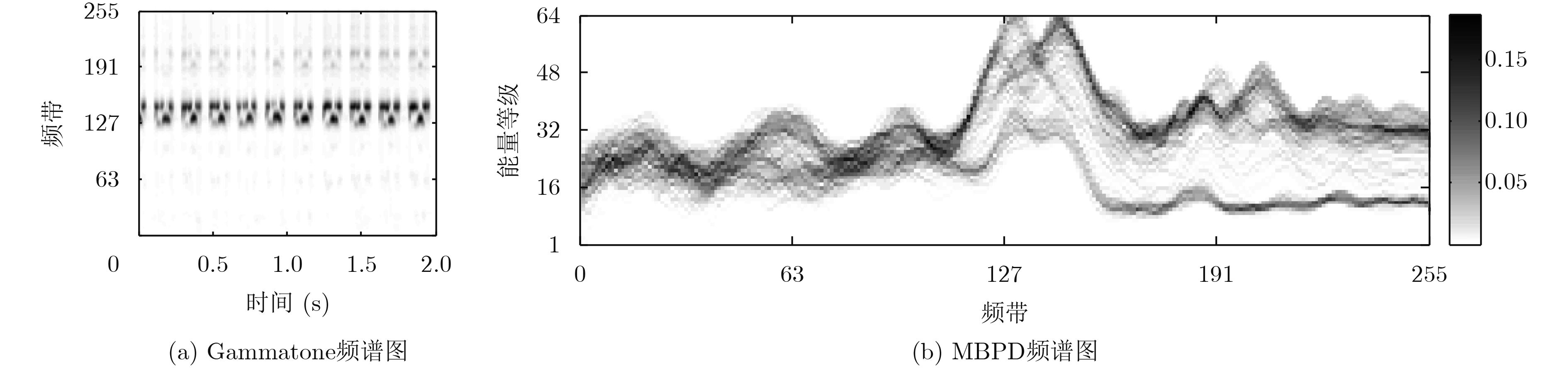
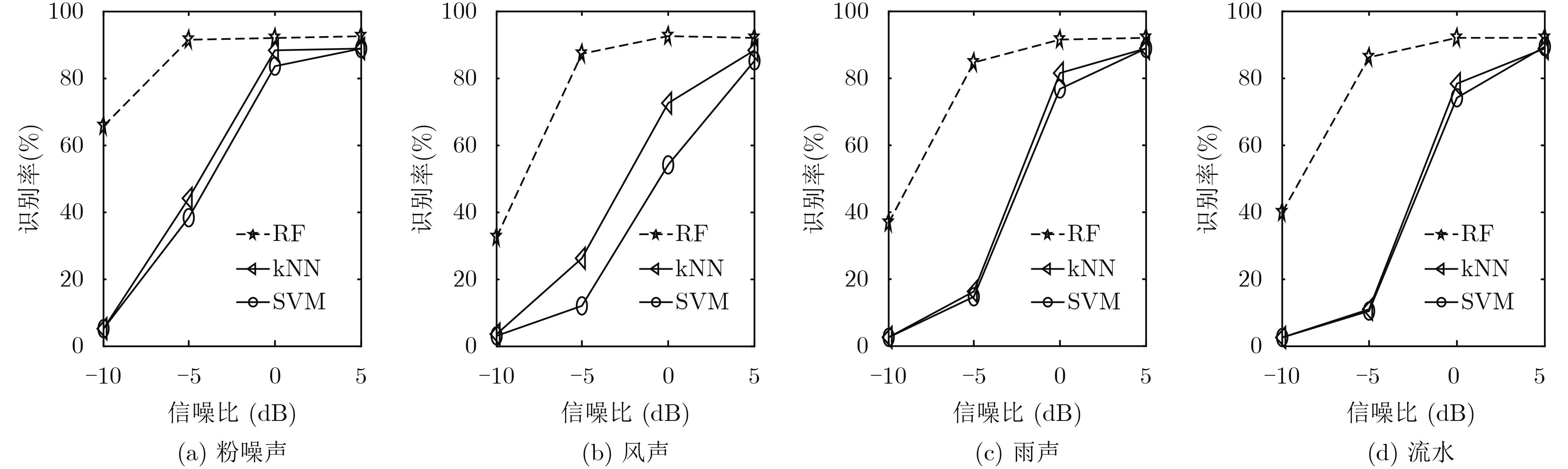
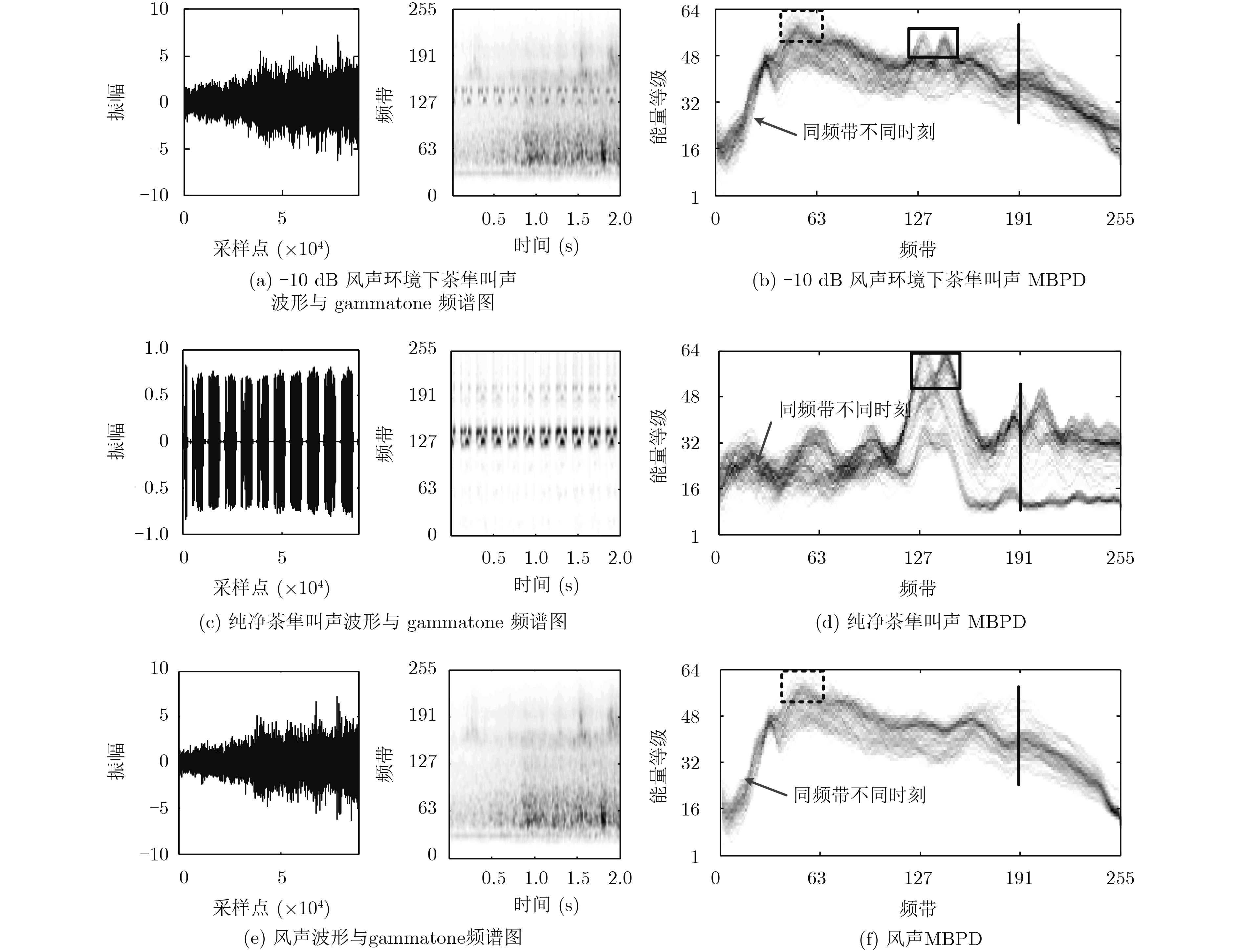
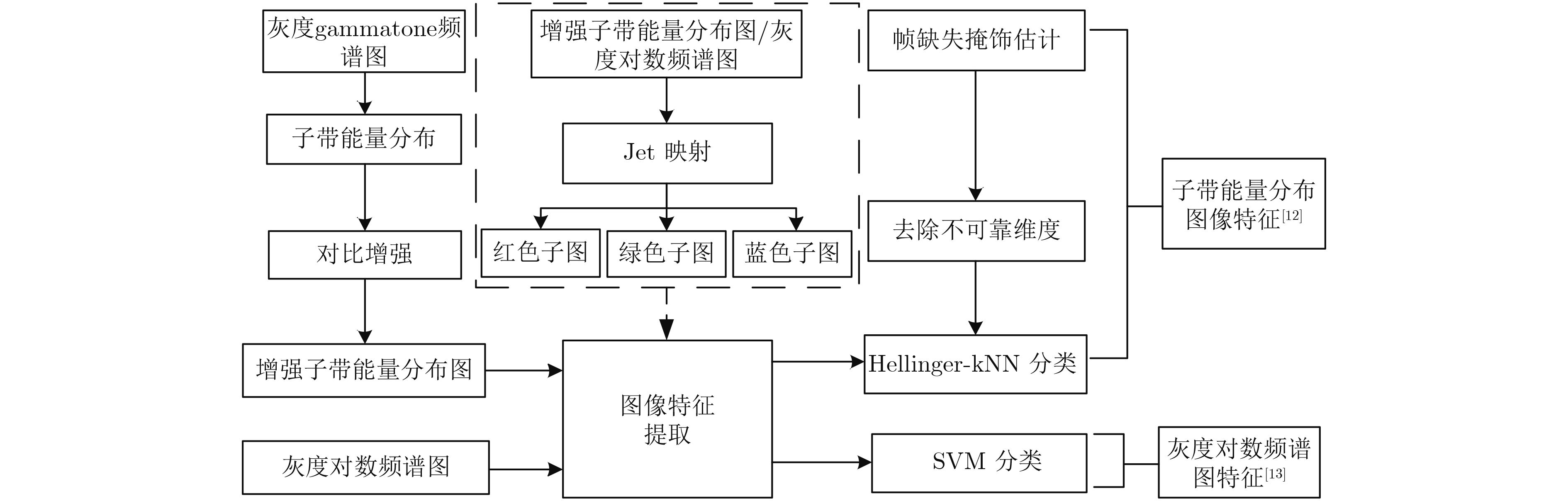
| Citation: | Ying LI, Lingfei WU. Detection of Sound Event under Low SNR Using Multi-band Power Distribution[J]. Journal of Electronics & Information Technology, 2018, 40(12): 2905-2912. doi: 10.11999/JEIT180180

|

|
米建伟, 方晓莉, 仇原鹰. 非平稳背景噪声下声音信号增强技术[J]. 仪器仪表学报, 2017, 38(1): 17–22 doi: 10.3969/j.issn.0254-3087.2017.01.003
MI Jianwei, FANG Xiaoli, and QIU Yuanying. Enhancement technology for the audio signal with nonstationary background noise[J]. Chinese Journal of Scientific Instrument, 2017, 38(1): 17–22 doi: 10.3969/j.issn.0254-3087.2017.01.003
|
|
汪家冬, 邹采荣, 蒋本聪, 等. 基于数字助听器声音场景分类的噪声抑制算法[J]. 数据采集与处理, 2017, 32(4): 825–830 doi: 10.16337/j.1004-9037.2017.04.021
WANG Jiadong, ZOU Cairong, JIANG Bencong, et al. Noise reduction algorithm based on acoustic scene classification in digital hearing aids[J]. Journal of Data Acquisition and Processing, 2017, 32(4): 825–830 doi: 10.16337/j.1004-9037.2017.04.021
|
|
FENG Zuren, ZHOU Qing, ZHANG Jun, et al. A target guided subband filter for acoustic event detection in noisy environments using wavelet packets[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2015, 23(2): 361–372 doi: 10.1109/TASLP.2014.2381871
|
|
GRZESZICK R, PLINGE A, and FINK G A. Bag-of-features methods for acoustic event detection and classification[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2017, 25(6): 1242–1252 doi: 10.1109/TASLP.2017.2690574
|
|
REN Jianfeng, JIANG Xudong, YUAN Junsong, et al. Sound-event classification using robust texture features for robot hearing[J]. IEEE Transactions on Multimedia, 2017, 19(3): 447–458 doi: 10.1109/TMM.2016.2618218
|
|
YE Jiaxing, KOBAYASHI T, and MURAKAWA M. Urban sound event classification based on local and global features aggregation[J]. Applied Acoustics, 2017, 117: 246–256 doi: 10.1016/j.apacoust.2016.08.002
|
|
CAKIR E, PARASCANDOLO G, HEITTOLA T, et al. Convolutional recurrent neural networks for polyphonic sound event detection[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2017, 25(6): 1291–1303 doi: 10.1109/TASLP.2017.2690575
|
|
SHARAN R V and MOIR T J. Robust acoustic event classification using deep neural networks[J]. Information Sciences, 2017, 396: 24–32 doi: 10.1016/j.ins.2017.02.013
|
|
OZER I, OZER Z, and FINDIK O. Noise robust sound event classification with convolutional neural network[J]. Neurocomputing, 2018, 272: 505–512 doi: 10.1016/j.neucom.2017.07.021
|
|
WANG Jiaching, LIN Changhong, and CHEN Bowei. Gabor-based nonuniform scale-frequency map for environmental sound classification in home automation[J]. IEEE Transactions on Automation Science and Engineering, 2014, 11(2): 607–613 doi: 10.1109/TASE.2013.2285131
|
|
SHARMA A and KAUL S. Two-stage supervised learning-based method to detect screams and cries in urban environments[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2016, 24(2): 290–299 doi: 10.1109/TASLP.2015.2506264
|
|
DENNIS J, TRAN H D, and CHNG E S. Image feature representation of the subband power distribution for robust sound event classification[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2013, 21(2): 367–377 doi: 10.1109/TASL.2012.2226160
|
|
DENNIS J, TRAN H D, and LI Haizhou. Spectrogram image feature for sound event classification in mismatched conditions[J]. IEEE Signal Processing Letters, 2011, 18(2): 130–133 doi: 10.1109/LSP.2010.2100380
|
|
SLANEY M. An efficient implementation of the Patterson-Holdsworth auditory filter bank[R]. Apple Computer Technical Report, 1993.
|
|
PAPAKOSTAS G A, KOULOURIOTIS D E, and KARAKASIS E G. Efficient 2-D DCT Computation from An Image Representation Point of View[M]. London, UK, Intch Open, 2009: 21–34.
|
|
LAY J A and GUAN Ling. Image retrieval based on energy histograms of the low frequency DCT coefficients[C]. IEEE International Conference on Acoustic, Speech and Signal Processing, Arizona, USA, 1999: 3009–3012.
|
|
BREIMAN L. Random forests[J]. Machine Learning, 2001, 45(1): 5–32 doi: 10.1023/A:1010933404324
|
|
Universitat Pompeu Fabra. Repository of sound under the creative commons license, Freesound. org[OL]. http://www.freesound.org, 2012.5.14.
|
|
IEEE Signal Processing Society, Tampere University of Technology, Queen Mary University of London, et al. IEEE DCASE 2016 Challenge[OL]. http://www.cs.tut.fi/sgn/arg/dcase2016/, 2016.
|
|
CHANG Chihchung and LIN Chihjen. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 1–27 doi: 10.1145/1961189.1961199
|
|
COVER T and HART P. Nearest neighbor pattern classification[J]. IEEE Transactions on Information Theory, 1967, 13(1): 21–27 doi: 10.1109/TIT.1967.1053964
|
|
ZHENG Fang, ZHANG Guoliang, and SONG Zhanjiang. Comparison of different implementations of MFCC[J]. Journal of Computer Science and Technology, 2001, 16(6): 582–589 doi: 10.1007/BF02943243
|
|
KIM C and STERN R M. Feature extraction for robust speech recognition based on maximizing the sharpness of the power distribution and on power flooring[C]. IEEE International Conference on Acoustic, Speech and Signal Processing, Dallas, USA, 2010: 4574–4577.
|
|
魏静明, 李应. 利用抗噪纹理特征的快速鸟鸣声识别[J]. 电子学报, 2015, 43(1): 185–190 doi: 10.3969/j.issn.0372-2112.2015.01.029
WEI Jingming and LI Ying. Rapid bird sound recognition using anti-noise texture features[J]. Acta Electronica Sinica, 2015, 43(1): 185–190 doi: 10.3969/j.issn.0372-2112.2015.01.029
|
|
KOBAYASHI T and YE J. Acoustic feature extraction by statictics based local binary pattern for environmental sound classification[C]. IEEE International Conference on Acoustic, Speech and Signal Processing, Florence, Italy, 2014: 3052–3056.
|
|
RAKOTOMAMONJY A and GASSO G. Histogram of gradients of time-frequency representations for audio scene classification[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2015, 23(1): 142–153 doi: 10.1109/TASLP.2014.2375575
|
Figures(7) / Tables(5)



 DownLoad:
DownLoad: