

Millimeter-Wave Air-to-Ground Channel Prediction Assisted by Visual Information of the Propagation Environment
-
摘要: 空对地信道的精准预测是实现无人机通信链路自适应传输与高效资源调度的关键。然而,现有方法往往面临环境表征冗余、物理可解释性不足等问题。为此,本文提出一种无人机传播环境视觉信息辅助的毫米波空对地信道预测。首先,构建时空严格对齐的通信感知一体化数据集,实现视觉感知数据与信道参数的联合获取;其次,从RGB图像与深度图像中提取建筑物坐标、高度、体积和收发机距离等低维空间特征,以刻画传播环境的关键几何结构,并验证了空间特征与信道之间存在显著关联;最后,设计了Transformer与多层感知机融合网络,学习空间特征与路径损耗、接收功率及均方根时延扩展之间的非线性映射关系。实验结果表明,所提方法在三类信道参数预测任务上均优于对比模型,具有较高的预测精度和鲁棒性。Abstract:
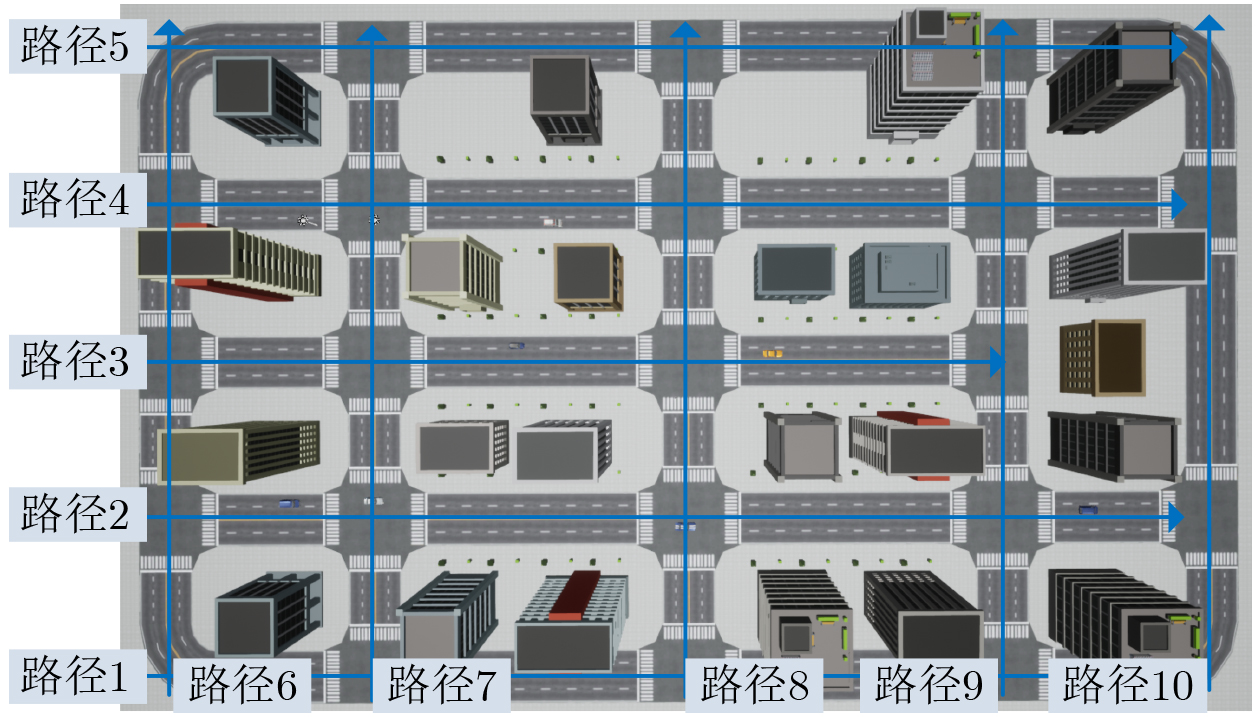
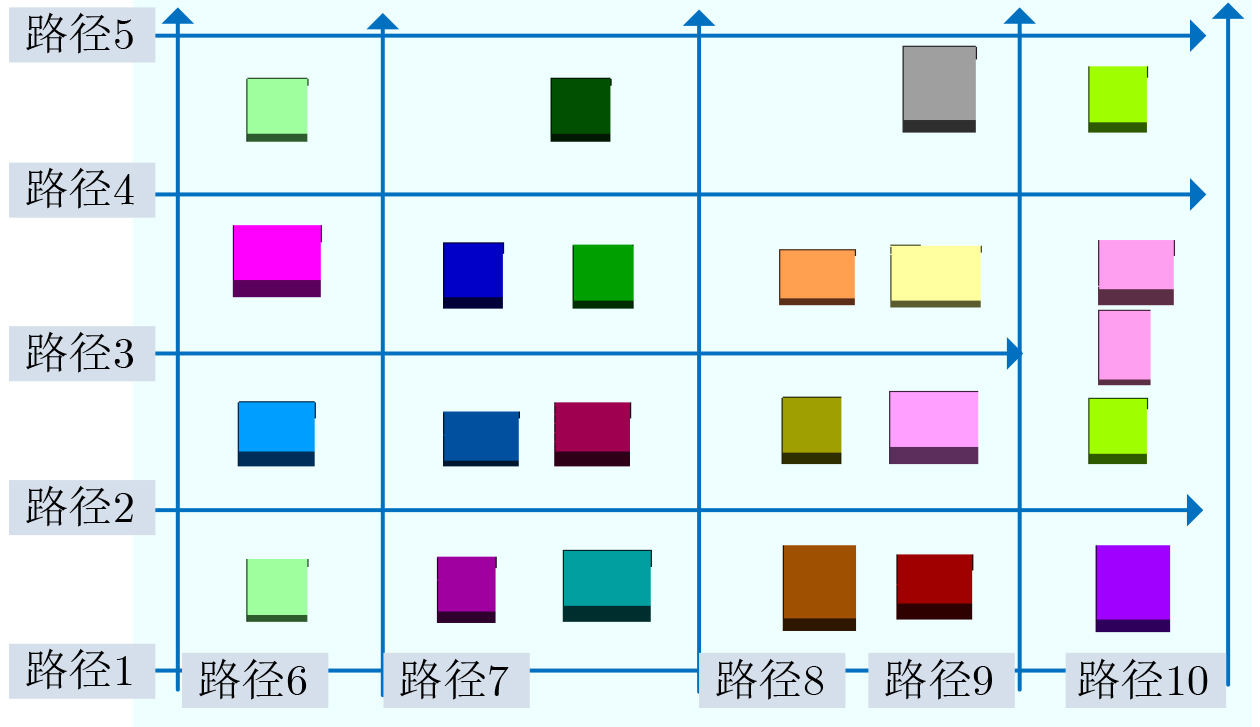
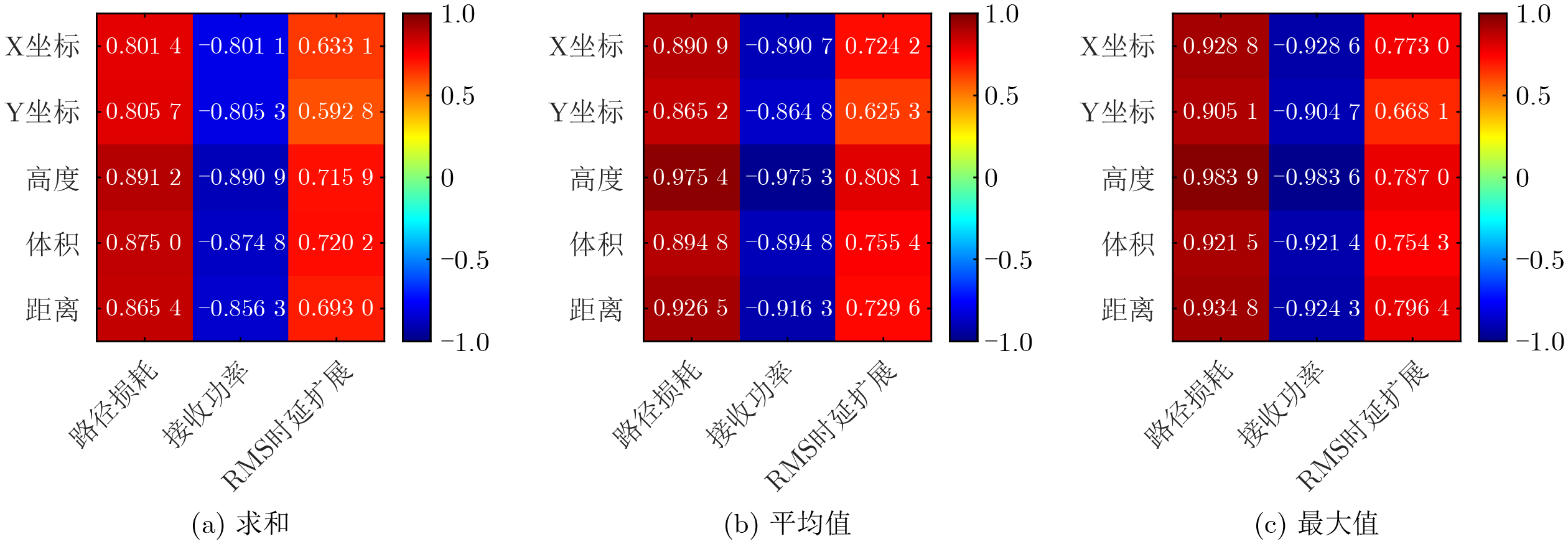
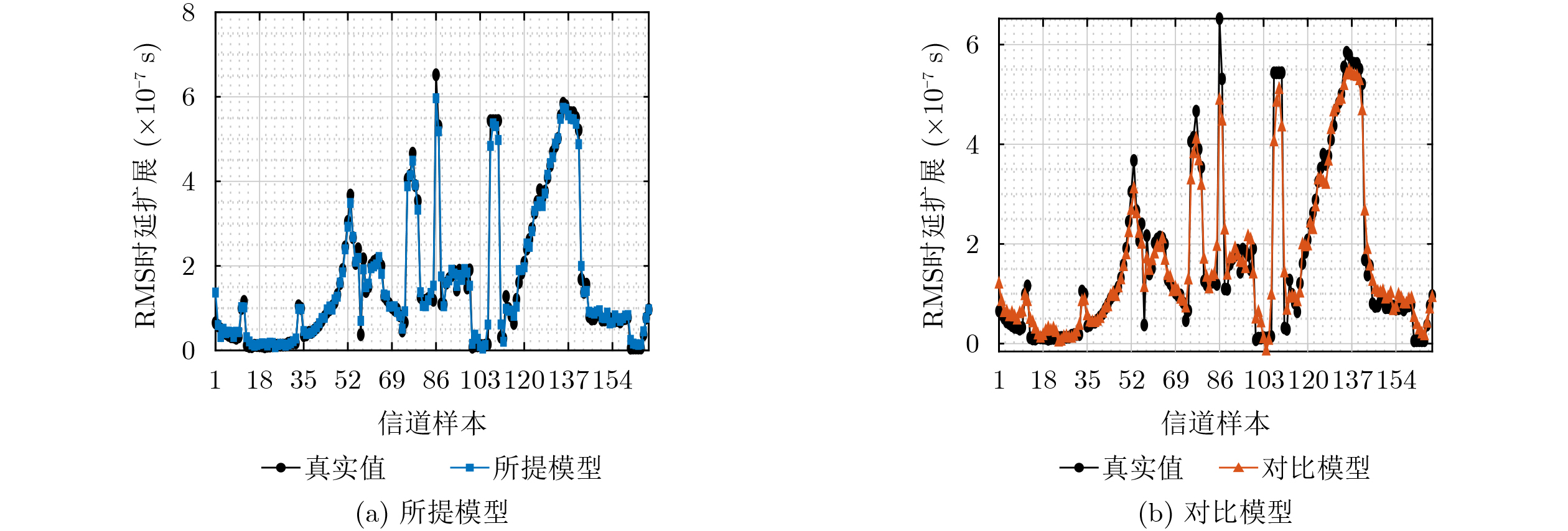
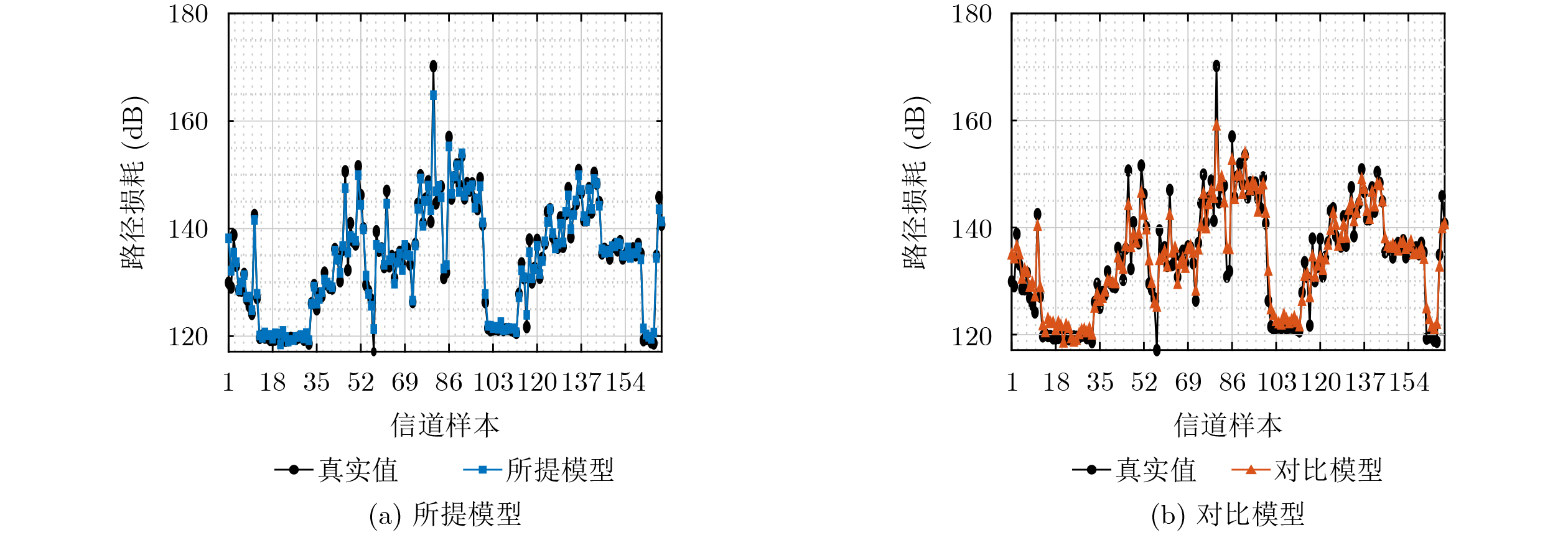
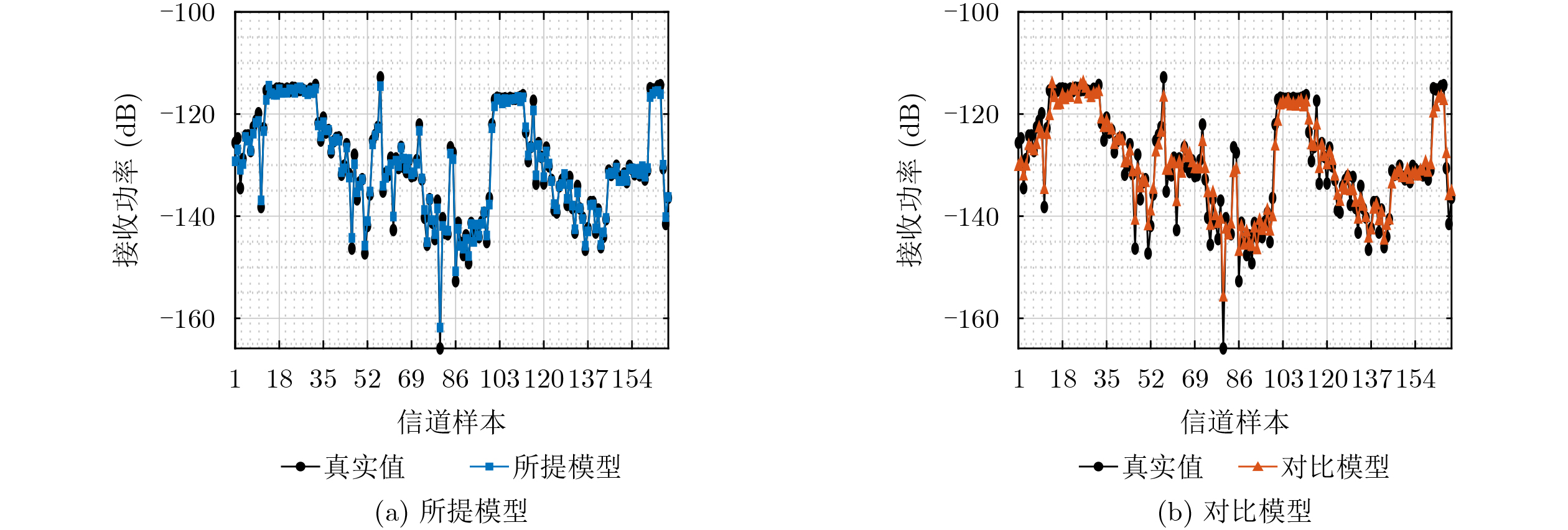
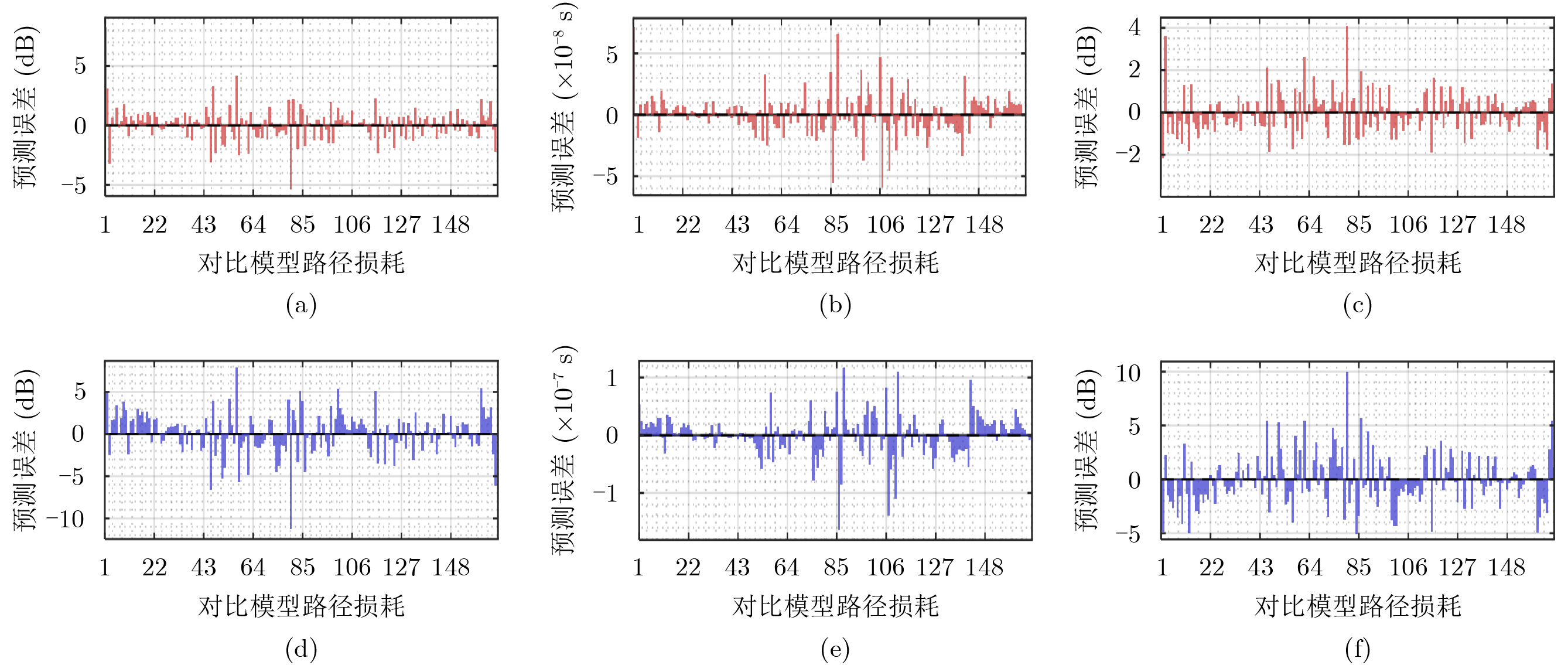
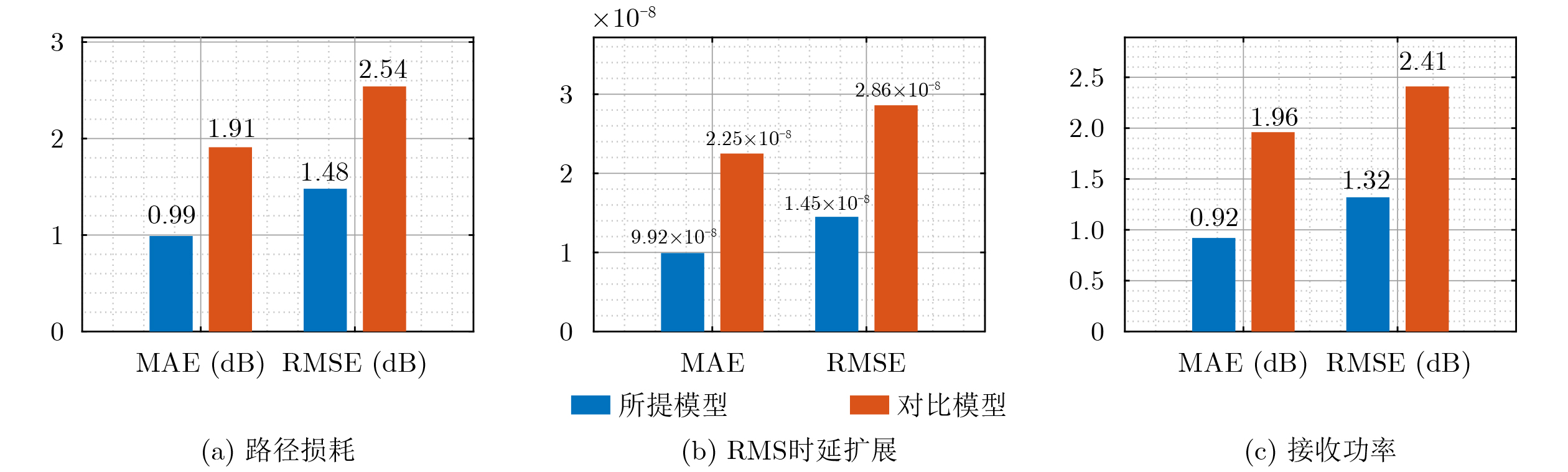
Objective Accurate prediction of air-to-ground (A2G) channel states is essential for adaptive transmission and resource optimization in unmanned aerial vehicle (UAV) communications. In urban millimeter-wave scenarios, however, A2G links are highly sensitive to blockage, reflection, scattering, and the rapidly changing geometric relationship among the transmitter, the receiver, and surrounding buildings. As a result, the channel exhibits strong spatial and temporal nonstationarity, and conventional pilot- or feedback-based acquisition methods may become ineffective because the obtained channel state information is easily outdated. Recent data-driven approaches have shown potential, but many of them rely heavily on historical channel observations or directly use raw images as network inputs, which may introduce redundant visual information and weaken physical interpretability. To address these limitations, this paper proposes a vision-assisted millimeter-wave A2G channel prediction method that extracts low-dimensional geometric features from the propagation environment instead of using raw visual data directly. The objective is to preserve the key structural information governing channel evolution while reducing irrelevant redundancy, thereby improving the prediction of channel. Methods A communication-and-sensing integrated dataset with strict spatial and temporal alignment is established for millimeter-wave UAV A2G channel prediction. On the sensing side, a high-fidelity three-dimensional urban scenario containing 23 buildings, roads, and intersections is constructed in Unreal Engine 4.27, where synchronized RGB and depth images are collected through AirSim using a multirotor UAV equipped with RGB and depth cameras. The UAV flies along 10 preset trajectories at a height of 55 m with a spatial sampling interval of 1 m, yielding 2160 valid visual samples (Fig. 1 ,Fig. 2 ). On the communication side, the same scene is reconstructed in Wireless InSite, and the transmitter-receiver positions are synchronously updated along the same trajectories to ensure frame-level alignment between visual and channel data (Fig. 3 ). To obtain compact and physically meaningful environmental representations, a cross-modal spatial feature extraction scheme is developed. Buildings are first detected from RGB images using YOLO-V8 (Fig. 4 ), and the detected regions are then registered with depth images to reconstruct three-dimensional point clouds. After Euclidean clustering and axis-aligned bounding-box fitting, key geometric attributes, including planar position, height, and volume, are extracted. These features are combined with the transmitter-receiver distance to form the spatial feature vector of each frame, and their relevance to path loss, received power, and RMS delay spread is evaluated through cosine-similarity-based correlation analysis (Fig. 6 ). Based on the extracted features, a hybrid Transformer-MLP network is designed for channel prediction (Fig. 5 ). Building features are first projected into a latent space, and a stacked Transformer encoder is employed to capture global interactions among buildings through masked multi-head self-attention. Masked average pooling is then used to aggregate building-level representations into a scene-level environmental descriptor, which is concatenated with the link distance feature and fed into a multilayer perceptron regressor to predict the three target channel parameters.Results and Discussions The results confirm the effectiveness of the proposed spatial feature representation. Correlation analysis shows that the extracted geometric features are consistently related to path loss, received power, and RMS delay spread under different aggregation strategies ( Fig. 6 ), indicating that compact building descriptors can effectively characterize the propagation environment. Among them, building height exhibits the strongest correlation with all three channel parameters, highlighting its important role in blockage, attenuation, and multipath propagation in urban millimeter-wave A2G channels. In prediction experiments, the proposed method accurately tracks the variation trends of all three targets. It remains effective in deep-fading and sharp-fluctuation regions for path loss prediction (Fig. 7 ), achieves high consistency with the ground truth for RMS delay spread (Fig. 8 ), and follows rapid local fluctuations of received power with good fidelity (Fig. 9 ). In contrast, the benchmark model only captures the general trend and shows larger deviations in peaks, valleys, and abrupt-changing intervals. Residual analysis further demonstrates the superiority of the proposed method. Its errors are more concentrated around zero and fluctuate within narrower ranges than those of the benchmark model across all three tasks (Fig. 10 ). Quantitatively, both the mean absolute error and the root mean squared error are reduced (Fig. 11 ). In addition, the model maintains acceptable complexity, with about 5.5 M parameters and a single-frame inference delay of about 3.4 ms, indicating good potential for real-time deployment.Conclusions A vision-assisted millimeter-wave A2G channel prediction method for UAV communications is proposed. By constructing a strictly aligned communication-and-sensing dataset and extracting low-dimensional spatial features with clear physical meaning, the method establishes an effective mapping from environmental geometry to channel parameters. The proposed Transformer-MLP framework achieves accurate prediction of path loss, received power, and RMS delay spread, while offering better interpretability, robustness, and efficiency than the benchmark model. -
表 1 RGB相机和深度相机参数设置
参数 RGB相机 深度相机 宽度 1080 320 长度 1080 320 视场角度数 90° 90° 自动曝光速度 100 100 运动模糊量 0 0  下载: 导出CSV
下载: 导出CSV
表 2 信道预测超参数设定
超参数 设定值 Batch Size 32 Epochs 200 Learning rate 0.01 Activation function GeLU Optimizer Adam
下载: 导出CSV
-
[1] 陶静, 侯萌, 彭薇, 等. 伪三维卷积注意力网络的多步信道预测[J]. 电子与信息学报, 2026, 48(1): 394–403. doi: 10.11999/JEIT251090.TAO Jing, HOU Meng, PENG Wei, et al. A Multi-step channel prediction method based on pseudo-3D convolutional neural network with attention mechanism[J]. Journal of Electronics & Information Technology, 2026, 48(1): 394–403. doi: 10.11999/JEIT251090. [2] CUI Yanpeng, FENG Zhiyong, ZHANG Qixun, et al. Toward trusted and swift UAV communication: ISAC-enabled dual identity mapping[J]. IEEE Wireless Communications, 2023, 30(1): 58–66. doi: 10.1109/MWC.003.2200207. [3] LIU Lihong, FENG Hui, YANG Tao, et al. MIMO-OFDM wireless channel prediction by exploiting spatial-temporal correlation[J]. IEEE Transactions on Wireless Communications, 2014, 13(1): 310–319. doi: 10.1109/TWC.2013.112613.130455. [4] ZENG Fanhui, ZHANG Rongqing, CHENG Xiang, et al. Channel prediction based scheduling for data dissemination in VANETs[J]. IEEE Communications Letters, 2017, 21(6): 1409–1412. doi: 10.1109/LCOMM.2017.2676766. [5] 游雨欣, 姜兴龙, 刘会杰, 等. TDD OTFS低轨卫星通信系统的LLM信道预测方法[J]. 电子与信息学报, 2025, 47(8): 2535–2548. doi: 10.11999/JEIT250105.YOU Yuxin, JIANG Xinglong, LIU Huijie, et al. LLM channel prediction method for TDD OTFS low-earth-orbit satellite communication systems[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2535–2548. doi: 10.11999/JEIT250105. [6] STENHAMMAR O, FODOR G, and FISCHIONE C. A comparison of neural networks for wireless channel prediction[J]. IEEE Wireless Communications, 2024, 31(3): 235–241. doi: 10.1109/MWC.006.2300140. [7] MELIHA M, CHARGÉ P, WANG Yide, et al. Deep learning-based channel prediction with path extraction[J]. IEEE Wireless Communications Letters, 2025, 14(3): 891–895. doi: 10.1109/LWC.2025.3527345. [8] WANG Jun, GONG Shenyi, XIAO Jian, et al. A lightweight channel prediction network for UAV-LEO satellite communications[J]. IEEE Wireless Communications Letters, 2025, 14(1): 113–117. doi: 10.1109/LWC.2024.3489677. [9] 廖勇, 尹子松, 田肖懿. 车联网V2I场景下基于GNN的SC-FDMA智能信道估计[J]. 电子学报, 2024, 52(3): 772–782. doi: 10.12263/DZXB.20220545.LIAO Yong, YIN Zisong, and TIAN Xiaoyi. Intelligent channel estimation of SC-FDMA based on GNN for V2I scenarios in internet of vehicles[J]. Acta Electronica Sinica, 2024, 52(3): 772–782. doi: 10.12263/DZXB.20220545. [10] 赵川斌, 许伟华, 林博, 等. 融合视觉的多模态通信感知一体化关键技术及原型验证[J]. 电子与信息学报, 2026, 48(2): 487–498. doi: 10.11999/JEIT250685.ZHAO Chuanbin, XU Weihua, LIN bo, et al. Vision enabled multimodal integrated sensing and communications: Key technologies and prototype validation[J]. Journal of Electronics & Information Technology, 2026, 48(2): 487–498. doi: 10.11999/JEIT250685. [11] SUN Mingran, BAI Lu, HUANG Ziwei, et al. Multi-modal sensing data-based real-time path loss prediction for 6G UAV-to-ground communications[J]. IEEE Wireless Communications Letters, 2024, 13(9): 2462–2466. doi: 10.1109/LWC.2024.3419245. [12] ZHANG Xuejian, HE Ruisi, YANG Mi, et al. Vision aided channel prediction for vehicular communications: A case study of received power prediction using RGB Images[J]. IEEE Transactions on Vehicular Technology, 2025, 74(11): 17531–17544. doi: 10.1109/TVT.2025.3579333. [13] GUPTA A, DU Jinfeng, CHIZHIK D, et al. Machine learning-based urban canyon path loss prediction using 28 GHz Manhattan measurements[J]. IEEE Transactions on Antennas and Propagation, 2022, 70(6): 4096–4111. doi: 10.1109/TAP.2022.3152776. [14] NISHIO T, OKAMOTO H, NAKASHIMA K, et al. Proactive received power prediction using machine learning and depth images for mmWave networks[J]. IEEE Journal on Selected Areas in Communications, 2019, 37(11): 2413–2427. doi: 10.1109/JSAC.2019.2933763. [15] AHMADIEN O, ATES H F, BAYKAS T, et al. Predicting path loss distribution of an area from satellite images using deep learning[J]. IEEE Access, 2020, 8: 64982–64991. doi: 10.1109/ACCESS.2020.2985929. [16] YIN Hongpei, LIU P X, and ZHENG Minhua. Stereo visual-inertial odometry with online initialization and extrinsic self-calibration[J]. IEEE Transactions on Instrumentation and Measurement, 2023, 72: 9508210. doi: 10.1109/TIM.2023.3282674. [17] YUAN Xingyu, WANG Shuting, XIE Yuanlong, et al. Object-based semantic fusion algorithm of Lidar and camera via inverse projection[J]. IEEE Transactions on Instrumentation and Measurement, 2025, 74: 9513215. doi: 10.1109/TIM.2025.3548241. [18] GENG Maosi, LI Junyi, XIA Yingji, et al. A physics-informed transformer model for vehicle trajectory prediction on highways[J]. Transportation Research Part C: Emerging Technologies, 2023, 154: 104272. doi: 10.1016/j.trc.2023.104272. [19] TALAAT F M and ZAINELDIN H. An improved fire detection approach based on YOLO-v8 for smart cities[J]. Neural Computing and Applications, 2023, 35(28): 20939–20954. doi: 10.1007/s00521-023-08809-1. [20] 游雨欣, 姜兴龙, 刘会杰, 等. TDD OTFS低轨卫星通信系统的LLM信道预测方法[J]. 电子与信息学报, 2025, 47(8): 2535–2548. doi: 10.11999/JEIT250105. (查阅网上资料,本条文献与第5条文献重复,请确认).YOU Yuxin, JIANG Xinglong, LIU Huijie, et al. LLM channel prediction method for TDD OTFS low-earth-orbit satellite communication systems[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2535–2548. doi: 10.11999/JEIT250105. -


 下载:
下载:




图(11) / 表(3)
计量
- 文章访问数: 178
- HTML全文浏览量: 68
- PDF下载量: 12
- 被引次数: 0
