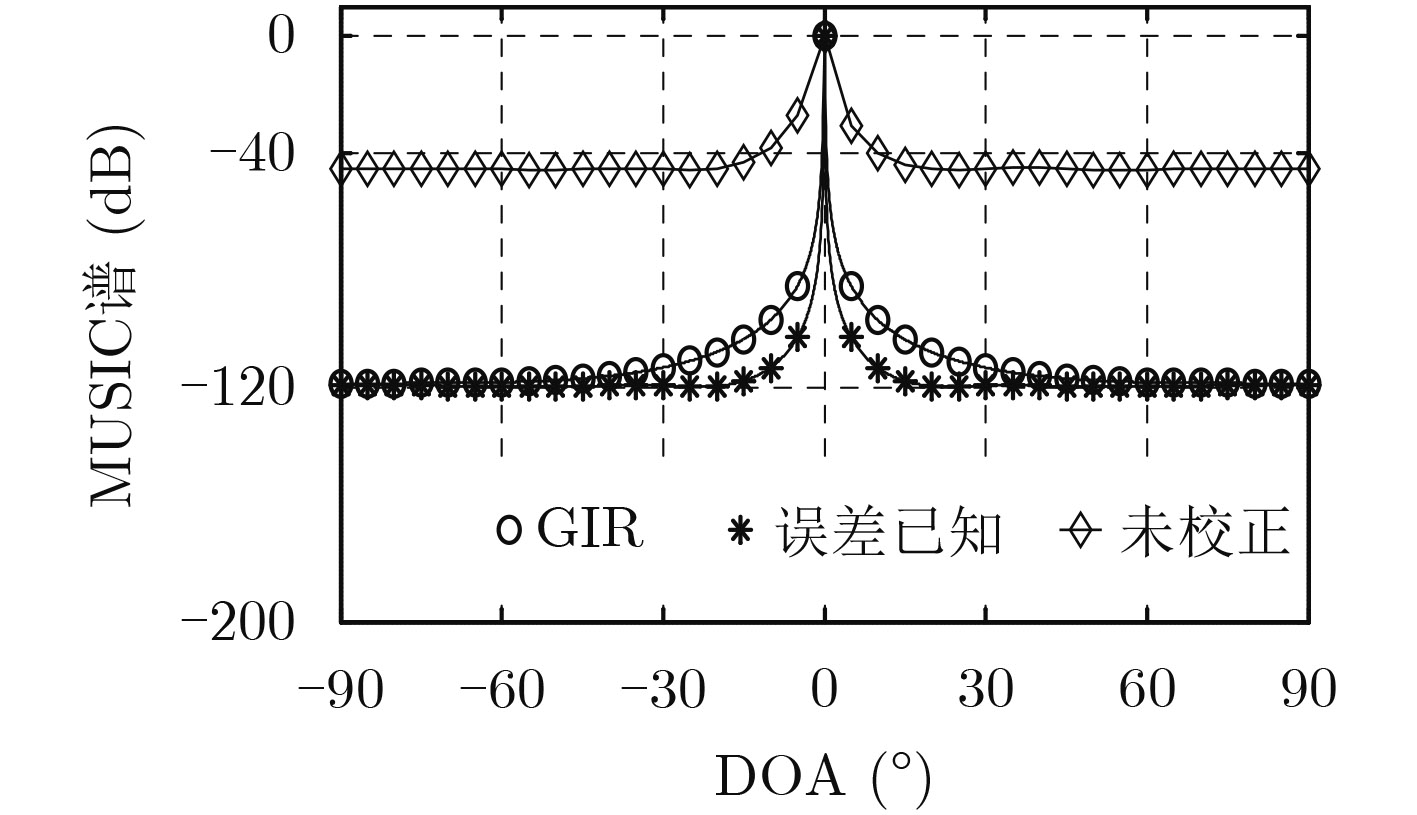
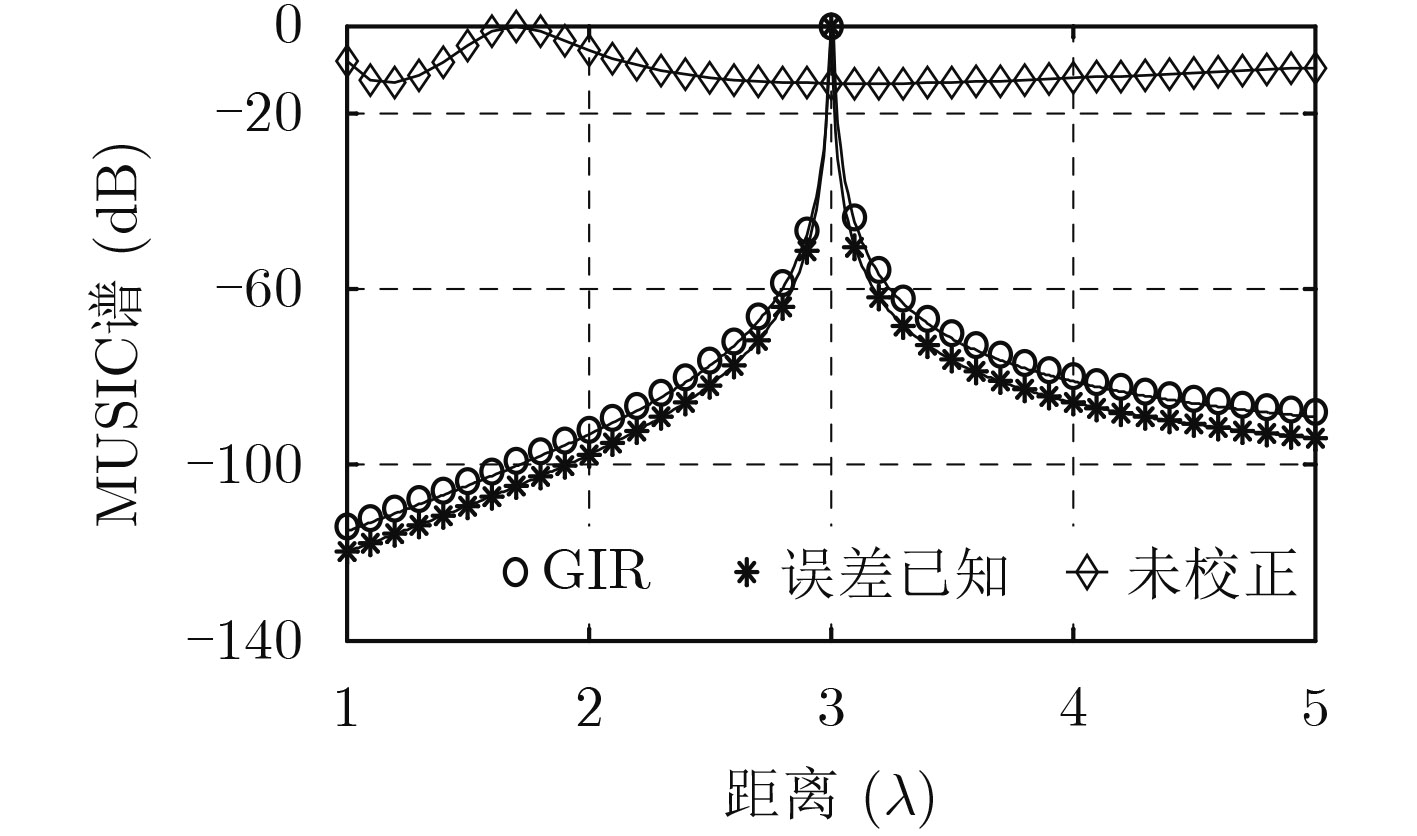
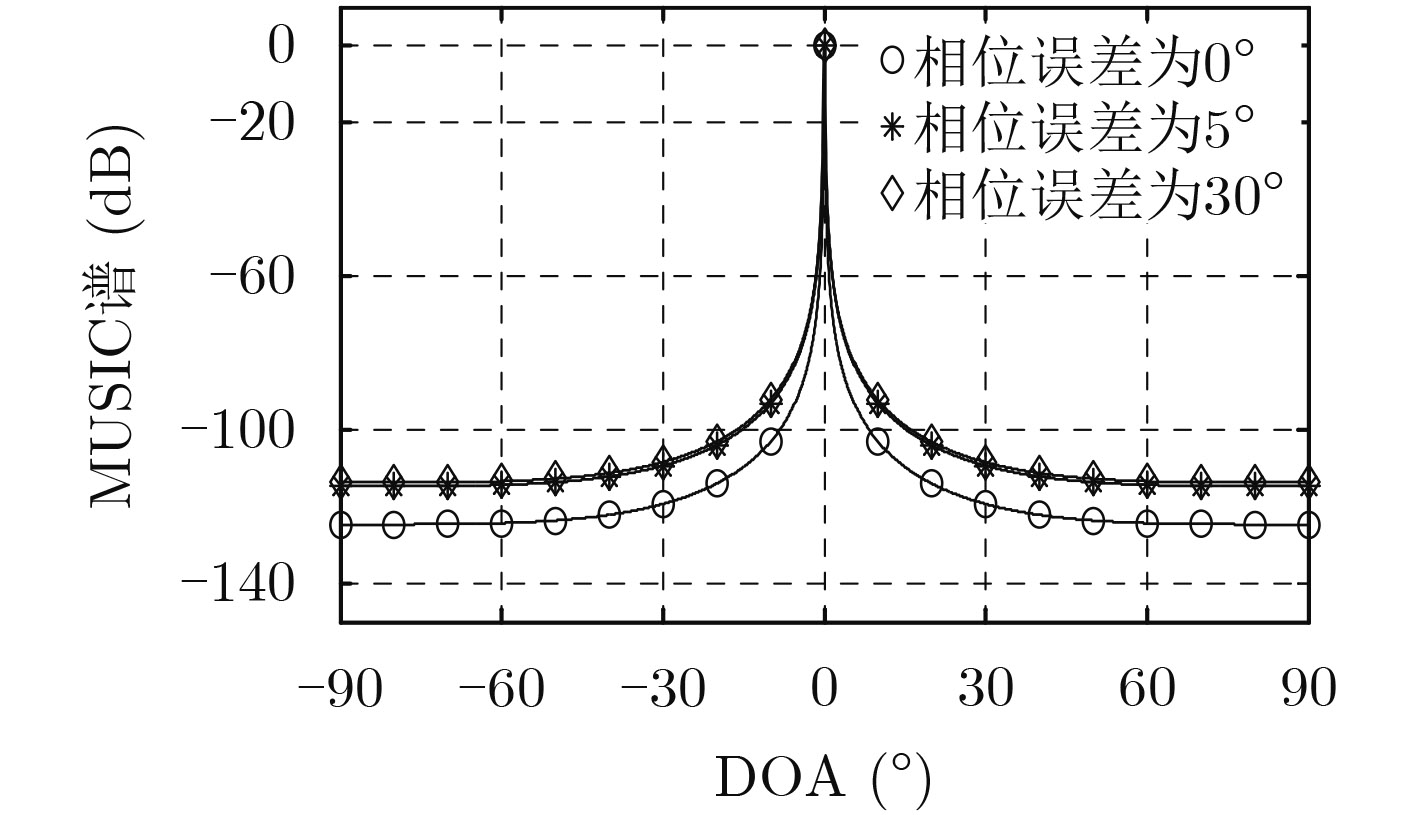
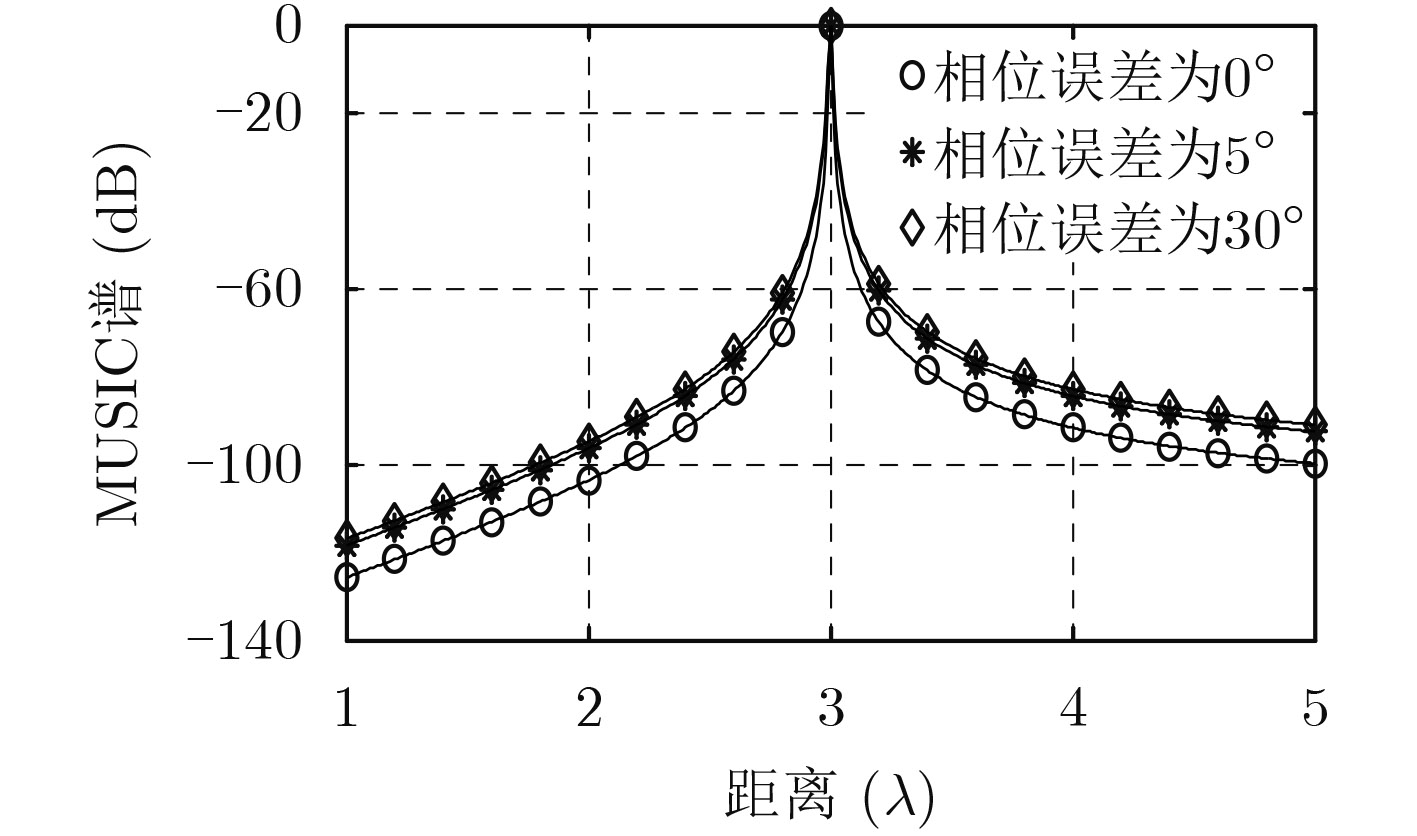
| Citation: | Mengyu NI, Hui CHEN, Song XIAO, Liuliu NI, Jiajia ZHANG. Gain and Phase Calibration Algorithm of Near-field Source Based on Instrumental Sensors[J]. Journal of Electronics & Information Technology, 2018, 40(10): 2415-2422. doi: 10.11999/JEIT180032

|

|
SWINDLEHURST A L and KAILATH T. Passive direction of arrival and range estimation for near-field sources[C]. IEEE Spectrum Estimation and Modeling Workshop, MN, USA, 1988: 123–128.
|
|
LI Jianzhong, WEI Gang, and MA Biyun. A simple way of near-field source localization with MUSIC[C]. IEEE International Conference on Computational Electromagnetics, Guangzhou, China, 2016: 330–332.
|
|
XIE Jian, TAO Haihong, RAO Xuan, et al. Localization of mixed far-field and near-field sources under unknown mutual coupling[J]. Digital Signal Processing, 2016, 50(C): 229–239 doi: 10.1016/j.dsp.2015.10.012
|
|
SINGH P R, WANG Y, and CHARGE P. Near field targets localization using bistatic MIMO system with symmetric arrays[C]. IEEE Signal Processing Conference, Kos, Greece, 2017: 2408–2412.
|
|
陈建峰, 张贤达, 吴云韬. 近场源距离、频率及到达角联合估计算法[J]. 电子学报, 2004, 32(5): 803–806 doi: 10.3321/j.issn:0372-2112.2004.05.023
CHEN Jianfeng, ZHANG Xianda, and WU Yuntao. An algorithm for jointly estimating range, DOA and frequency of near field source[J]. Acta Electronica Sinica, 2004, 32(5): 803–806 doi: 10.3321/j.issn:0372-2112.2004.05.023
|
|
黄家才, 石要武, 陶建武. 一种新的近场源距离及到达角联合估计算法[J]. 电子与信息学报, 2007, 29(11): 2738–2742 doi: 10.3724/SP.J.1146.2006.00633
HUANG Jiacai, SHI Yaowu, and TAO Jianwu. A new method for range and DOA estimation of near-field sources[J]. Journal of Electronics&Information Technology, 2007, 29(11): 2738–2742 doi: 10.3724/SP.J.1146.2006.00633
|
|
CHEN Xin, LIN Zhen, and WEI Xizhang. Unambiguous parameter estimation of multiple near-field sources via totating uniform circular array[J]. IEEE Antennas and Wireless Propagation Letters, 2017, 16: 872–875 doi: 10.1109/LAWP.2016.2613084
|
|
KIM Jungtai, YANG Hyunjong, JUNG Byungwook, et al. Blind calibration for a linear array with gain and phase error using independent component analysis[J]. IEEE Antennas and Wireless Letters, 2010, 9(10): 1259–1262 doi: 10.1109/LAWP.2010.2104132
|
|
LIU Hongqing, ZHAO Luming, LI Yong, et al. A sparse-based approach for DOA estimation and array calibration in uniform linear array[J]. IEEE Sensors Journal, 2016, 16(15): 6018–6027 doi: 10.1109/JSEN.2016.2577712
|
|
LI Youming and ER M H. Theoretical analyses of gain and phase error calibration with optimal implementation for linear equispaced array[J]. IEEE Transactions on Signal Processing, 2006, 54(2): 712–723 doi: 10.1109/TSP.2005.861892
|
|
程丰, 龚子平, 张驰, 等. 一种基于旋转测量的阵列幅相误差校正新方法[J]. 电子与信息学报, 2017, 39(8): 1899–1905 doi: 10.11999/JEIT161058
CHENG Feng, GONG Ziping, ZHANG Chi, et al. A new rotation measurement-based method for array gain-phase errors calibration[J]. Journal of Electronics&Information Technology, 2017, 39(8): 1899–1905 doi: 10.11999/JEIT161058
|
|
王布宏, 王永良, 陈辉, 等. 方位依赖阵元幅相误差校正的辅助阵元法[J]. 中国科学E辑: 信息科学, 2004, 34(8): 906–918 doi: 10.3321/j.issn:1006-9275.2004.08.006
WANG Buhong, WANG Yongliang, CHEN Hui, et al. Array calibration of angularly dependent gain and phase uncertainties with carry-on instrumental sensors[J]. Science in China Ser. E Information Sciences, 2004, 34(8): 906–918 doi: 10.3321/j.issn:1006-9275.2004.08.006
|
|
芦迅, 甄佳奇. 基于幅相误差阵列的远近场混合信号超分辨测向方法[J]. 电波科学学报, 2017, 32(2): 227–236 doi: 10.13443/j.cjors.2016120401
LU Xun and ZHEN Jiaqi. Super-resolution direction finding method for mixed far-field and near-field signals based on gain-phase error array[J]. Chinese Journal of Radio Science, 2017, 32(2): 227–236 doi: 10.13443/j.cjors.2016120401
|
|
DAI Zheng, SU Weimin, GU Hong, et al. Sensor gain-phase errors estimation using disjoint sources in unknown directions[J]. IEEE Sensors Journal, 2016, 16(10): 3724–3730 doi: 10.1109/JSEN.2016.2531282
|
|
付永庆, 郑莉, 邵学辉. 一种监听键盘录入信息的新方法[J]. 哈尔滨工程大学学报, 2008, 29(2): 175–178 doi: 10.3969/j.issn.1006-7043.2008.02.014
FU Yongqing, ZHENG Li, and SHAO Xuehui. Intercepting messages using the sounds of keystrokes[J]. Journal of Harbin Engineering University, 2008, 29(2): 175–178 doi: 10.3969/j.issn.1006-7043.2008.02.014
|

Figures(11) / Tables(1)



 DownLoad:
DownLoad: