| Citation: | Wenjie LI, Fengpei GE, Pengyuan ZHANG, Yonghong YAN. Spatial Smoothing Regularization for Bi-direction Long Short-term Memory Model[J]. Journal of Electronics & Information Technology, 2019, 41(3): 544-550. doi: 10.11999/JEIT180314

|
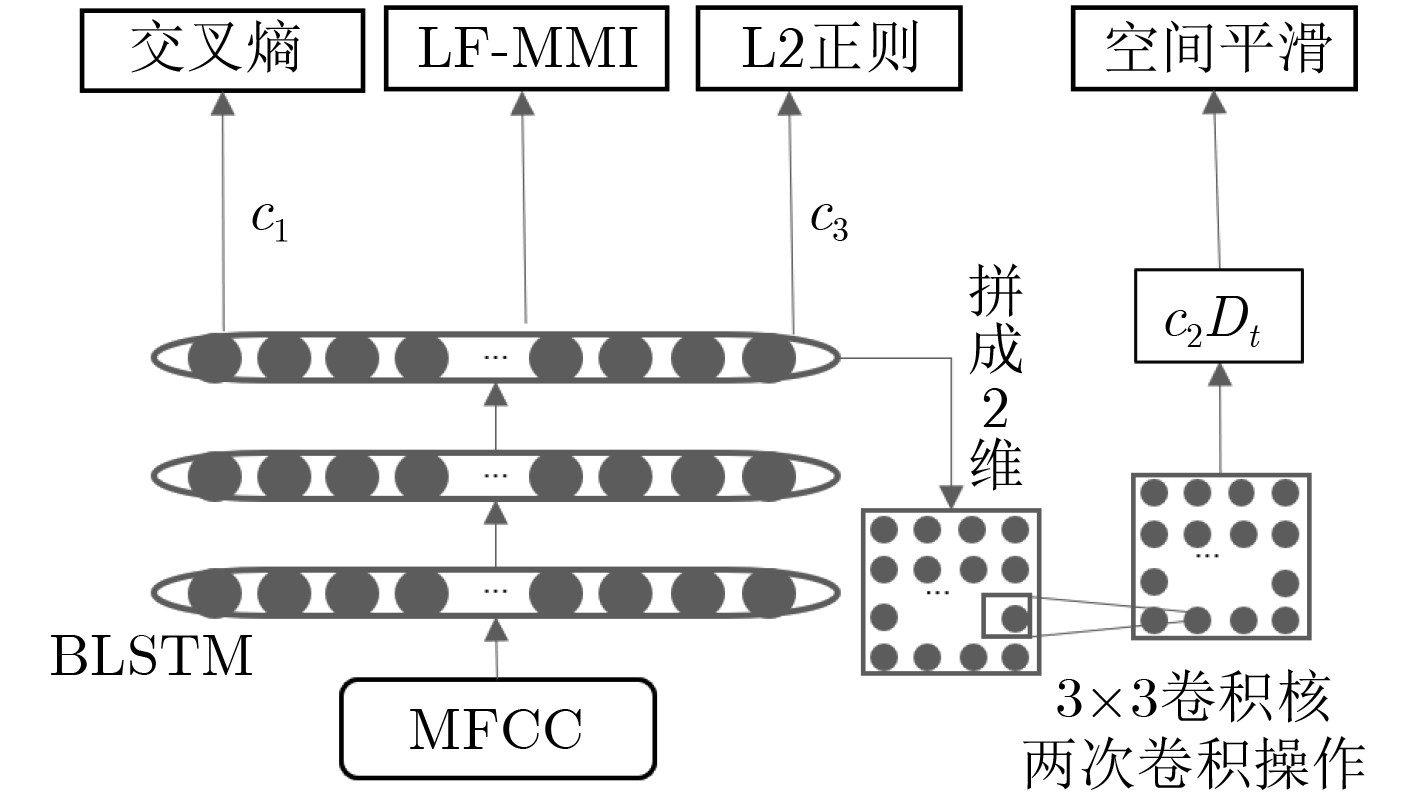
Bi-direction Long Short-Term Memory (BLSTM) model is widely used in large scale acoustic modeling recently. It is superior to many other neural networks on performance and stability. The reason may be that the BLSTM model gets complicated structure and computation with cell and gates, taking more context and time dependence into account during training. However, one of the biggest problem of BLSTM is overfitting, there are some common ways to get over it, for example, multitask learning, L2 model regularization. A method of spatial smoothing is proposed on BLSTM model to relieve the overfitting problem. First, the activations on the hidden layer are reorganized to a 2-D grid, then a filter transform is used to induce smoothness over the grid, finally adding the smooth information to the objective function, to train a BLSTM network. Experiment results show that the proposed spatial smoothing way achieves 4% relative reduction on Word Error Ratio (WER), when adding the L2 norm to model, which can lower the relative WER by 8.6% jointly.

|
LI X, and WU X. Constructing long short-term memory based deep recurrent neural networks for large vocabulary speech recognition[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 2015: 4520–4524. doi: 10.1109/ICASSP.2015.7178826.
|
|
CHEN K and HUO Q. Training deep bidirectional LSTM acoustic model for LVCSR by a context-sensitive-chunk BPTT approach[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)
|
|
AXELROD S, GOEL V, Gopinath R, et al. Discriminative estimation of subspace constrained gaussian mixture models for speech recognition[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(1): 172–189. doi: 10.1109/TASL.2006.872617
|
|
POVEY D, KANEVSKY D, KINGSBURY B, et al. Boosted MMI for model and feature-space discriminative training[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, USA, 2008: 4057–4060. doi: 10.1109/ICASSP.2008.4518545.
|
|
POVEY D and KINGSBURY B. Evaluation of proposed modifications to MPE for large scale discriminative training[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu, USA, 2007: 321–324. doi: 10.1109/ICASSP.2007.366914.
|
|
HUANG Z, SINISCALCHI S M, and LEE C H. Hierarchical Bayesian combination of plug-in maximum a posteriori decoders in deep neural networks-based speech recognition and speaker adaptation[J]. Pattern Recognition Letters, 2017, 98(15): 1–7. doi: 10.1016/j.patrec.2017.08.001
|
|
POVEY D. Discriminative training for large vocabulary speech recognition[D].[Ph.D. dissertation], University of Cambridge, 2003.
|
|
ZHOU P, JIANG H, DAI L R, et al. State-clustering based multiple deep neural networks modeling approach for speech recognition[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)
|
|
SRIVASTAVA N, HINTON G, KRIZHEYSKY A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929–1958.
|
|
GOODFELLOW I, BENGIO Y, and COURVILLE A, Deep Learning[M], Cambridge, MA: MIT Press, 2016: 228–230.
|
|
POVEY D, PEDDINTI V, GALVEZ D, et al. Purely sequence-trained neural networks for ASR based on lattice-free MMI[C]. International Speech Communication Association (INTERSPEECH), San Francisco, USA, 2016: 2751–2755. doi: 10.21437/Interspeech.2016-595.
|
|
SAHRAEIAN R, and VAN D. Cross-entropy training of DNN ensemble acoustic models for low-resource ASR[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018, 26(11): 1991–2001. doi: 10.1109/TASLP.2018.2851145
|
|
LIU P, LIU C, JIANG H, et al. A constrained line search optimization method for discriminative training of HMMs[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2008, 16(5): 900–909. doi: 10.1109/TASL.2008.925882
|
|
WU C, KARANASOU P, GALES M J, et al. Stimulated deep neural network for speech recognition[C]. International Speech Communication Association (INTERSPEECH), San Francisco, USA, 2016: 400–404. doi: 10.21437/Interspeech.2016-580.
|
|
Wu C, CALES M J F, RAGNI A, et al. Improving interpretability and regularization in deep learning[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP)
|
|
KO T, PEDDINTI V, POVEY D, et al. Audio augmentation for speech recognition[C]. International Speech Communication Association (INTERSPEECH), Dresden, Germany, 2015: 3586–3589. doi: 10.21437/Interspeech.2015-571.
|
|
LAURENT C, PEREYRA G, BRAKEL P, et al. Batch normalized recurrent neural networks[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 2016: 2657–2661. doi: 10.1109/ICASSP.2016.7472159.
|
Figures(3) / Tables(3)



 DownLoad:
DownLoad: