| Citation: | Bo HU, Qiyao WANG, Hui FENG, Lingbing LUO. Adaptive Sensor Scheduling Algorithm for Target Tracking in Wireless Sensor Networks[J]. Journal of Electronics & Information Technology, 2018, 40(9): 2033-2041. doi: 10.11999/JEIT171154

|

|
ALCALA J M, URENA J U, HERNANDEZ A, et al. Sustainable homecare monitoring system by sensing electricity data[J]. IEEE Sensors Journal, 2017, 17(23): 7741–7749 doi: 10.1109/JSEN.2017.2713645
|
|
MARTELLI T, BONGIOANNI C, COLONE F, et al. Security enhancement in small private airports through active and passive radar sensors[C]. 17th IEEE International Conference on Radar Symposium (IRS), Krakow, Poland, 2016: 1–5.
|
|
SHI W Y and CHIAO J C. Neural network based real-time heart sound monitor using a wireless wearable wrist sensor[C]. IEEE Conference on Circuits and Systems Conference (DCAS), Arlington, USA, 2016: 1–4.
|
|
ANGLEY D, SUVOROVA S, RISTIC B, et al. Sensor scheduling for target tracking in large multistatic sonobuoy fields[C]. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Arlington, USA, 2017: 3146–3150.
|
|
SONG R, WEI Q, and XIAO W. ADP-based optimal sensor scheduling for target tracking in energy harvesting wireless sensor networks[J]. Neural Computing and Applications, 2016, 27(6): 1543–1551 doi: 10.1007/s00521-015-1954-4
|
|
YANG X, ZHANG W A, CHEN M Z Q, et al. Hybrid sequential fusion estimation for asynchronous sensor network-based target tracking[J]. IEEE Transactions on Control Systems Technology, 2017, 25(2): 669–676 doi: 10.1109/TCST.2016.2558632
|
|
唐显锭, 冯辉, 杨涛, 等. 无线传感器网络中用于目标跟踪的节点规划算法[J]. 太赫兹科学与电子信息学报, 2014, 12(3): 355–361 doi: 10.11805/TKYDA201403.0355
TANG Xianding, FENG Hui, YANG Tao, et al. Sensor scheduling for target tracking in wireless sensor networks[J]. Journal of Terahertz Science and Electronic Information Technology, 2014, 12(3): 355–361 doi: 10.11805/TKYDA201403.0355
|
|
ZHANG H, AYOUB R, and SUNDARAM S. Sensor selection for Kalman filtering of linear dynamical systems: Complexity, limitations and greedy algorithms[J]. Automatica, 2017, 78: 202–210 doi: 10.1016/j.automatica.2016.12.025
|
|
冉晓旻, 方德亮. 基于势博弈的分布式目标跟踪传感器分配算法[J]. 电子与信息学报, 2017, 39(11): 2748–2754 doi: 10.11999/JEIT170229
RAN Xiaomin and FANG Deliang. Distributed sensor allocation algorithm for target tracking based on potential game[J]. Journal of Electronics&Information Technology, 2017, 39(11): 2748–2754 doi: 10.11999/JEIT170229
|
|
SINGH P, CHEN M, CARLONE L, et al. Supermodular mean squared error minimization for sensor scheduling in optimal Kalman filtering[C]. IEEE Conference on American Control Conference (ACC), Seattle, USA, 2017: 5787–5794.
|
|
ASGHAR A B, JAWAID S T, and SMITH S L. A complete greedy algorithm for infinite-horizon sensor scheduling[J]. Automatica, 2017, 81: 335–341 doi: 10.1016/j.automatica.2017.04.018
|
|
SPAAN M T J. Partially Observable Markov Decision Processes[M]. Berlin Heidelberg: Springer, 2012: 387–414.
|
|
ZOIS D S, LEVORATO M, and MITRA U. Active classification for POMDPs: A Kalman-like state estimator[J]. IEEE Transactions on Signal Processing, 2014, 62(23): 6209–6224 doi: 10.1109/TSP.2014.2362098
|
|
ZOIS D S and MITRA U. Active state tracking with sensing costs: Analysis of two-states and methods for n-states[J]. IEEE Transactions on Signal Processing, 2017, 65(11): 2828–2843 doi: 10.1109/TSP.2017.2664049
|
|
SHANI G, PINEAU J, and KAPLOW R. A survey of point-based POMDP solvers[J]. Autonomous Agents and Multi-Agent Systems, 2013, 27(1): 1–51 doi: 10.1007/s10458-012-9200-2
|
|
LITTMAN M L, CASSANDRA A R, and KAELBLING L P. Learning policies for partially observable environments: Scaling up[C]. Proceedings of the 12th International Conference on Machine Learning, Tahoe City, USA, 1995: 362–370.
|
|
RUSSELL S. Artificial Intelligence: A Modern Approach. Making Complex Decisions (Ch-17)[M]. Englewood Cliffs: Prentice-Hall, 2004: 645–692.
|
|
HE Y and CHONG K P. Sensor scheduling for target tracking in sensor networks[C]. 43rd IEEE Conference on Decision and Control(CDC), Nassau, Bahamas, 2004: 743–748.
|
|
CHONG E K P, KREUCHER C M, and HERO III A O. POMDP Approximation Using Simulation and Heuristics[M]. Boston, MA: Springer, 2008: 95–119.
|
|
LI Y, KRAKOW L W, CHONG E K P, et al. Dynamic sensor management for multisensor multitarget tracking[C]. IEEE 40th Annual Conference on Information Sciences and Systems, Princeton, USA, 2006: 1397–1402.
|
|
LI Y, KRAKOW L W, CHONG E K P, et al. Approximate stochastic dynamic programming for sensor scheduling to track multiple targets[J]. Digital Signal Processing, 2009, 19(6): 978–989 doi: 10.1016/j.dsp.2007.05.004
|
|
BAR-SHALOM Y, LI X R, and KIRUBARAJAN T. Estimation with Applications to Tracking and Navigation: Theory Algorithms and Software[M]. New York: John Wiley & Sons, 2004: 199–266.
|
|
ALIPPI C and VANINI G. A RSSI-based and calibrated centralized localization technique for Wireless Sensor Networks[C]. Fourth Annual IEEE International Conference on Pervasive Computing and Communications Workshops, Pisa, Italy, 2006: 301–305.
|
|
NIU R and VARSHNEY P K. Target location estimation in sensor networks with quantized data[J]. IEEE Transactions on Signal Processing, 2006, 54(12): 4519–4528 doi: 10.1109/TSP.2006.882082
|
|
ARULAMPALAM M S, MASKELL S, GORDON N, et al. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking[J]. IEEE Transactions on Signal Processing, 2002, 50(2): 174–188 doi: 10.1109/78.978374
|
|
RUSSELL S. Artificial Intelligence: A Modern Approach. Probabilistic Reasoning Over Time (Ch-15)[M]. Englewood Cliffs: Prentice-Hall, 2004: 566–609.
|
|
HE Y and CHONG E K P. Sensor scheduling for target tracking: A Monte Carlo sampling approach[J]. Digital Signal Processing, 2006, 16(5): 533–545 doi: 10.1016/j.dsp.2005.02.005
|
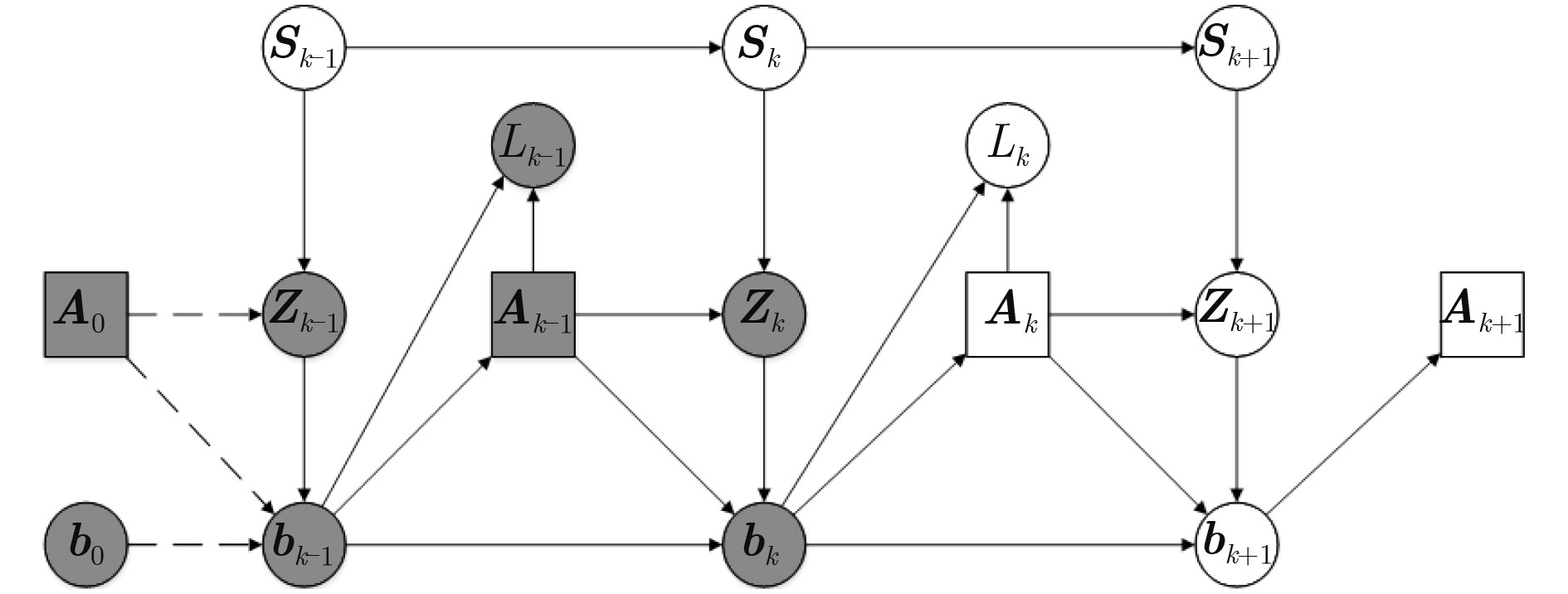
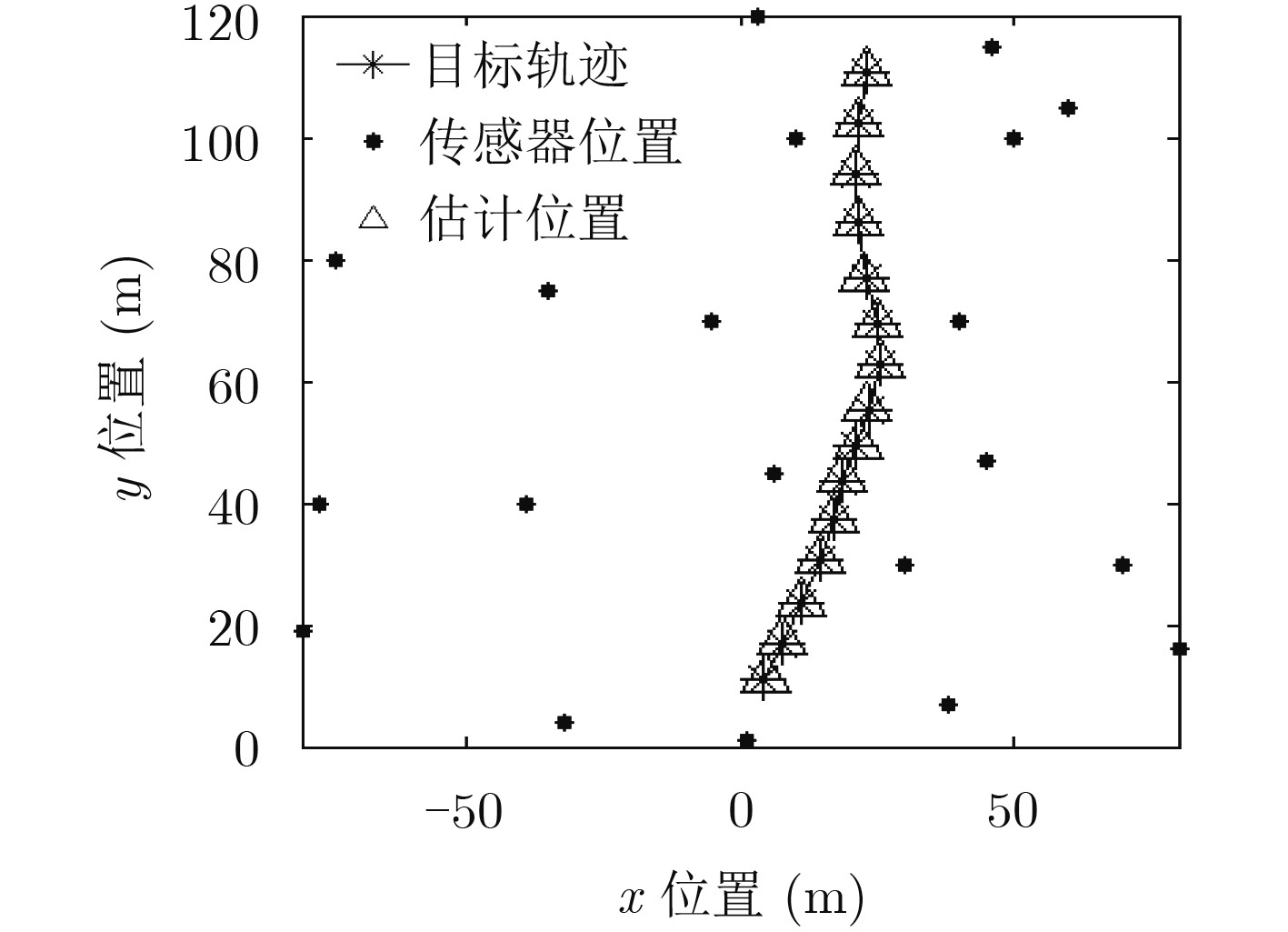
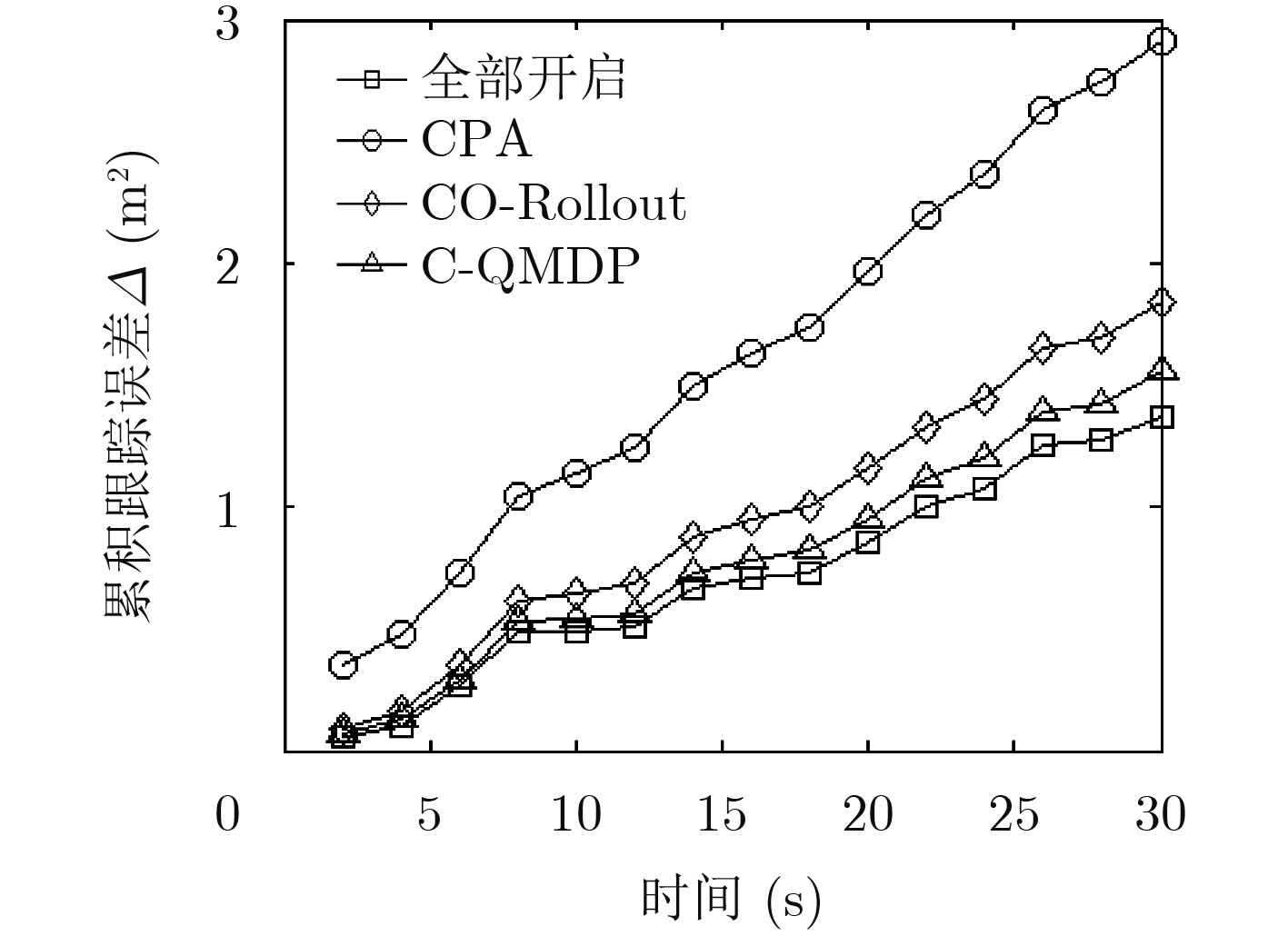
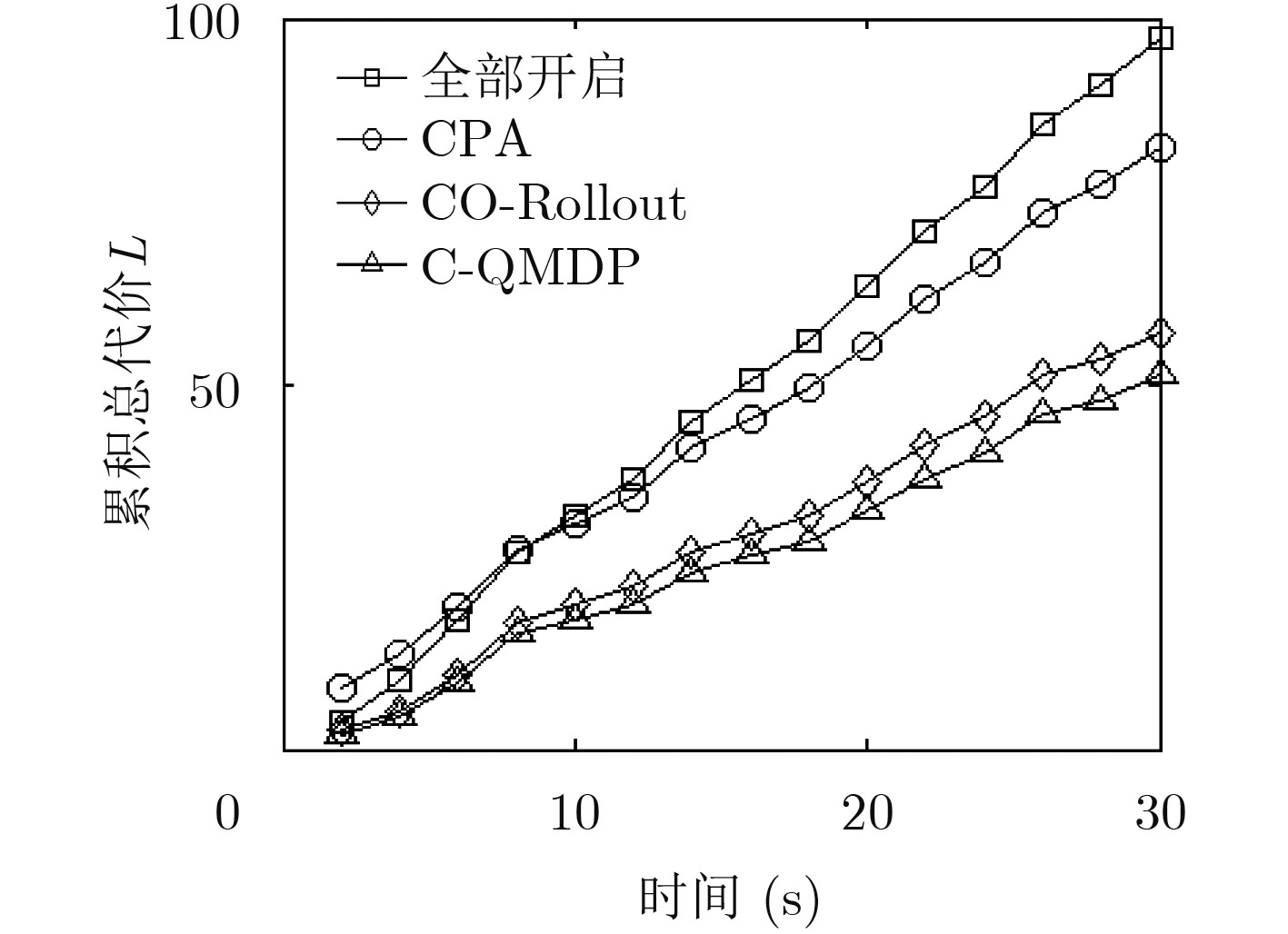
Figures(5) / Tables(2)



 DownLoad:
DownLoad: