| Citation: | Zibin DAI, Anqi YIN, Tongzhou QU, Longmei NAN. Efficient Workload Balance Technology on Many-core Crypto Processor[J]. Journal of Electronics & Information Technology, 2019, 41(2): 369-376. doi: 10.11999/JEIT180623

|
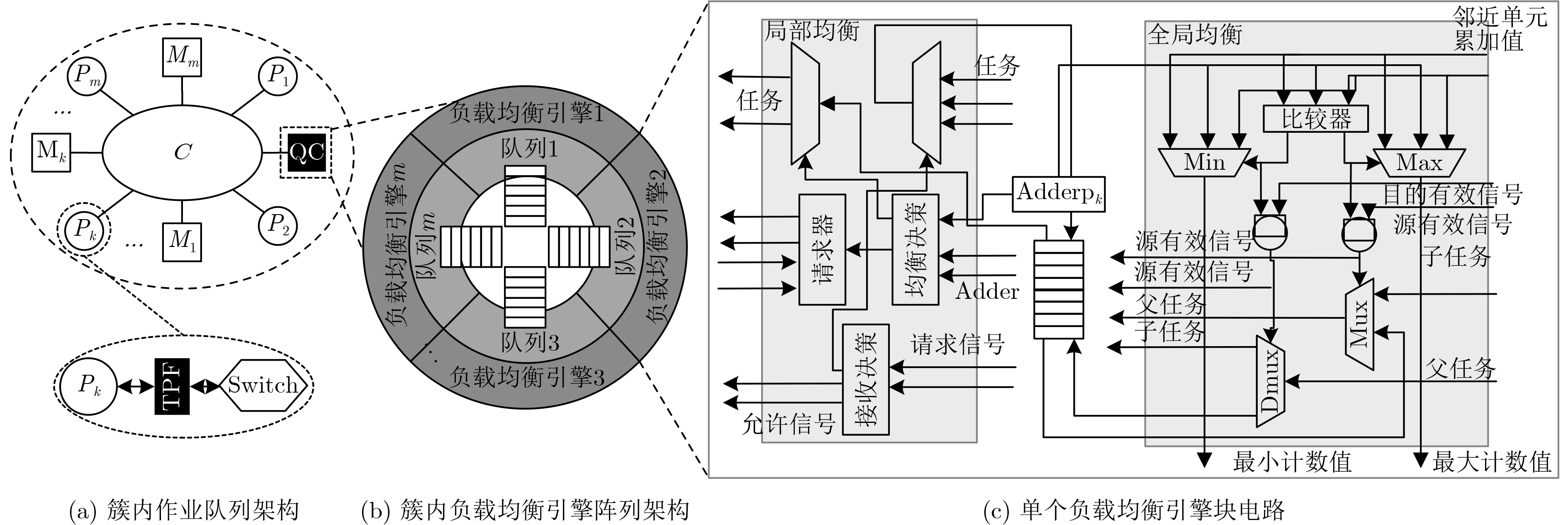
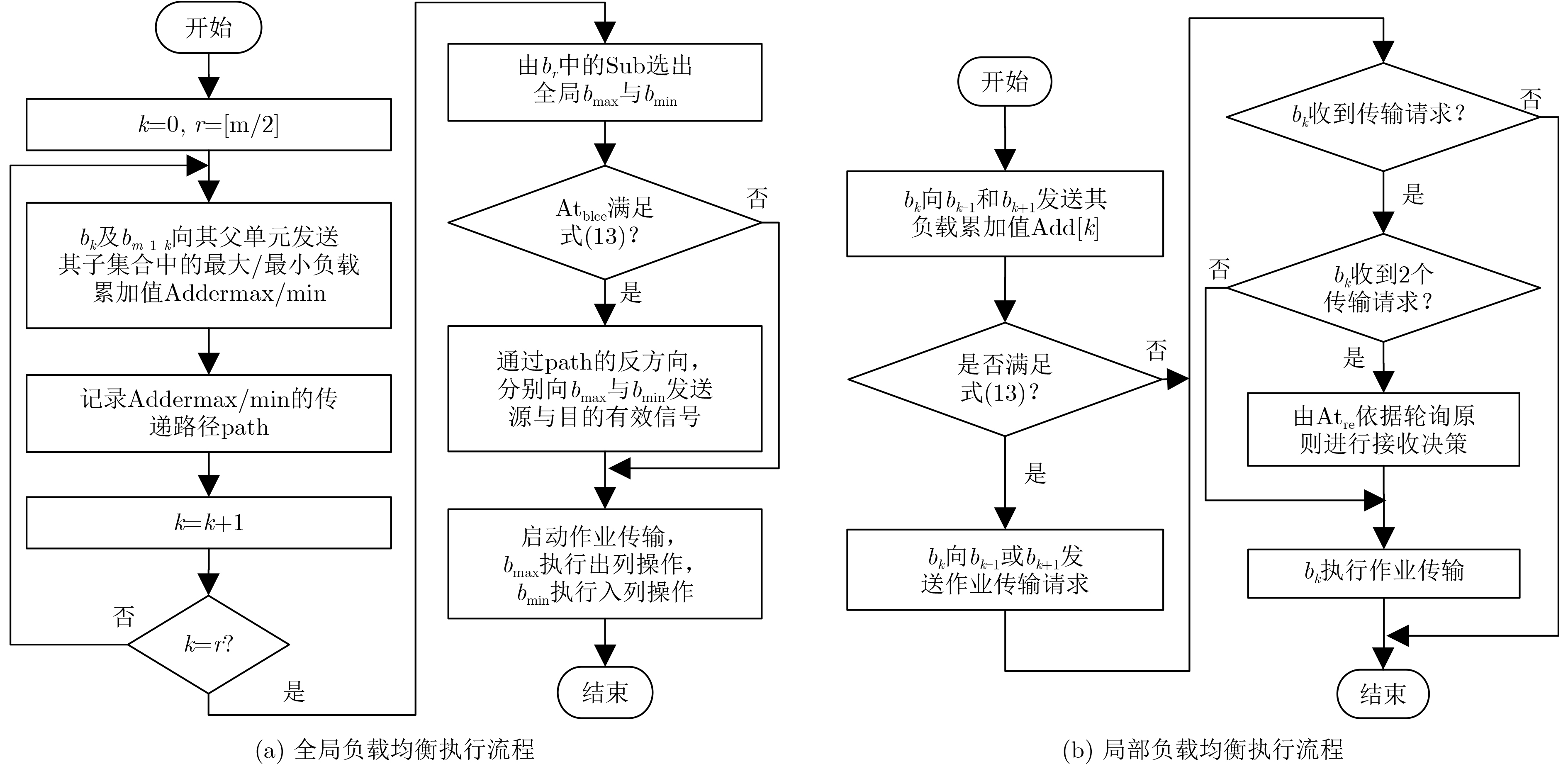
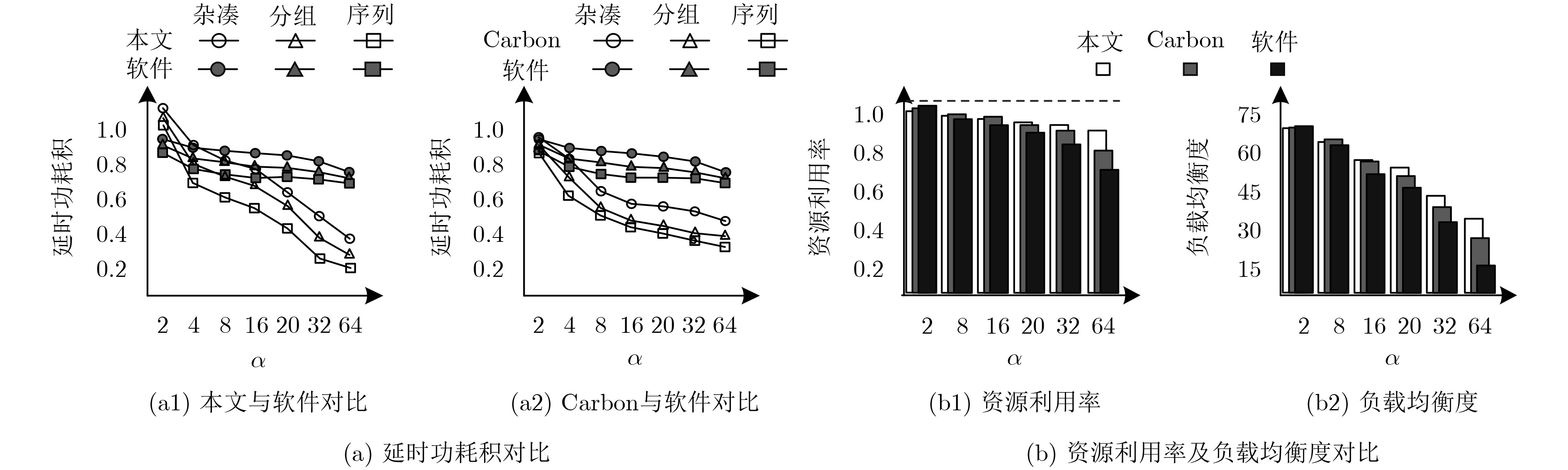
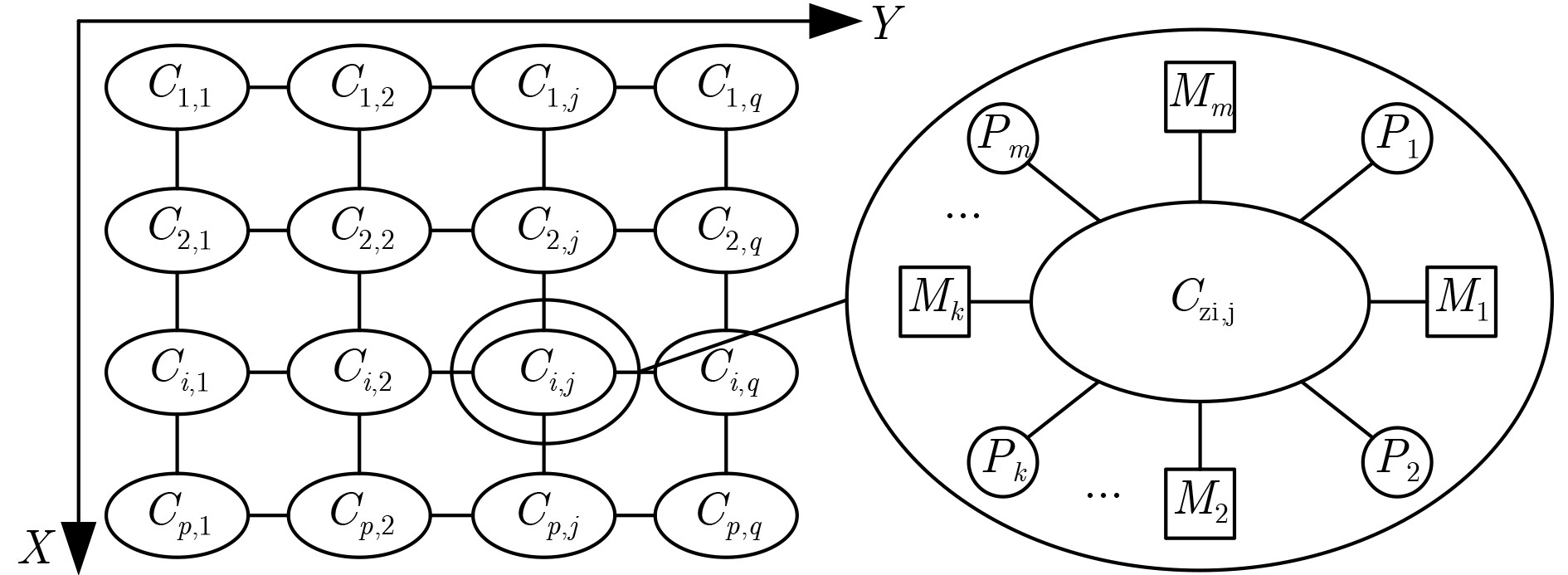
Imbalanced workload distribution results in low resource utilization of many-core crypto-platform. Dynamic workload allocation can improve the resource utilization with some overhead. Therefore, a higher frequency of workload balancing is not equivalent to higher gains. This paper establishes a mathematical model for gain rate and frequency of workload balancing. Based on this model, a collision-free workload balancing policy is proposed for many-core crypto systems, and a hierarchical "expandable-portable" engine is put forward, which consists of "Inter-cluster micro-network and intra-cluster ring-array" adopting hardware job queue technology. Experiment results show that the proposed workload-balancing engine is 4.06, 7.17, 23.01% and 2.15 times higher than the software technology based on " job stealing” in terms of performance, delay power consumption, resource utilization and workload balance; 1.75, 2.45, 10.2%, and 1.41 times better compared with the hardware technology based on "job stealing". By contrast with the ideal hardware technology, the average throughput of encryption algorithms is only decreased by 5.67% (the lowest 3%). The experiment also proves the scalability and portability of the proposed technique.

|
KIM C and HUH J. Exploring the design space of fair scheduling supports for asymmetric multicore systems[J]. IEEE Transactions on Computers, 2018, 67(8): 1136–1152. doi: 10.1109/TC.2018.2796077
|
|
KIM K W, CHO Y, EO J, et al. System-wide time versus density tradeoff in real-time multicore fluid scheduling[J]. IEEE Transactions on Computers, 2018, 67(7): 1007–1022. doi: 10.1109/TC.2018.2793919
|
|
LEE J, NICOPOULOS C, LEE H G, et al. IsoNet: Hardware-based job queue management for many core architectures[J]. IEEE Transactions on Very Large Scale Integration Systems, 2013, 21(6): 1080–1093. doi: 10.1109/TVLSI.2012.2202699
|
|
KUMAR S, HUGHES C J and NGUYEN A. Carbon: Architectural support for fine-grained parallelism on chip multiprocessors[C]. International Symposium on Computer Architecture, California, USA, 2007: 162–173.
|
|
CHEN J, JUANG P, KO K, et al. Hardware-modulated parallelism in chip multiprocessors[J]. ACM Sigarch Computer Architecture News, 2005, 33(4): 54–63. doi: 10.1145/1105734.1105742
|
|
LEE J, NICOPOULOS C, LEE Y, et al. Hardware-based job queue management for manycore architectures and OpenMP environments[J]. IEEE International Parallel & Distributed Processing Symposium, 2011, 21(6): 407–418. doi: 10.1109/IPDPS.2011.47
|
|
刘宗斌, 马原, 荆继武, 等. SM3哈希算法的硬件实现与研究[J]. 信息网络安全, 2011, 59(9): 191–193. doi: 10.3969/j.issn.1671-1122.2011.09.059
LIU Zongbin, MA Yuan, JING Jiwu, et al. Implementation of SM3 hash function on FPGA[J]. Information Network Security, 2011, 59(9): 191–193. doi: 10.3969/j.issn.1671-1122.2011.09.059
|
|
徐金甫, 杨宇航. SM4算法在粗粒度阵列平台的并行化映射[J]. 电子技术应用, 2017, 43(4): 39–42.
XU Jinfu and YANG Yuhang. Parallel mapping of SM4 algorithm on coarse-grained array platform[J]. Electronic Technology Application, 2017, 43(4): 39–42.
|
|
DUBEY P. Recognition, mining and synthesis moves computers to the era of tera[J]. Technology@Intel Magazine, 2005, 9(2): 1–10.
|
|
RATTNER J. Cool codes for hot chips: A quantitative basis for multi-core design[C]. Hot Chips 18 Symposium IEEE, Cupertino, USA, 2016: 1–28.
|
|
AN H, TAURA K, and SPOTTER D. A tool for spotting scheduler-caused delays in task parallel runtime systems[C]. IEEE International Conference on CLUSTER Computing, Hawaii, USA, 2017: 114–125.
|
|
KWOK Y K and AHMAD I. Static scheduling algorithms for allocating directed task graphs to multiprocessors[J]. ACM Computing Surveys, 1999, 31(4): 406–471. doi: 10.1145/344588.344618
|
|
TITHI J J, MATANI D, MENGHANI G, et al. Avoiding locks and atomic instructions in shared-memory parallel BFS using optimistic parallelization[C]. Parallel and Distributed Processing Symposium Workshops & Phd Forum IEEE, Cambridge, UK, 2013: 1628–1637.
|
|
MOON S W, REXFORD J, and SHIN K G. Scalable hardware priority queue architectures for high-speed packet switches[J]. IEEE Transactions on Computers, 2000, 49(11): 1215–1227. doi: 10.1109/RTTAS.1997.601359
|
|
CHEN Quan, ZHENG Long, and GUO Minyi. Adaptive Demand-aware Work-stealing in Multi-programmed Multi-core Architectures[J]. Concurrency and Computation: practice & Experience, 2016, 28(2): 455–471. doi: 10.1002.cpe.3619
|
Figures(6) / Tables(3)



 DownLoad:
DownLoad: