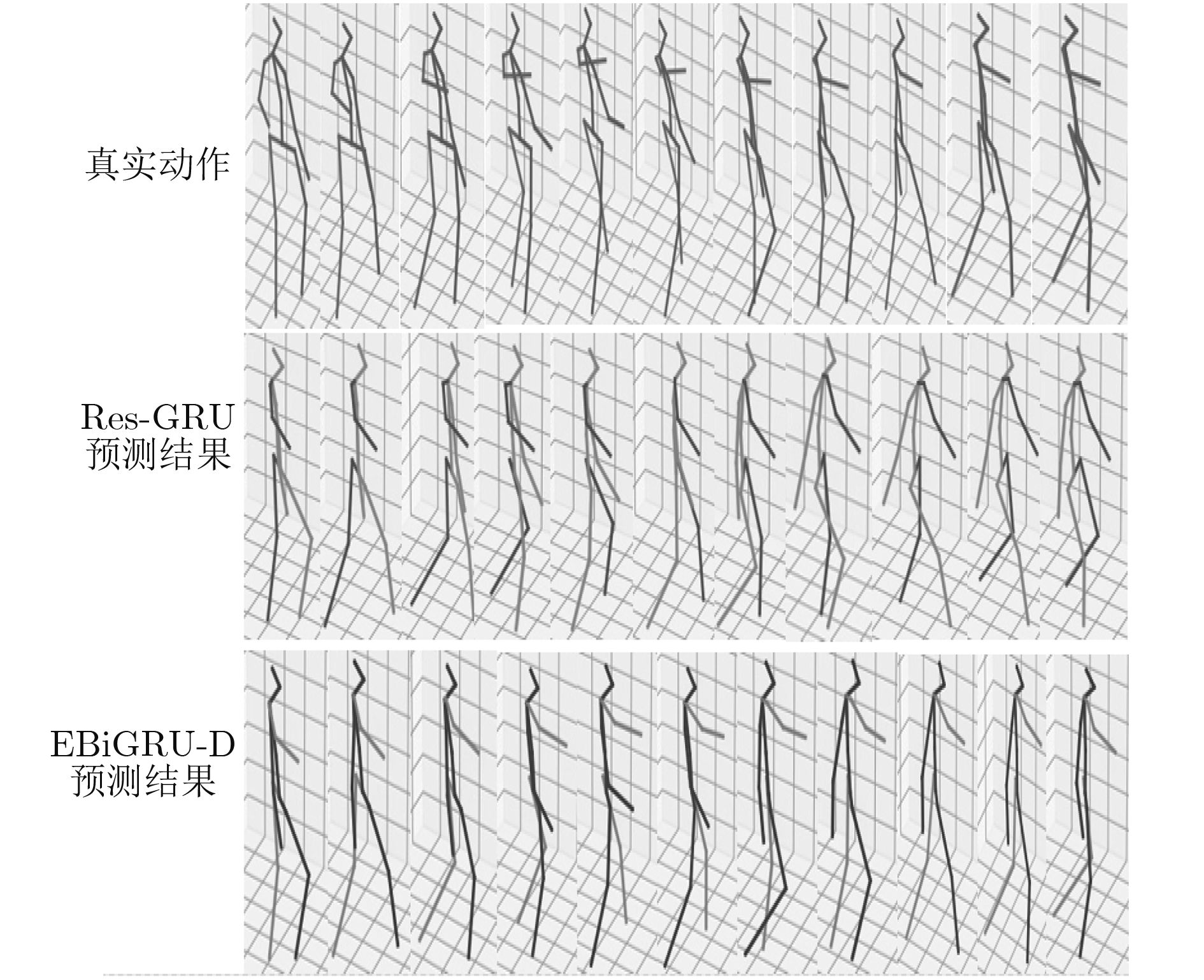
| Citation: | Haifeng SANG, Zizhen CHEN. 3D Human Motion Prediction Based on Bi-directionalGated Recurrent Unit[J]. Journal of Electronics & Information Technology, 2019, 41(9): 2256-2263. doi: 10.11999/JEIT180978

|

|
FOKA A F and TRAHANIAS P E. Probabilistic autonomous robot navigation in dynamic environments with human motion prediction[J]. International Journal of Social Robotics, 2010, 2(1): 79–94. doi: 10.1007/s12369-009-0037-z
|
|
MAINPRICE J and BERENSON D. Human–robot collaborative manipulation planning using early prediction of human motion[C]. 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 2013: 299–306.
|
|
BÜTEPAGE J, BLACK M J, KRAGIC D, et al. Deep representation learning for human motion prediction and classification[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 1591–1599.
|
|
TEKIN B, MÁRQUEZ–NEILA P, SALZMANN M, et al. Learning to fuse 2D and 3D image cues for monocular body pose estimation[C]. 2017 IEEE International Conference on Computer Vision, Venice, Italy, 2017: 3961–3970.
|
|
YASIN H, IQBAL U, KRÜGER B, et al. A dual–source approach for 3D pose estimation from a single image[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 4948–4956.
|
|
肖俊, 庄越挺, 吴飞. 三维人体运动特征可视化与交互式运动分割[J]. 软件学报, 2008, 19(8): 1995–2003.
XIAO Jun, ZHUANG Yueting, and WU Fei. Feature visualization and interactive segmentation of 3D human motion[J]. Journal of Software, 2008, 19(8): 1995–2003.
|
|
潘红, 肖俊, 吴飞, 等. 基于关键帧的三维人体运动检索[J]. 计算机辅助设计与图形学学报, 2009, 21(2): 214–222.
PAN Hong, XIAO Jun, WU Fei, et al. 3D human motion retrieval based on key-frames[J]. Journal of Computer-Aided Design &Computer Graphics, 2009, 21(2): 214–222.
|
|
LI Rui, LIU Zhenyu, and TAN Jianrong. Human motion segmentation using collaborative representations of 3D skeletal sequences[J]. IET Computer Vision, 2018, 12(4): 434–442. doi: 10.1049/iet-cvi.2016.0385
|
|
TAYLOR G W, HINTON G E, and ROWEIS S. Modeling human motion using binary latent variables[C]. The 19th International Conference on Neural Information Processing Systems, Hong Kong, China, 2006: 1345–1352.
|
|
FRAGKIADAKI K, LEVINE S, FELSEN P, et al. Recurrent network models for human dynamics[C]. The IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4346–4354.
|
|
HOLDEN D, SAITO J, and KOMURA T. A deep learning framework for character motion synthesis and editing[J]. ACM Transactions on Graphics, 2016, 35(4): 1–11.
|
|
ASHESH J, ZAMIR A R, SAVARESE S, et al. Structural-RNN: Deep learning on spatio–temporal graphs[C]. IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 2016: 5308–5317.
|
|
MARTINEZ J, BLACK M J, and ROMERO J. On human motion prediction using recurrent neural networks[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4674–4683.
|
|
TANG Yongyi, MA Lin, LIU Wei, et al. Long–term human motion prediction by modeling motion context and enhancing motion dynamic[J/OL]. arXiv: 1805.02513. http://arxiv.org/abs/1805.02513, 2018.
|
|
ZHANG Yachao, LIU Kaipei, QIN Liang, et al. Deterministic and probabilistic interval prediction for short&-term wind power generation based on variational mode decomposition and machine learning methods[J]. Energy Conversion and Management, 2016, 112: 208–219. doi: 10.1016/j.enconman.2016.01.023
|
|
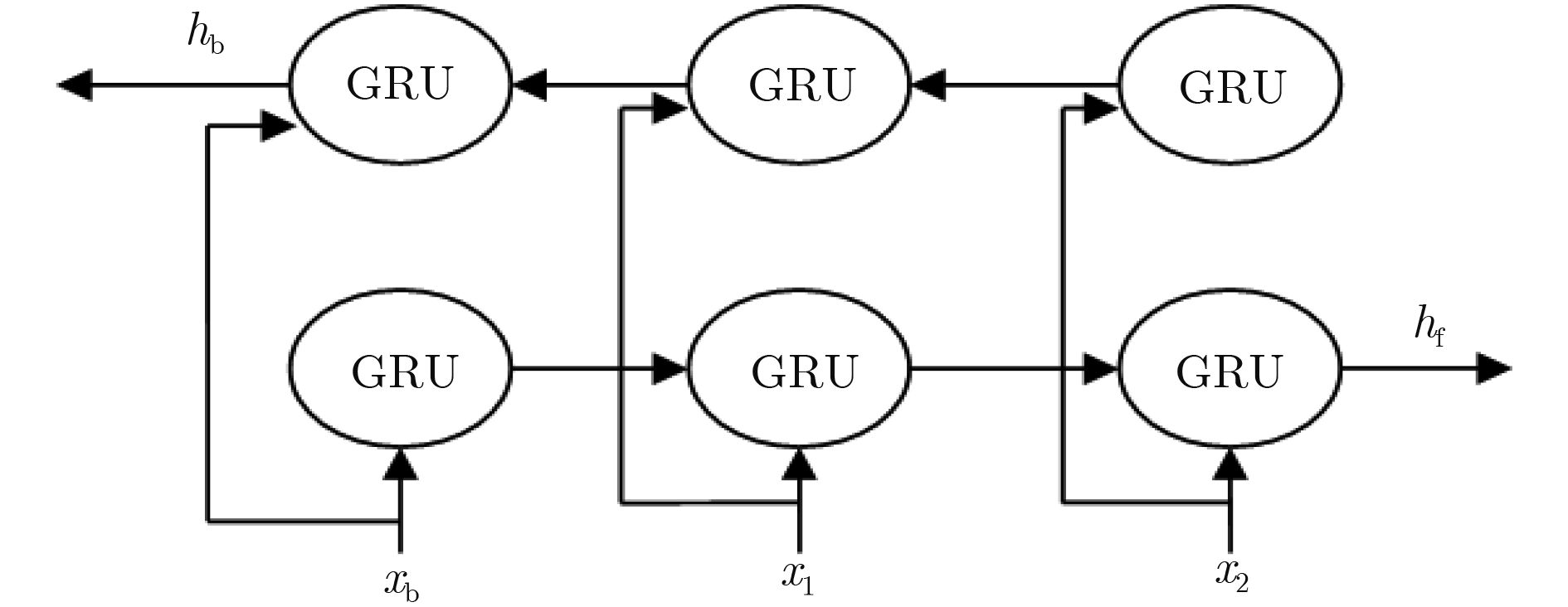
CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J/OL]. arXiv: 1406.1078, 2014.
|

Figures(8) / Tables(2)



 DownLoad:
DownLoad: