| Citation: | Xia ZOU, Penglong WU, Meng SUN, Xingyu ZHANG. An Adaptive Consistent Iterative Hard Thresholding Alogorith for Audio Declipping[J]. Journal of Electronics & Information Technology, 2019, 41(4): 925-931. doi: 10.11999/JEIT180543

|
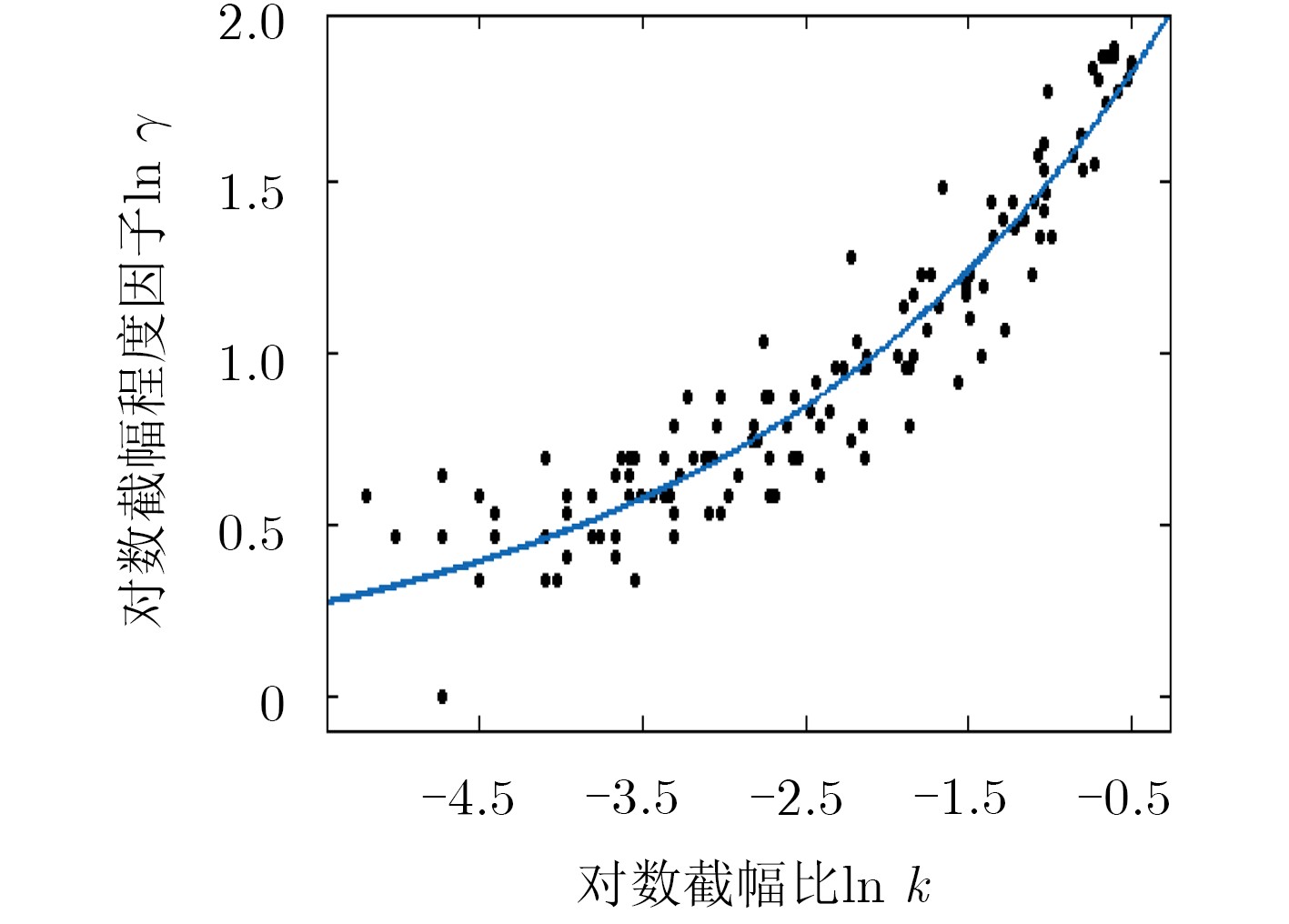
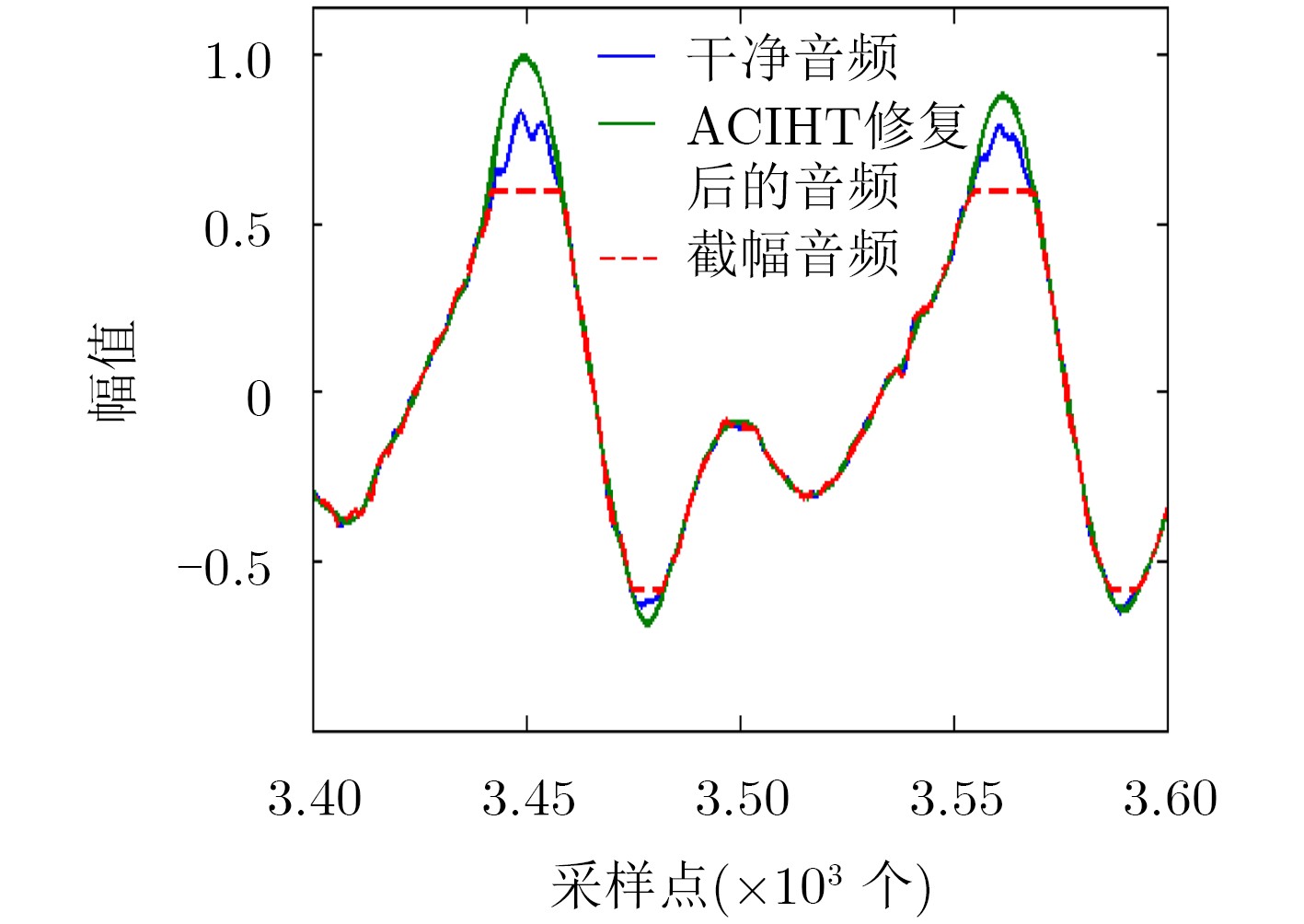
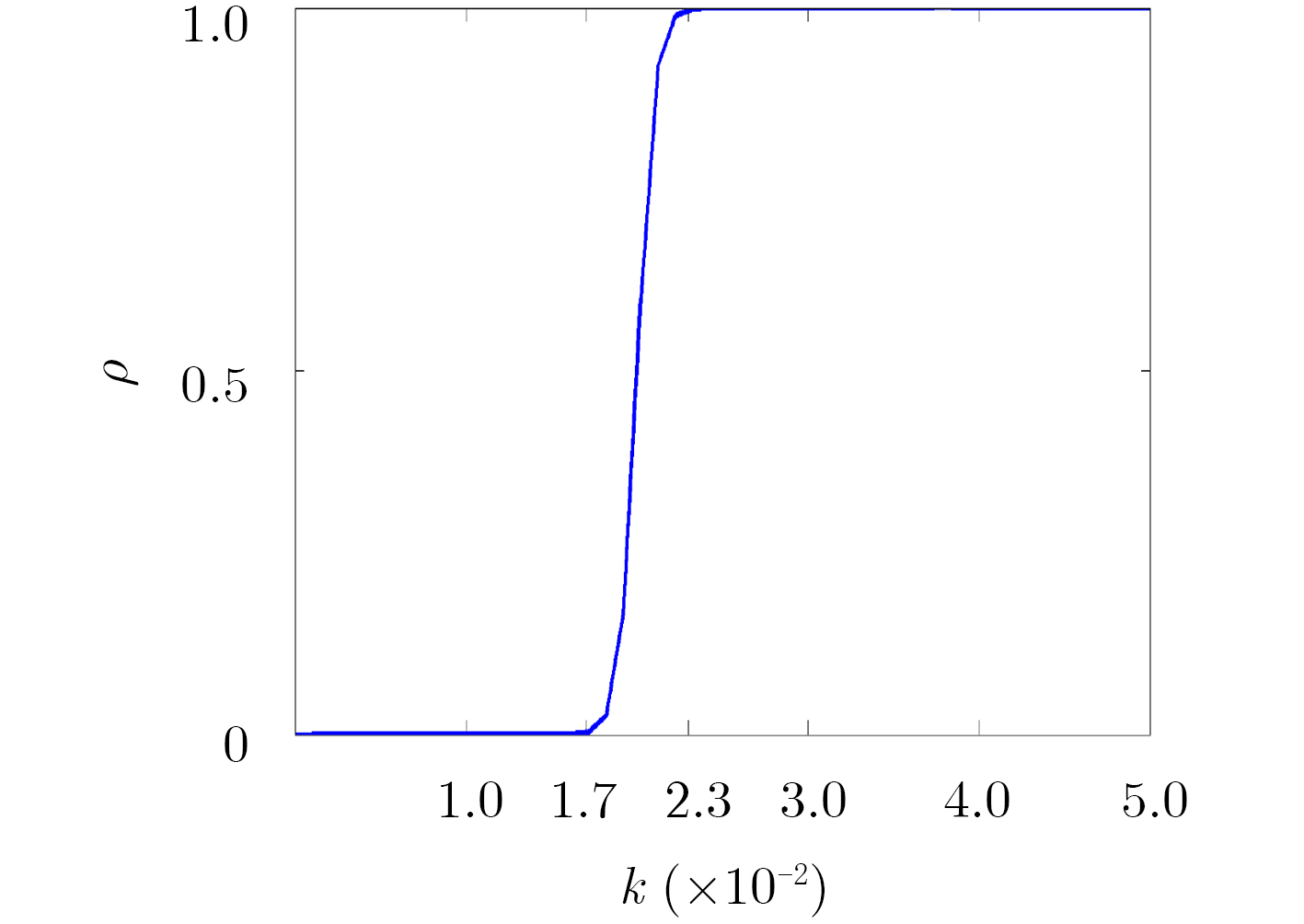
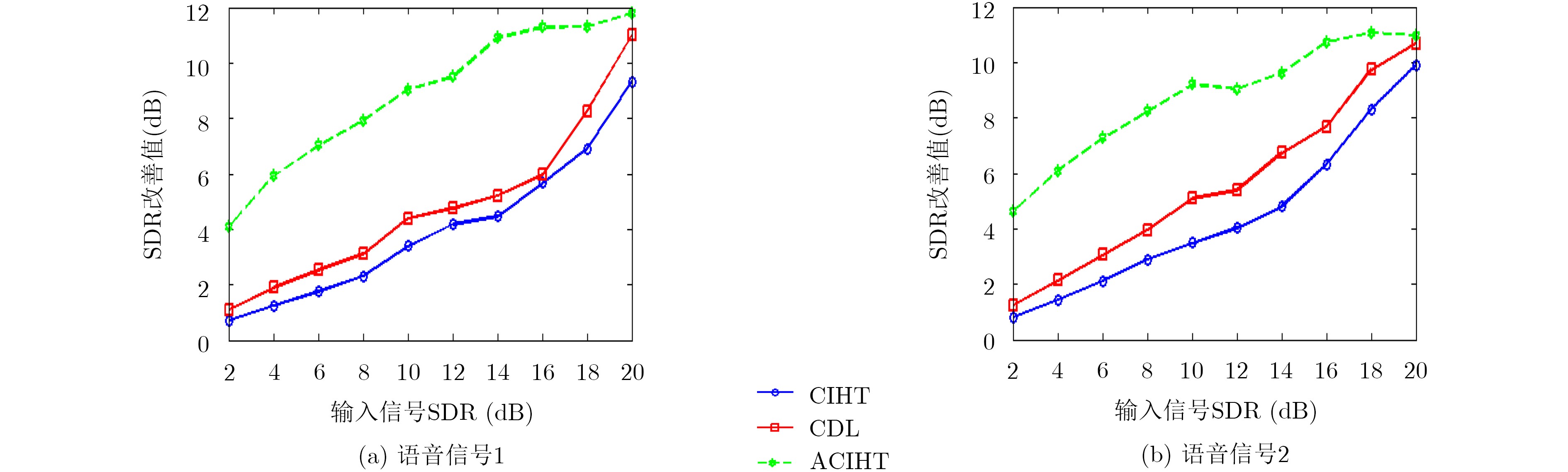
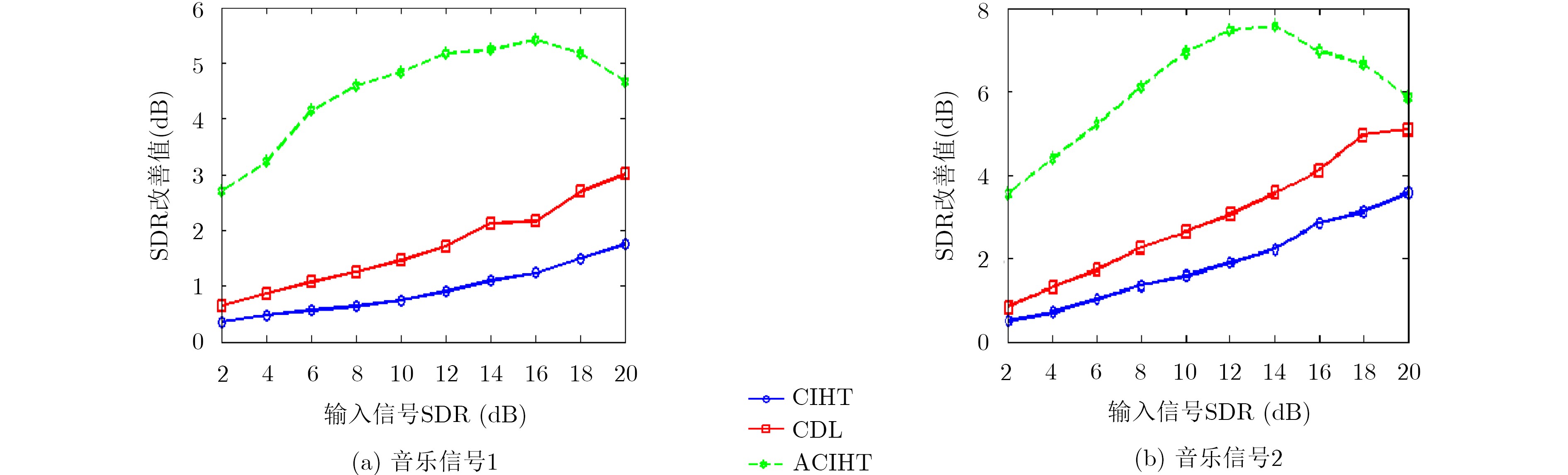
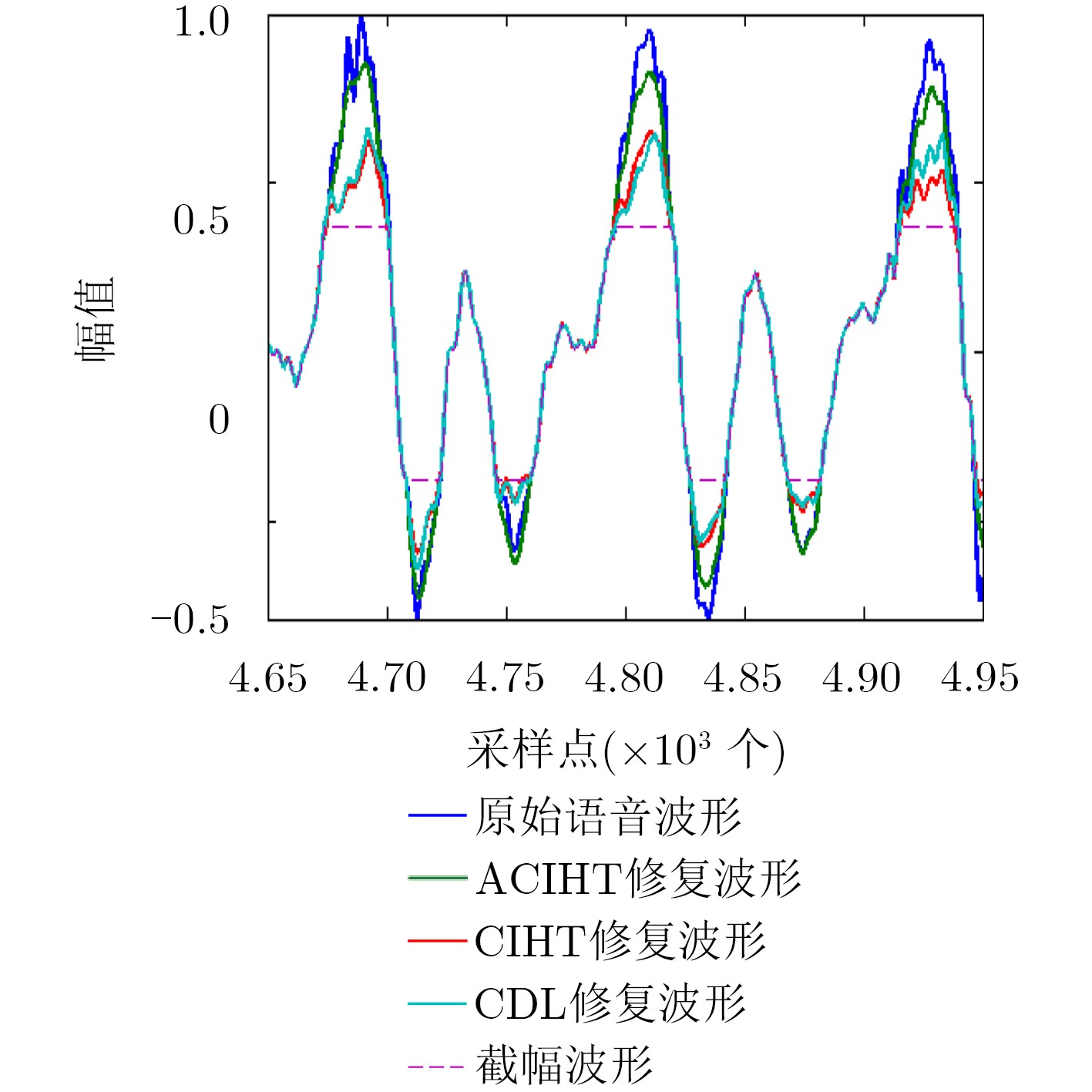
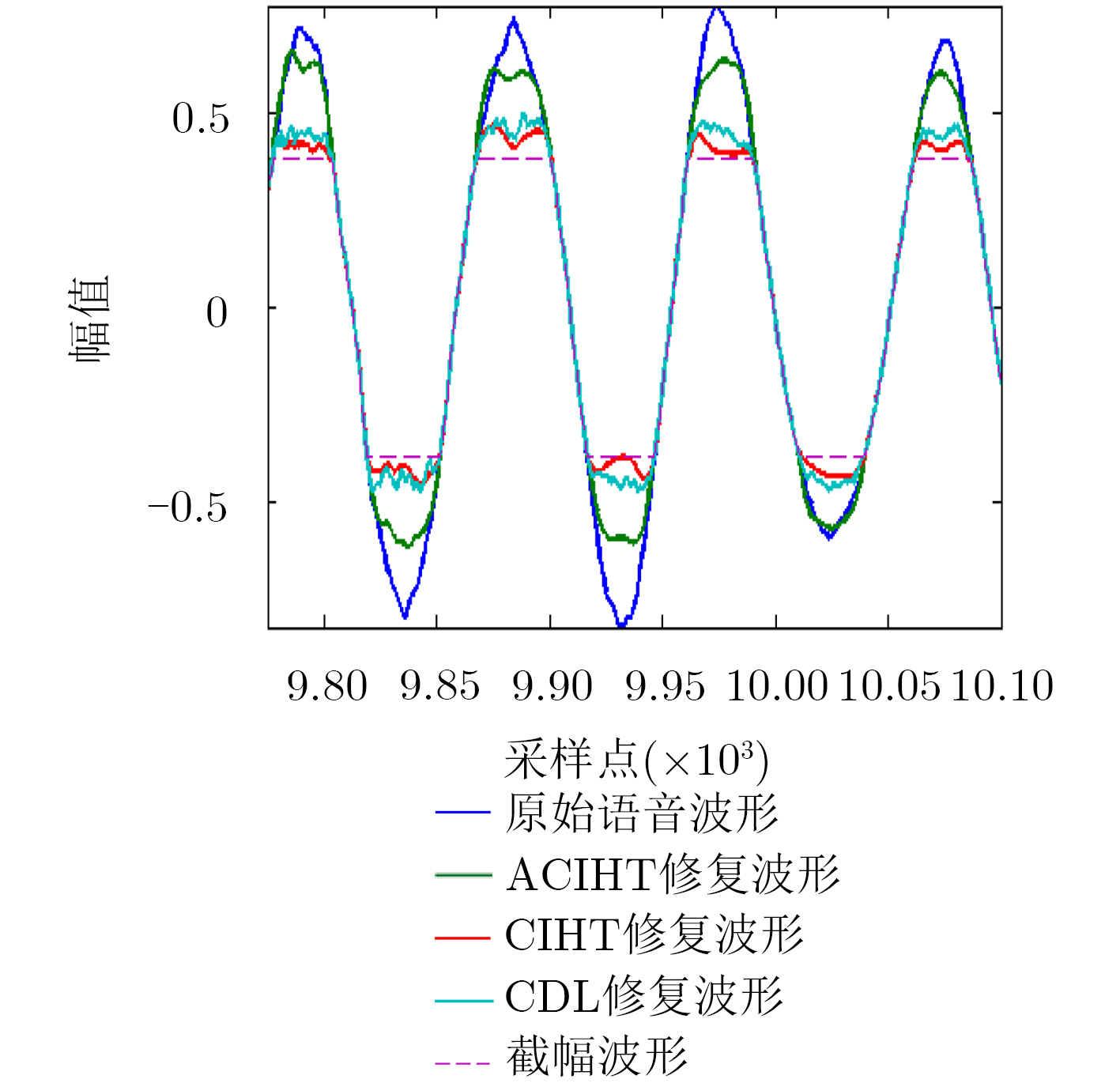
Audio clipping distortion can be solved by the Consistent Iterative Hard Thresholding (CIHT) algorithm, but the performance of restoration will decrease when the clipping degree is large, so, an algorithm based on adaptive threshold is proposed. The method estimates automatically the clipping degree, and the factor of the clipping degree is adjusted in the algorithm according to the degree of clipping. Compared with the CIHT algorithm and the Consistent Dictionary Learning (CDL) algorithm, the performance of restoration by the proposed algorithm is much better than the other two, especially in the case of severe clipping distortion. Compared with CDL, the computational complexity of the proposed algorithm is low like CIHT, compared with CDL, it has faster processing speed, which is beneficial to the practicality of the algorithm.

|
JANSSEN A, VELDHUIS R, and VRIES L. Adaptive interpolation of discrete-time signals that can be modeled as autoregressive processes[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1986, 34(2): 317–330 doi: 10.1109/TASSP.1986.1164824
|
|
ABEL J S and ABEL J S. Restoring a clipped signal[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Toronto, Canada, 1991, 3: 1745–1748.
|
|
SIMON J G, PATRICK J, and WILLIAM N W. Statistical model-based approaches to audio restoration and analysis[J]. Journal of New Music Research, 2001, 30(4): 323–338 doi: 10.1076/jnmr.30.4.323.7489
|
|
ADLER A, EMIYA V, and JAFARI M G. Audio Inpainting[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(3): 922–932 doi: 10.1109/TASL.2011.2168211
|
|
ADLER A, EMIYA V, and JAFARI M G. A constrained matching pursuit approach to audio declipping[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Prague, Czech Republic, 2011: 329–332.
|
|
DEFRAENE B, MANSOUR N, and HERTOGH S D. Declipping of audio signals using perceptual compressed sensing[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(12): 2627–2637 doi: 10.1109/TASL.2013.2281570
|
|
FOUCART S and NEEDHAM T. Sparse recovery from saturated measurements[J]. Information and Inference: A Journal of the IMA, 2017, 6(2): 196–212 doi: 10.1093/imaiai/iaw020
|
|
OZEROV A, BILEN C, and PEREZ P. Multichannel audio declipping[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Shanghai, China, 2016: 659–663.
|
|
KAI S, KOWALSKI M, and DORFLER M. Audio declipping with social sparsity[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Florence, Italy, 2014: 1577–1581.
|
|
KITIC S, JACQUES L, and MADHU N. Consistent iterative hard thresholding for signal declipping[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Vancouver, Canada, 2013: 5939–5943.
|
|
RENCKER L, BACH F, WANG Wenwu, et al. Consistent dictionary learning for signal declipping[C]. International Conference on Latent Variable Analysis and Signal Separation, Guildford, UK, 2018: 446–455.
|
|
LECUE G and FOUCART S. An IHT algorithm for sparse recovery from sub-exponential measurements[J]. IEEE Signal Processing Letters, 2017, 24(3): 1280–1283 doi: 10.1109/LSP.2017.2721500
|
|
HINES A, SKOGLUND J, and KOKARAM A. Robustness of speech quality metrics to background noise and network degradations: Comparing ViSQOL, PESQ and POLQA[C]. IEEE International Conference on Acoustics, Speech, and Signal Processing, Vancouver, Canada, 2013: 3697–3701.
|
|
何孝月. 基于EPESQ的VoIP语音质量评估的研究与实现[D]. [硕士论文], 中南大学, 2008.
HE Xiaoyue. Speech Quality Evaluation of VoIP Based on EPESQ[D]. [Master dissertation], Central South University, 2008.
|
Figures(9) / Tables(2)



 DownLoad:
DownLoad: