

VT2R: Video and Text-driven Method for Generating Large-scale Millimeter-wave Radar Data
-
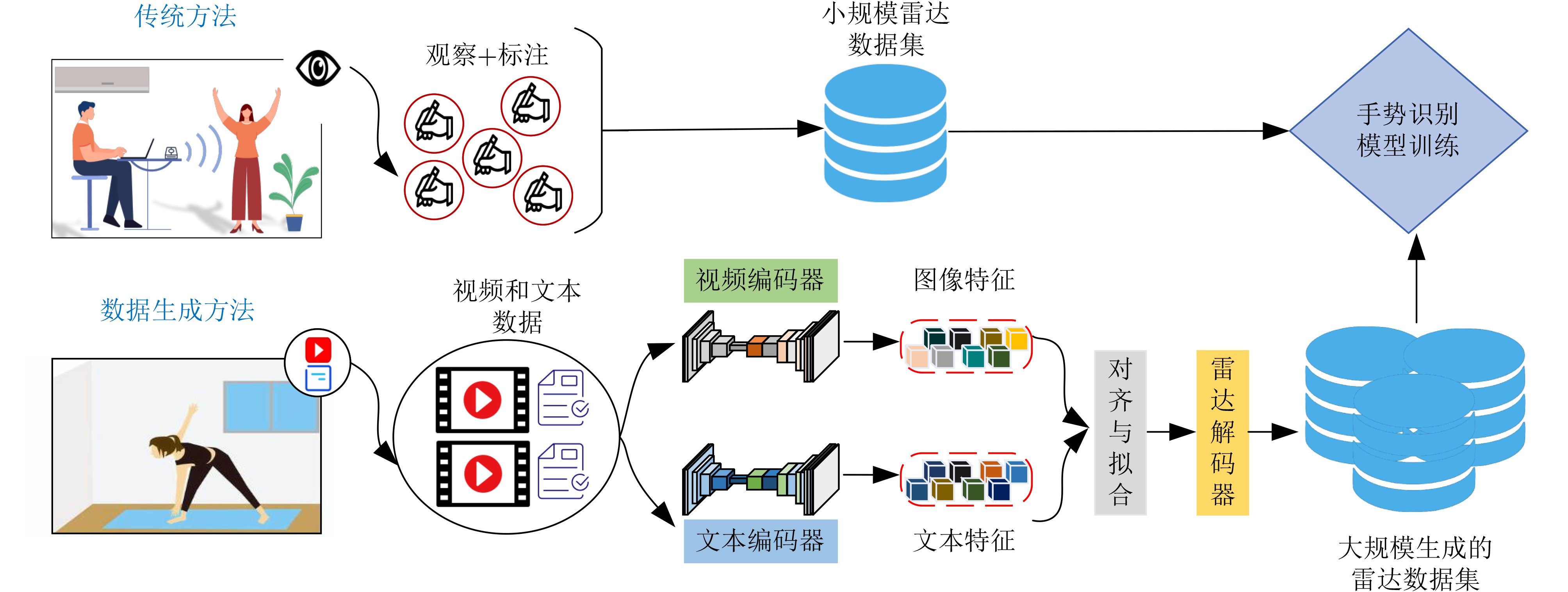
摘要: 基于毫米波雷达的手势识别已经成为一种很有前景的人机交互方式并应用于多个领域。然而,大规模训练数据的不足严重阻碍了开发鲁棒和普适的深度学习模型,尤其在用户躺姿场景更为显著。现有的毫米波雷达数据生成方法由于缺乏足够的数据源而效果不佳。为此,本文提出了一种新颖的雷达数据生成系统VT2R,其利用视频或文本数据生成大规模逼真的雷达数据,解决了视频和文本到雷达数据的映射关系难构建的关键问题。VT2R由四个组件组成:视频特征编码网络、文本特征编码网络和雷达特征编码网络分别建模三种模态输入的特征表示,随后数据拟合与解码网络基于变分自编码器机制对潜在分布进行对齐与解码,从而生成逼真的大规模雷达数据。最后,在生成与自采数据集上进行了广泛的实验验证,结果表明VT2R在识别躺姿场景下的手势方面显著优于现有最先进方法。Abstract:
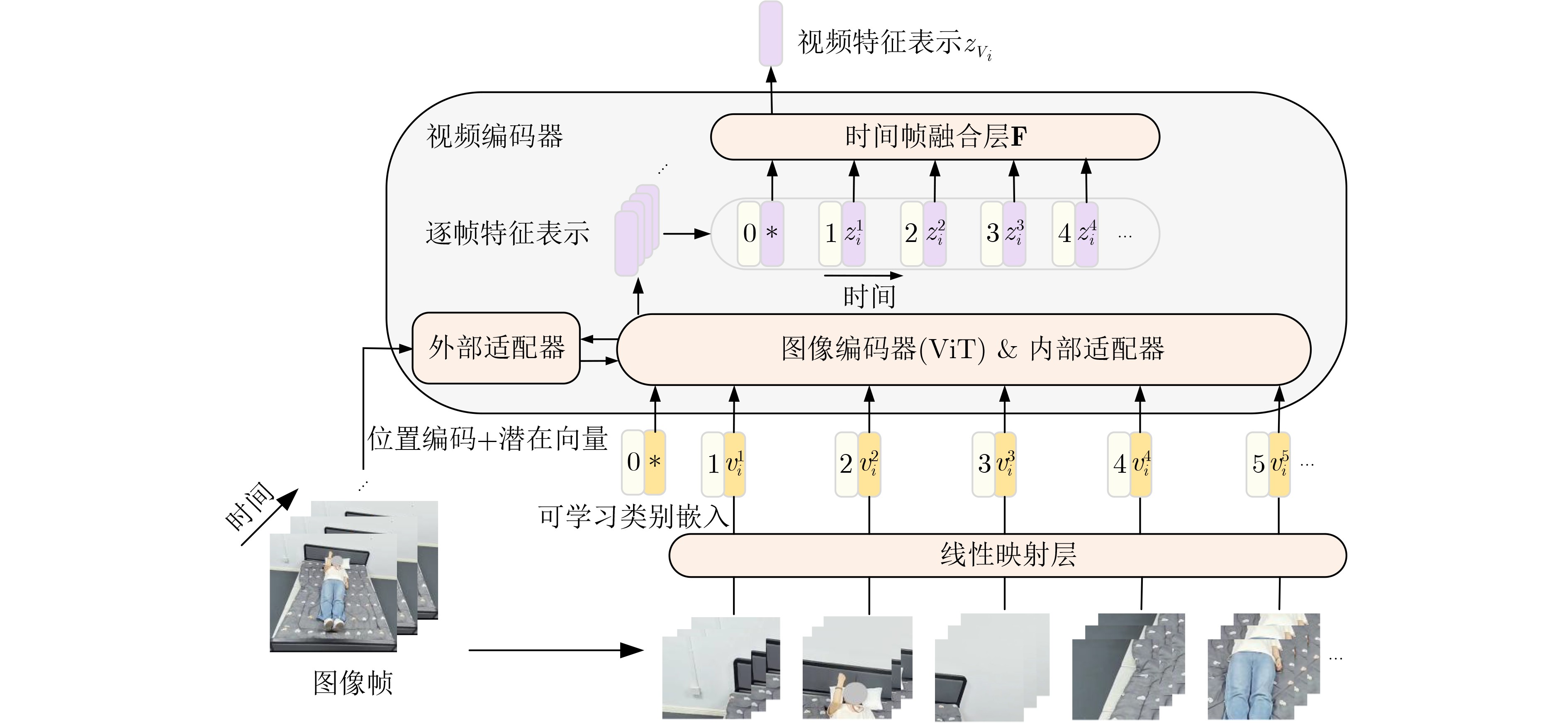
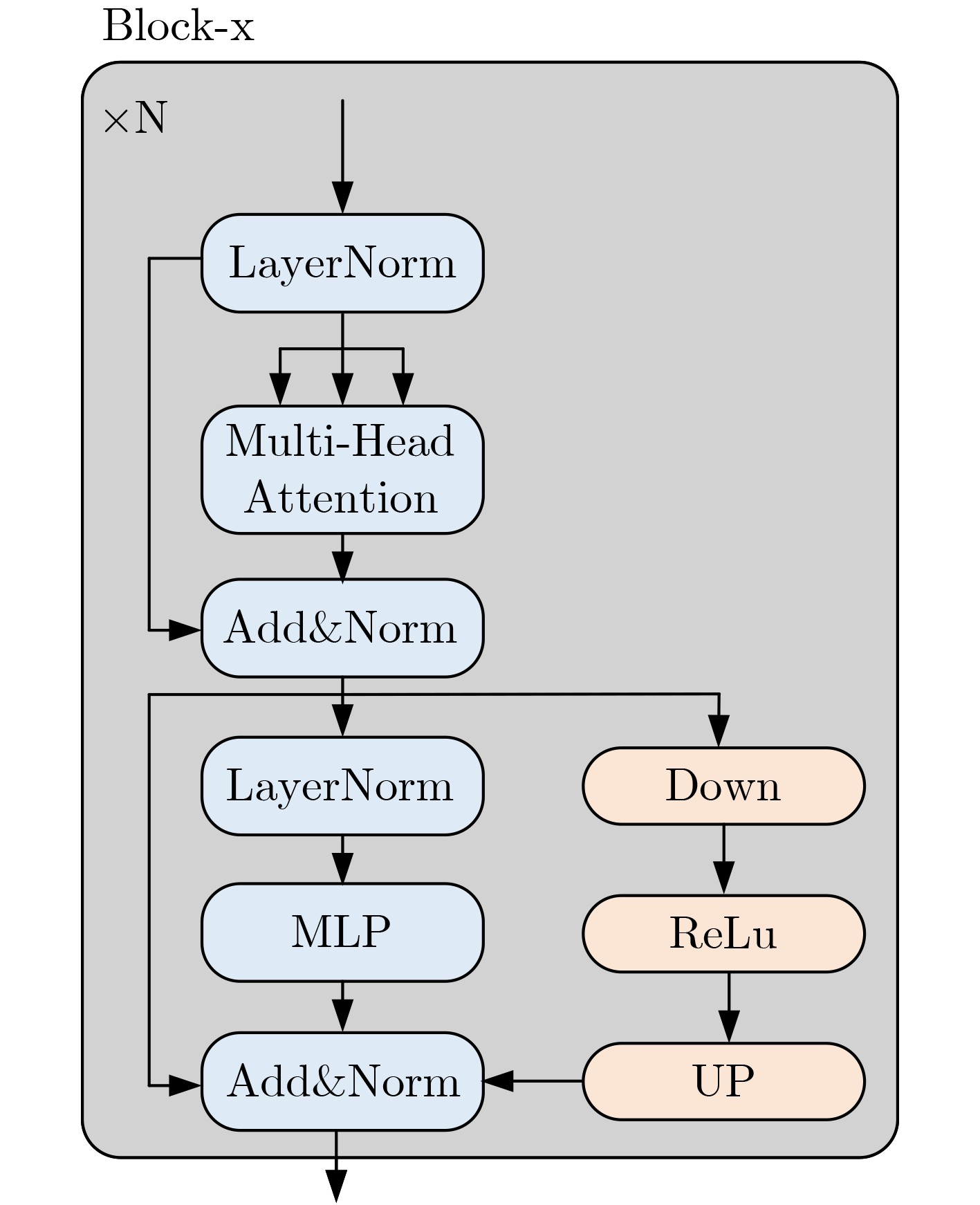
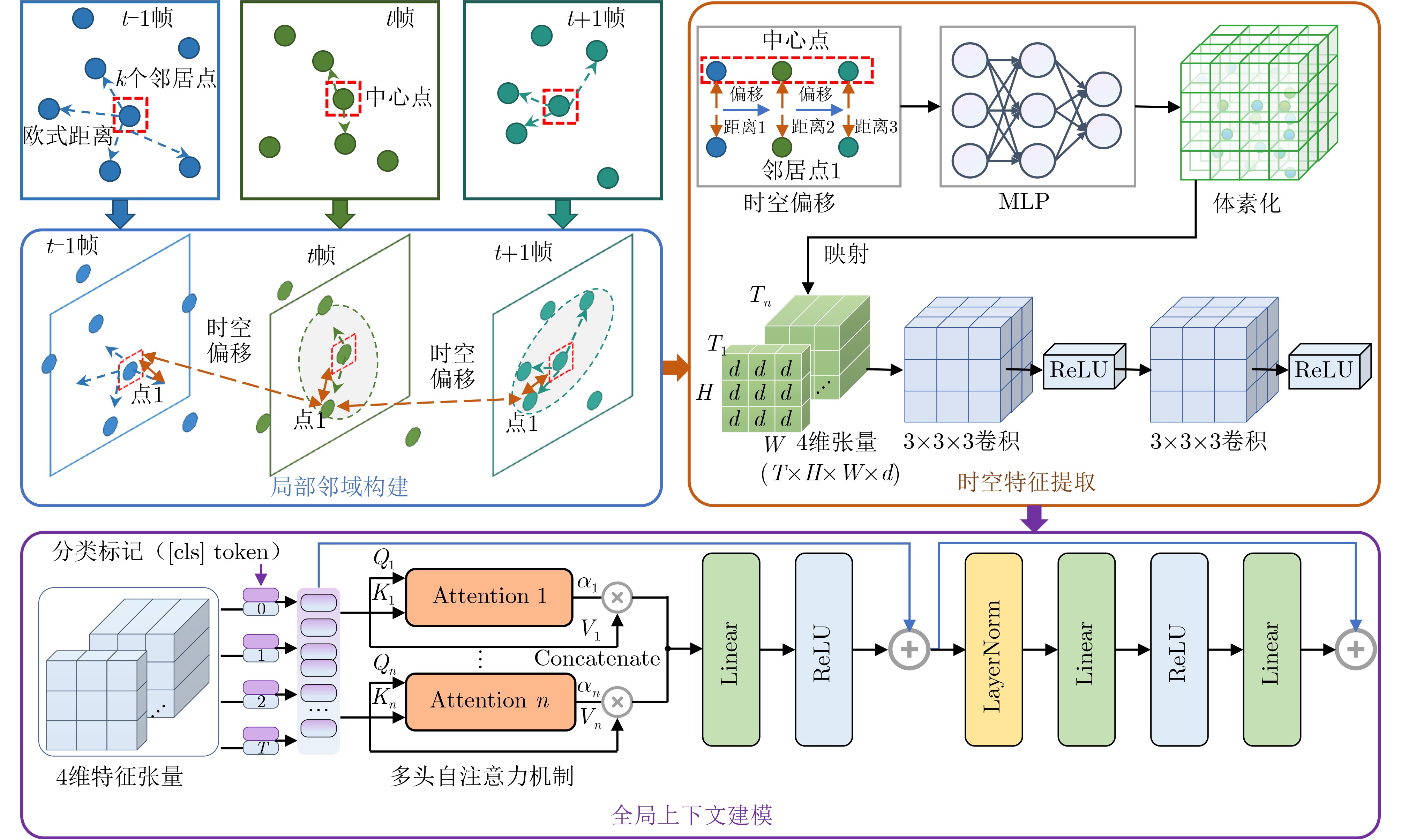
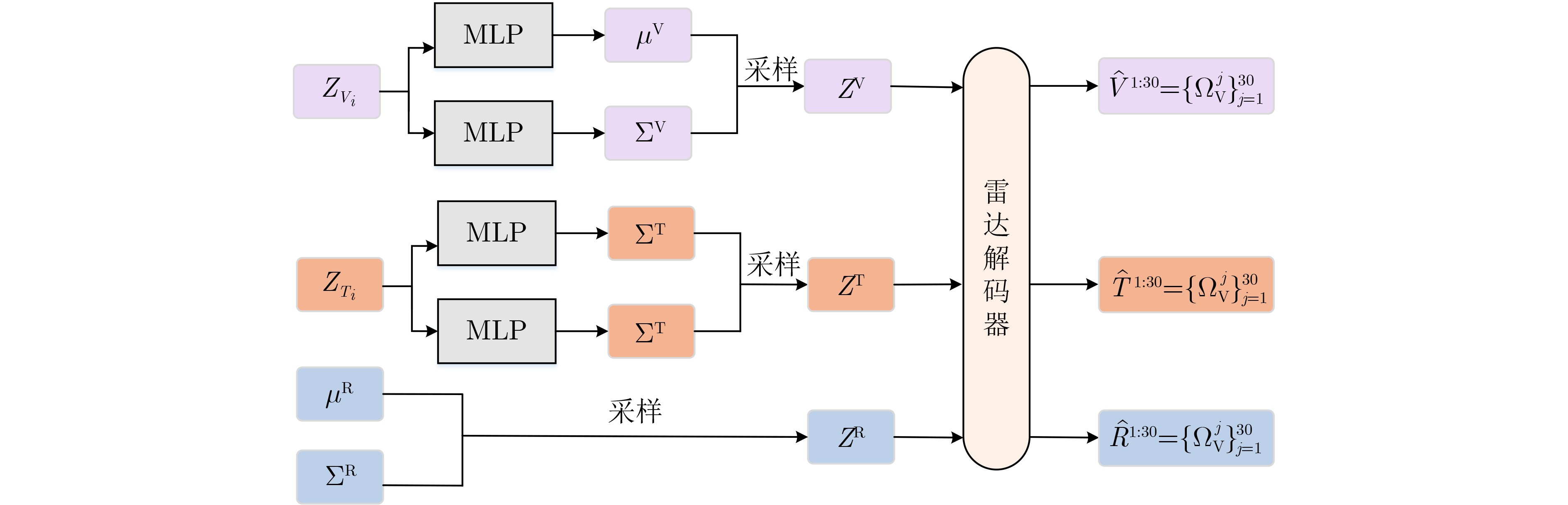
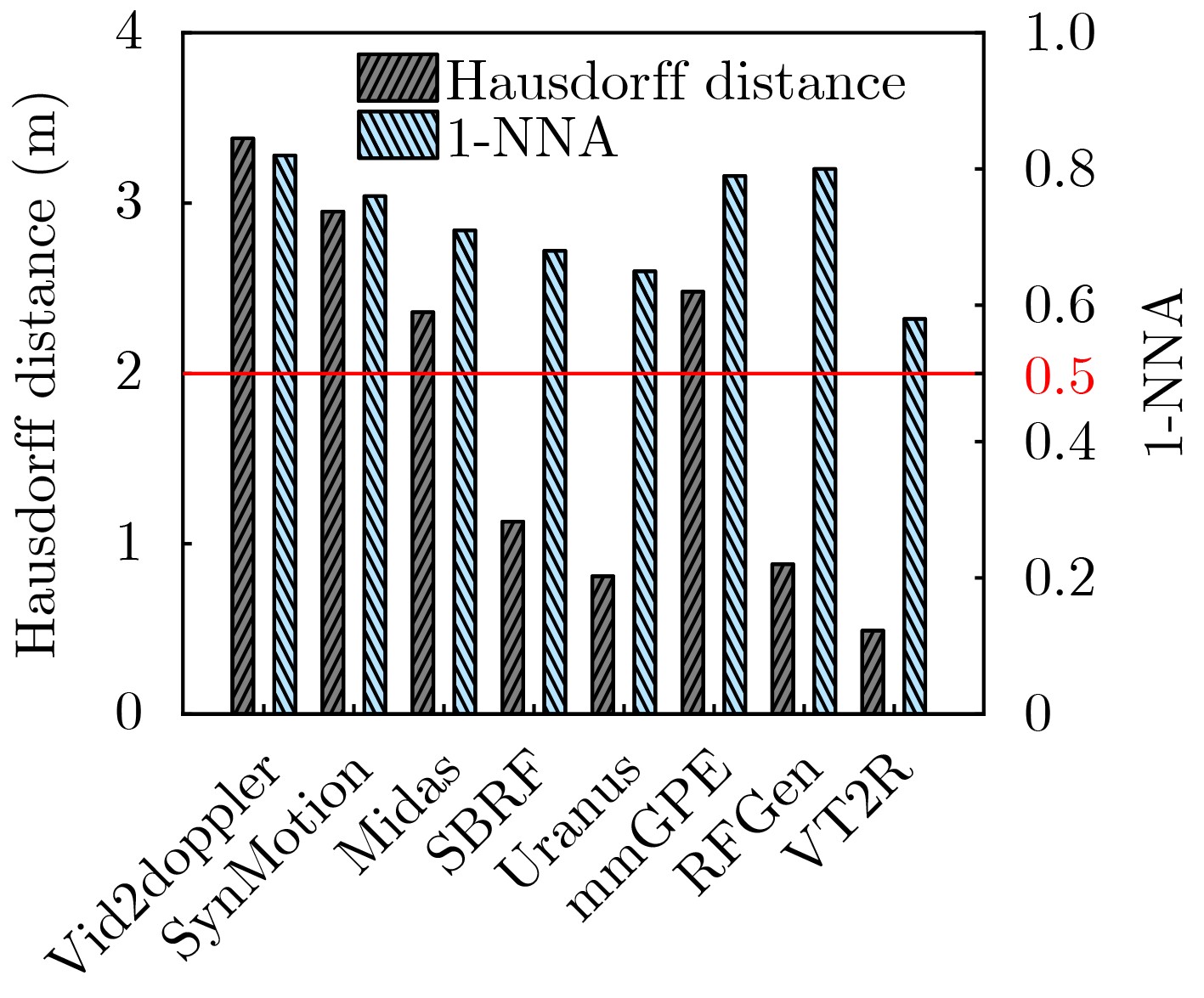
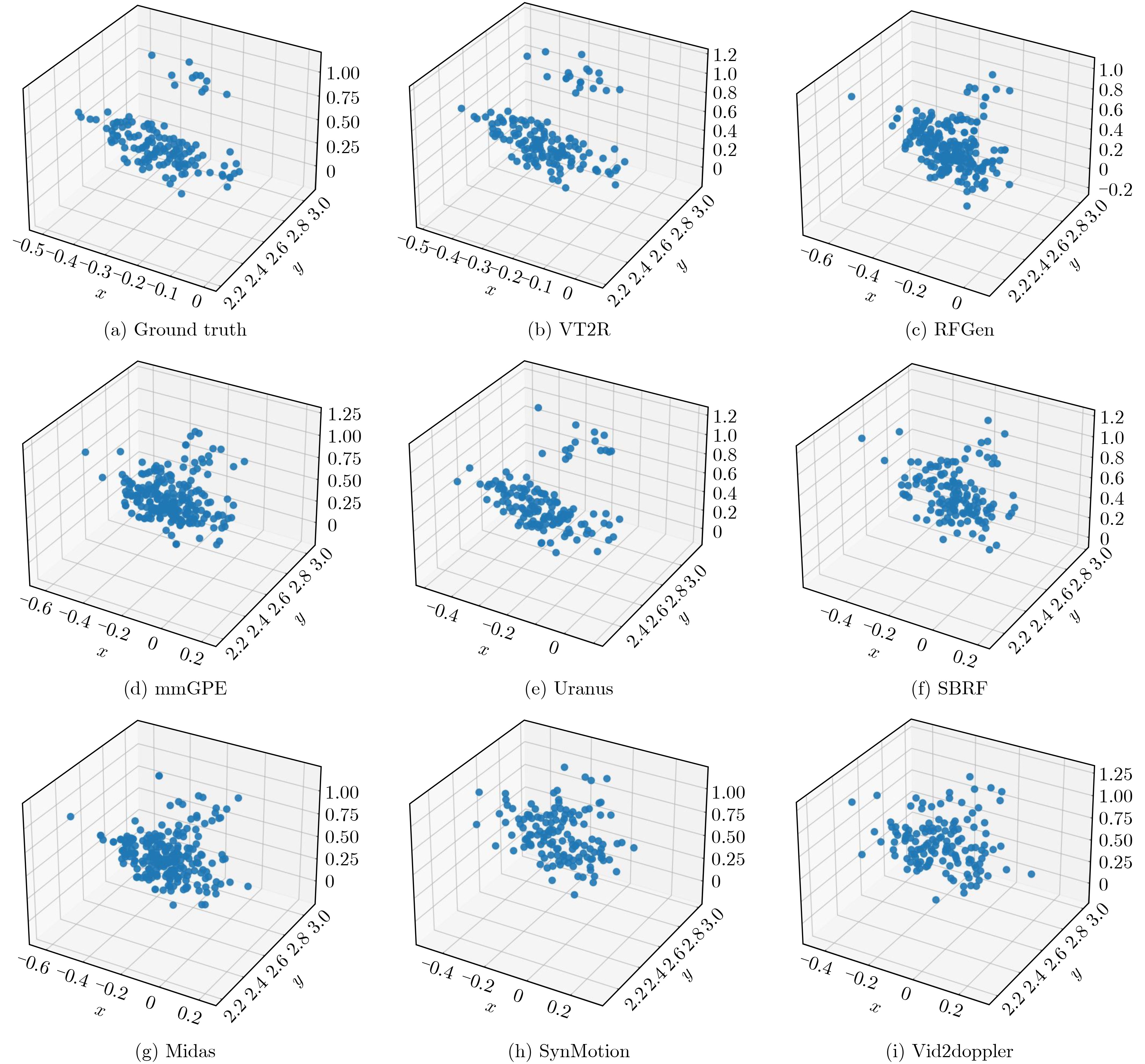
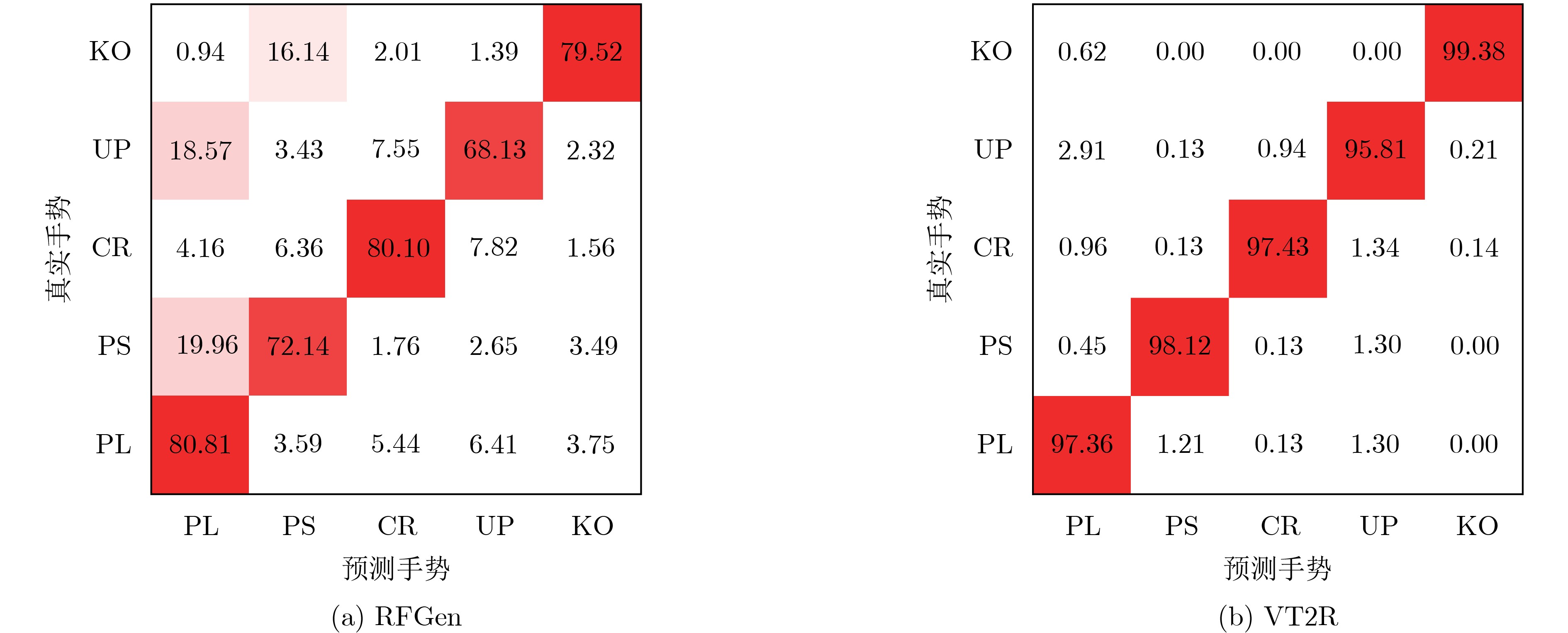
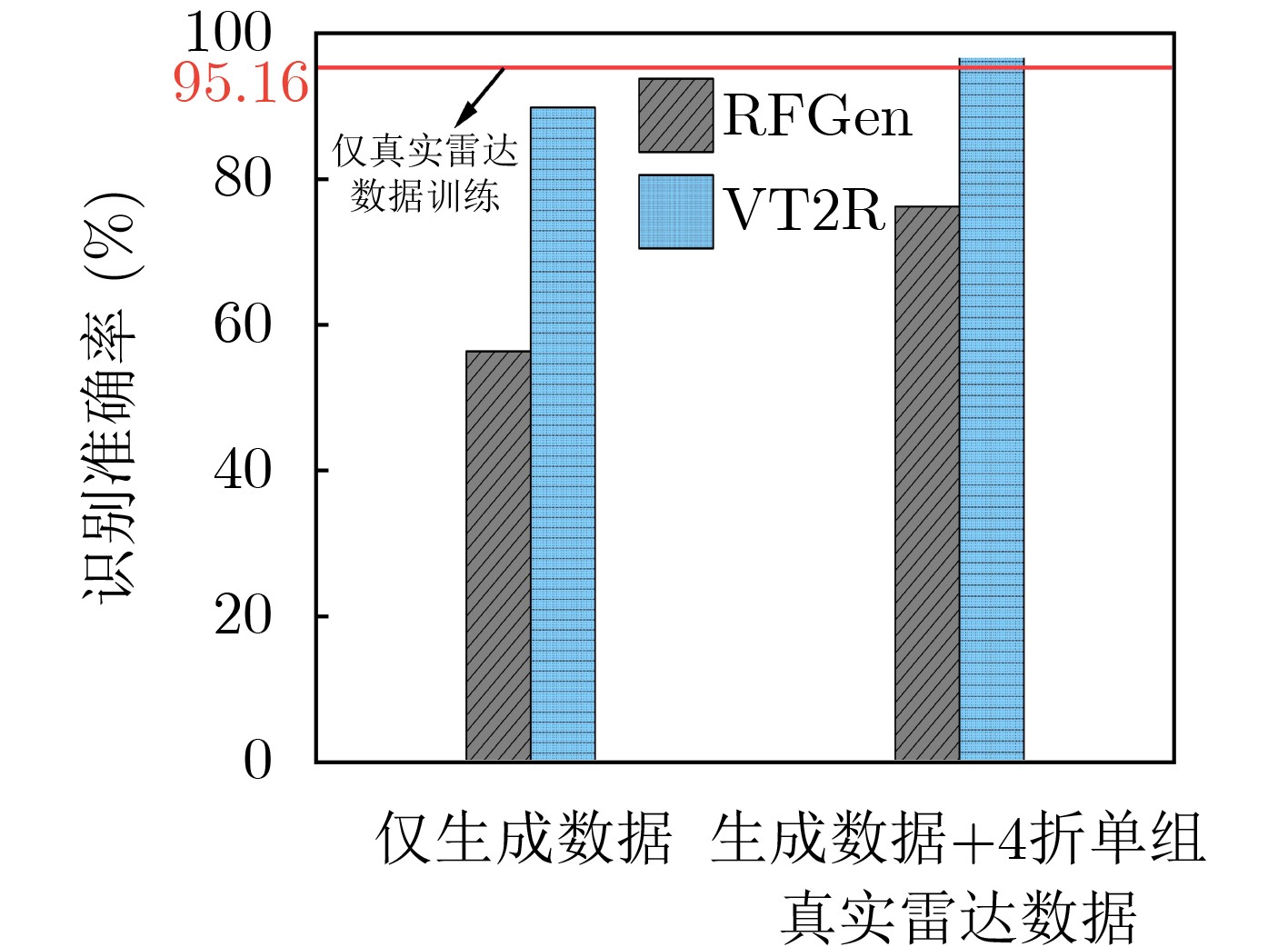
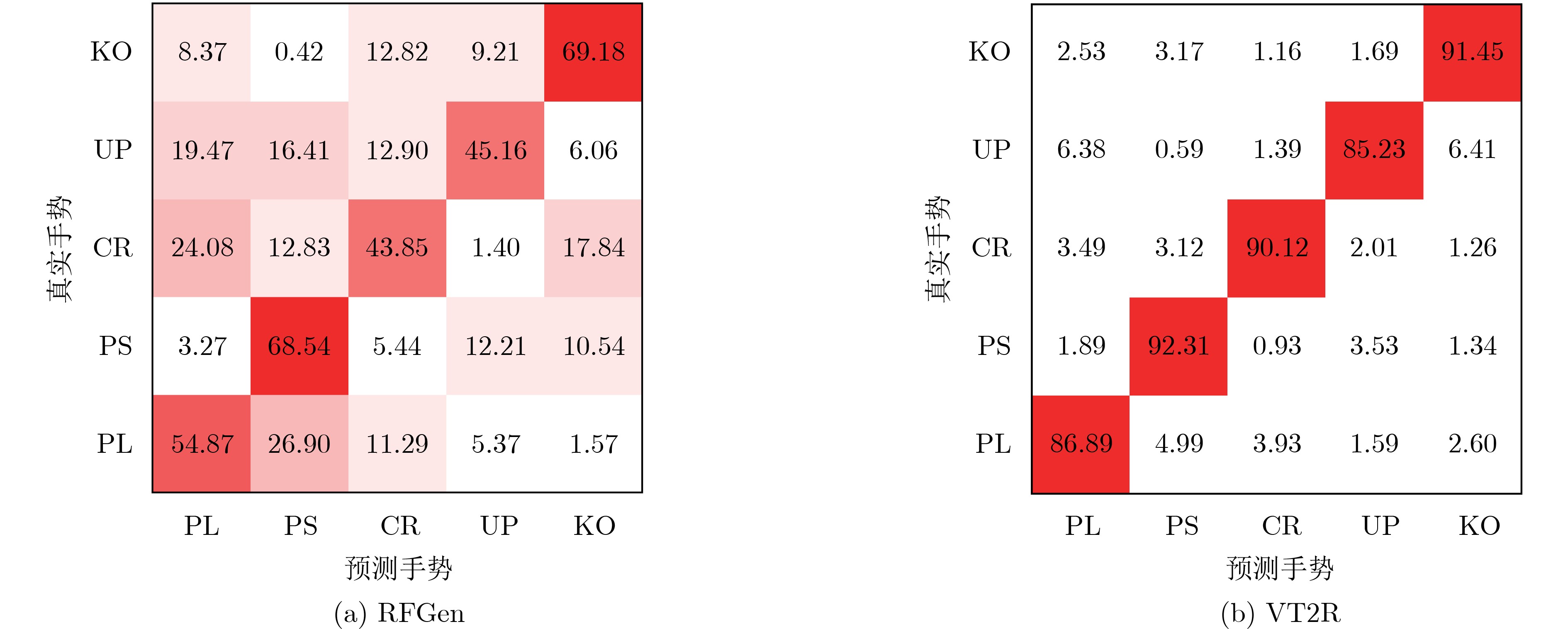
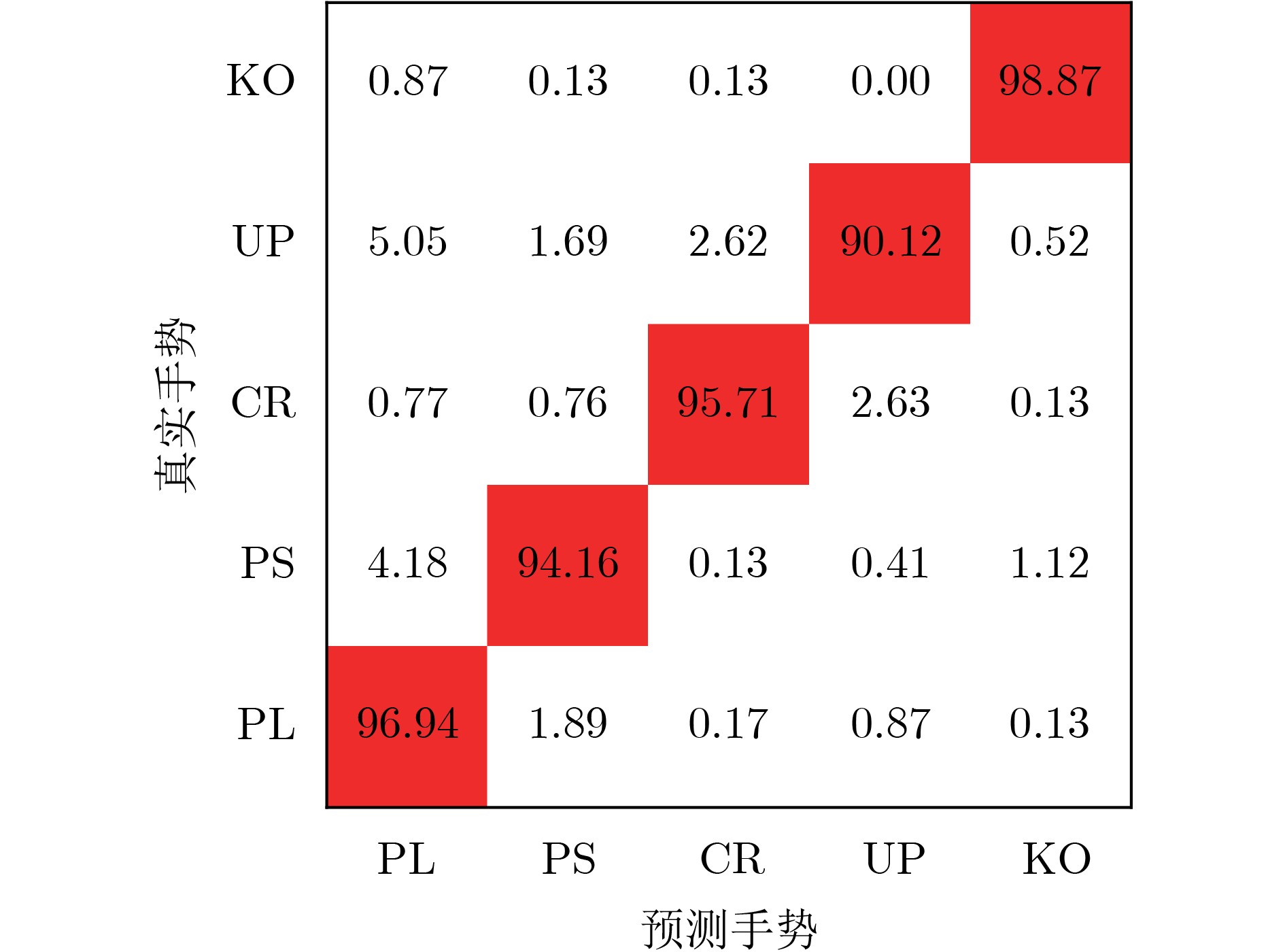
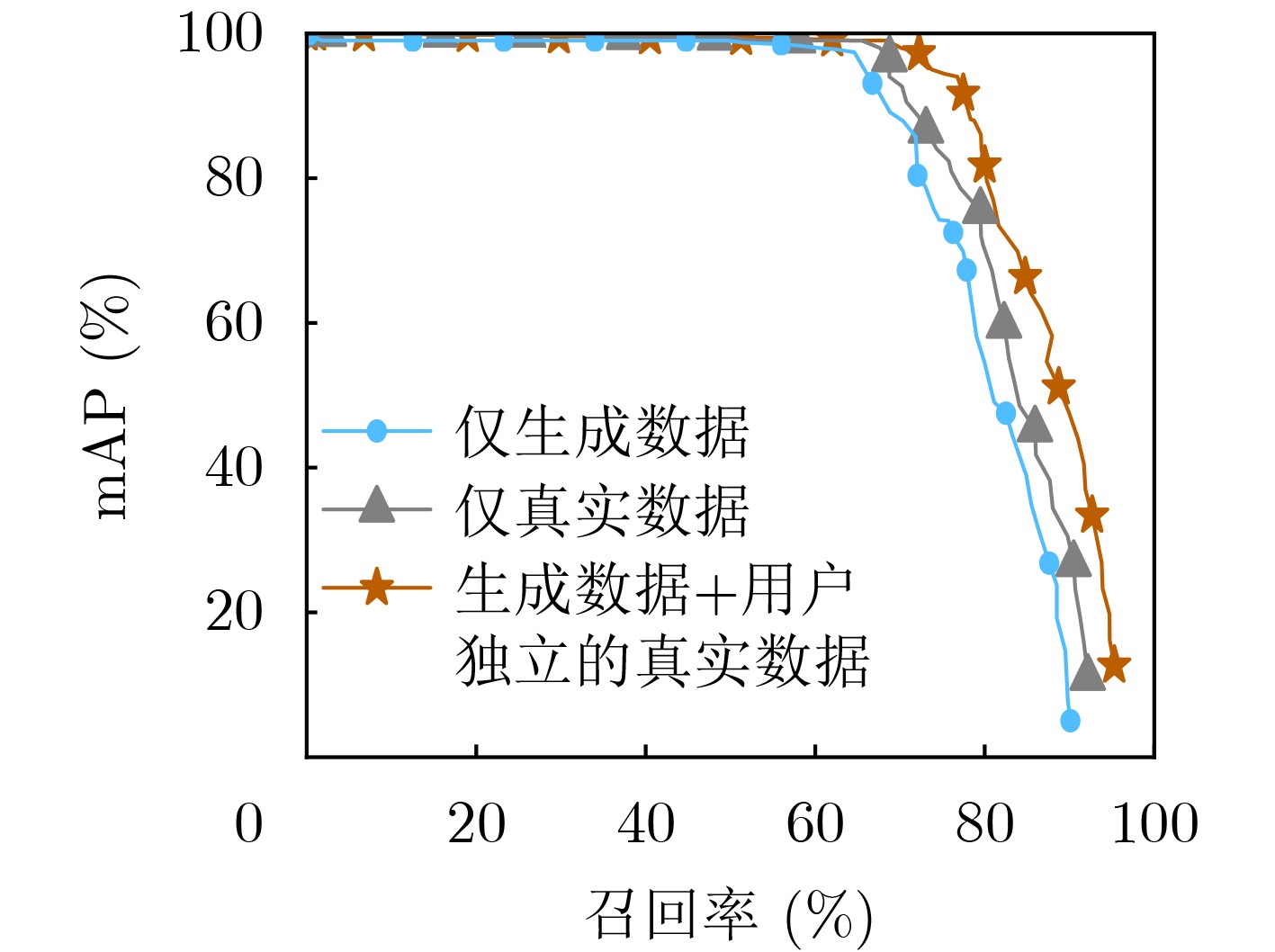
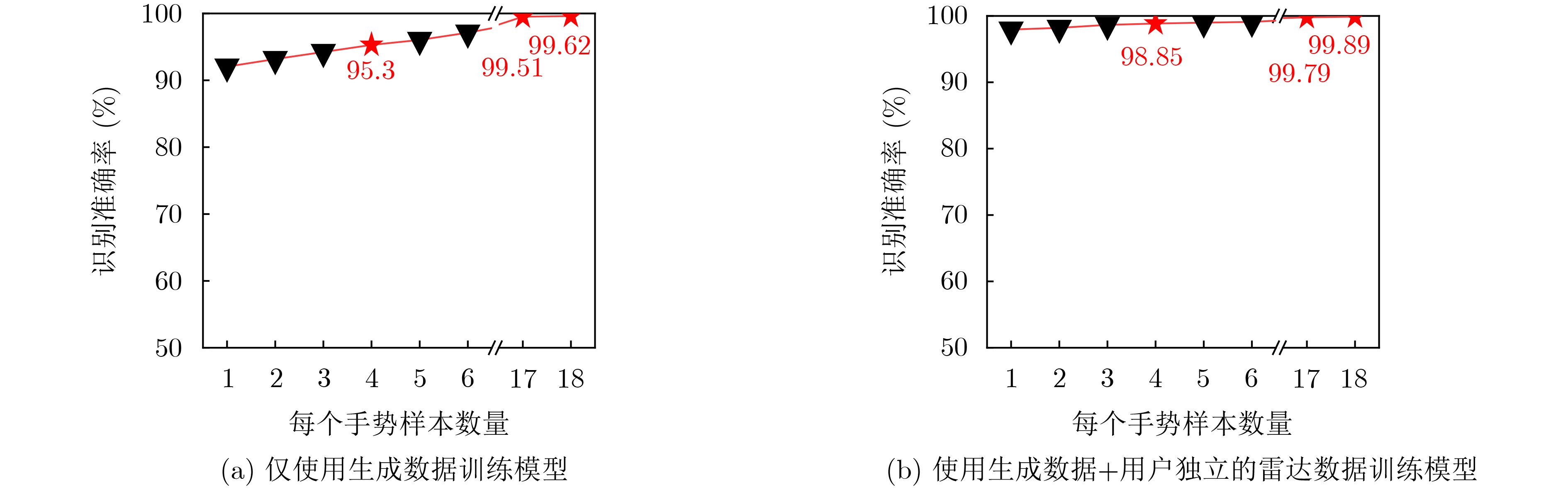
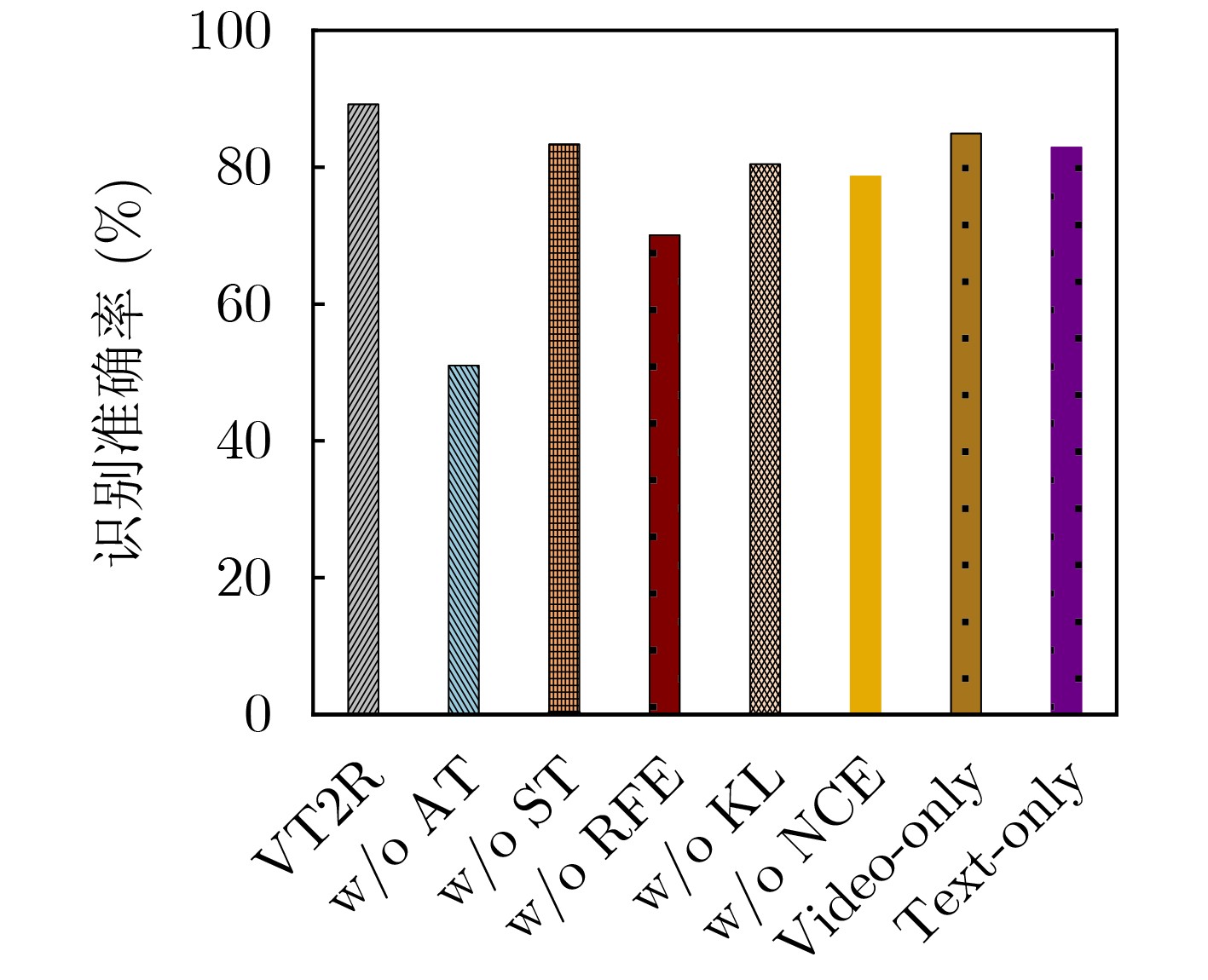
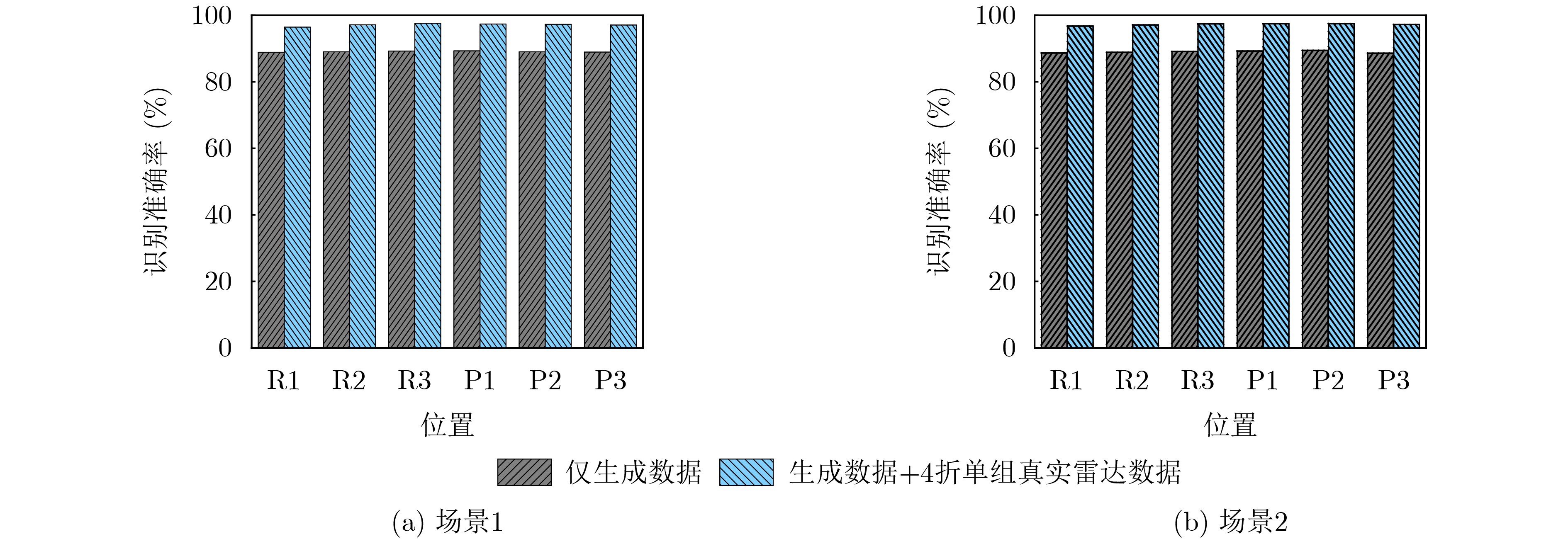
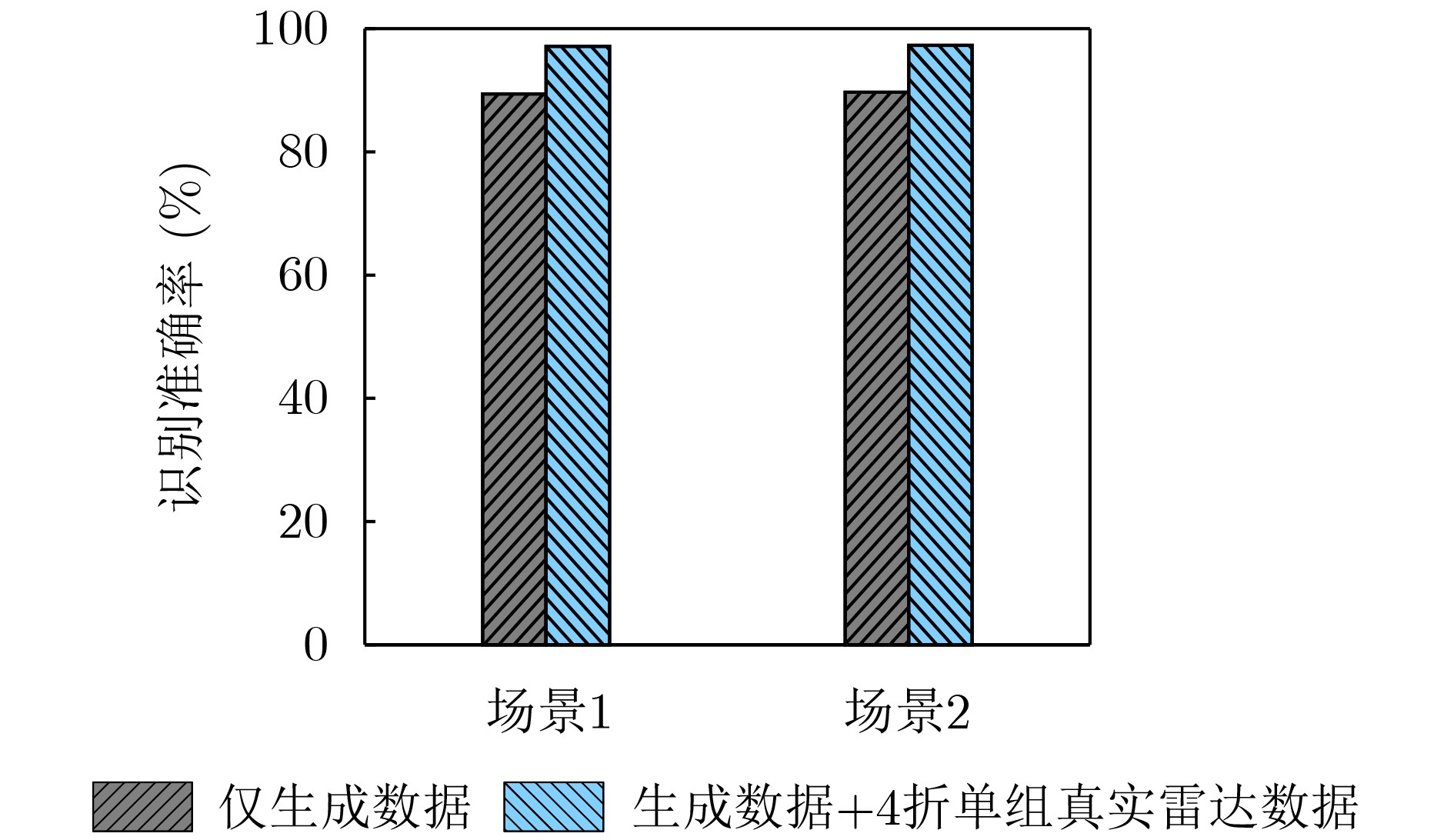
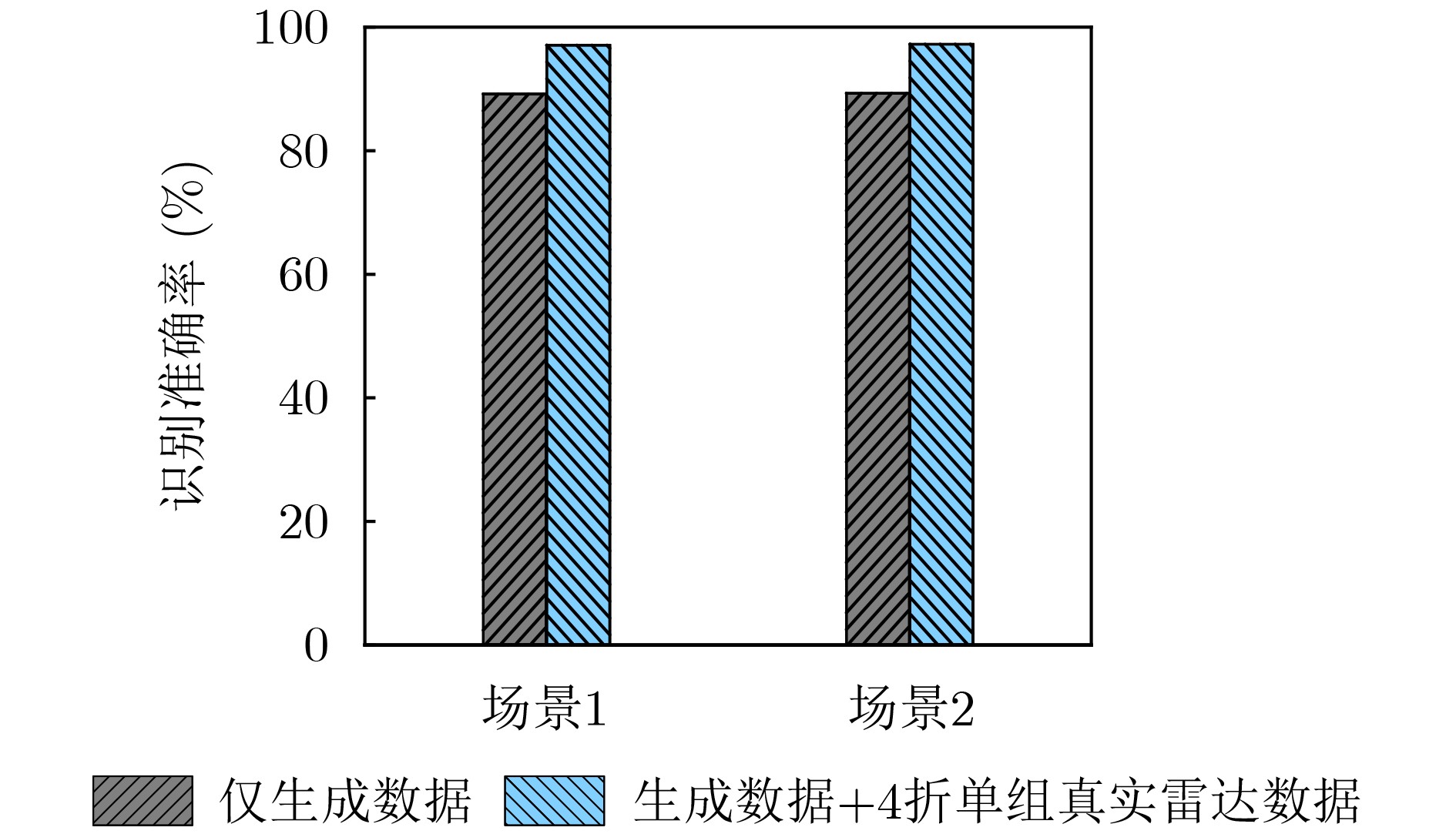
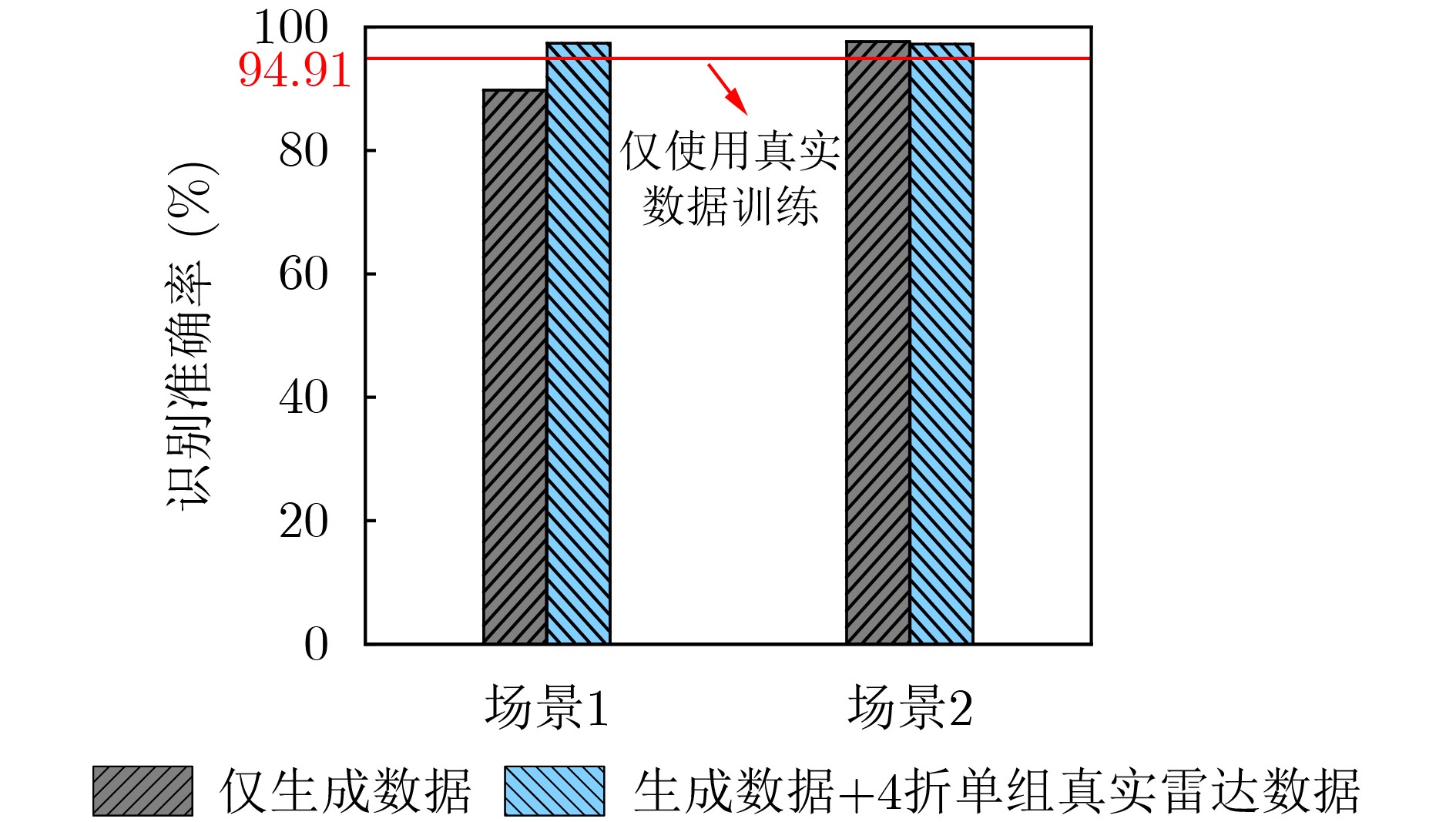
Objective The lack of large-scale training data impedes progress in developing robust and generalized deep learning models. However, existing millimeter-wave radar data generation methods are ineffective due to a lack of sufficient data sources. To address this gap, this paper proposes a video and text-driven radar data generation method, VT2R, which utilizes video or text data to generate large-scale, realistic radar data, solving the key problem of constructing the mapping relationship between video and text and radar data. Methods The proposed method consists of three main components: video feature encoding network, text feature encoding network, radar feature encoding network and data fitting and decoding network. Video feature encoding networks and text feature encoding networks extract temporally consistent visual representations and alignable semantic features, respectively, while the radar encoding network learns the structure and dynamic information of point clouds through hierarchical spatiotemporal modeling. In the data fitting and decoding network based on Variational AutoEncoder (VAE), multi-modal features are mapped to a unified latent distribution space and decoded into radar data through reparameterized sampling. During training, reconstruction loss, Kullback-Leibler (KL) divergence loss, and cross-modal similarity loss are jointly optimized. Results and Discussions This paper constructs the first radar point cloud dataset for reclining gesture recognition ( Figs. 6 and7 ), covering 5 gesture categories, 32 participants, and a total of 14,400 samples. Experimental results based on this dataset show that VT2R achieves a recognition accuracy of 89.2% when trained using only generated radar data, a 33.88% improvement over the representative RFGen (Figs. 9 and10 ). When combined with a small amount of real radar data for joint training, the accuracy further improves to 97.62%, a 21.48% improvement over RFGen (Figs. 9 and11 ). Furthermore, VT2R still achieves average recognition accuracies of 89.35% and 97.21% under different scenarios and factors (Figs. 16 -18 ). In addition, this paper also verifies the accuracy of VT2R under different postures, achieving average accuracies of 89.98% and 97.55% in the first and third settings, respectively (Fig. 19 ), which is basically consistent with the result obtained when lying down, demonstrating its robustness under cross-posture conditions.Conclusions This paper proposes a radar data generation system, VT2R, which addresses the severe lack of realistic radar training data when users are performing gestures in a lying position. Through a video feature encoding network built on a vision-language pre-trained model, a text encoding network incorporating cue templates, a hierarchical radar encoding network for sparse point clouds, and a VAE-based data fitting and decoding network, these components collaboratively generate large-scale, realistic radar data. It also supports augmented reconstruction based on limited real radar data, providing rich data support for radar perception tasks. Future work will focus on solving multi-modal data generation for more complex gesture scenes, providing better data support for emerging large-scale models. -
Key words:
- mmWave radar sensing /
- data generation /
- gesture recognition /
- variational autoencoder
-
[1] XING Ling, DENG Kaikai, WU Honghai, et al. The dawn of synthetic Era: Synthesizing mmWave radar data from 2D videos for human sensing[J]. IEEE Communications Magazine, 2025, 63(11): 14–20. doi: 10.1109/MCOM.001.2400488. [2] LIU Xiulong, LIU Hankai, ZHANG Jiaqi, et al. Multi-user behavioral privacy filtering for mmwave radar sensing[J]. IEEE Transactions on Mobile Computing, 2025, 24(9): 8347–8361. doi: 10.1109/TMC.2025.3556674. [3] YUAN Wenyang, ZHANG Jian, YUAN Wu, et al. 3D-sitpose: Millimeter wave radar-based human sitting posture estimation[J]. ACM Transactions on Sensor Networks, 2026, 22(2): 11. doi: 10.1145/3793858. [4] 赵川斌, 许伟华, 林博, 等. 融合视觉的多模态通信感知一体化关键技术及原型验证[J]. 电子与信息学报, 2026, 48(2): 487–498. doi: 10.11999/JEIT250685.ZHAO Chuanbin, XU Weihua, LIN Bo, et al. Vision enabled multimodal integrated sensing and communications: Key technologies and prototype validation[J]. Journal of Electronics & Information Technology, 2026, 48(2): 487–498. doi: 10.11999/JEIT250685. [5] LI Yaxuan, XU Dongzhu, LIANG Kun, et al. Mobi2Still: People detection and tracking with mobile human-equipped mmWave radars[J]. IEEE Transactions on Mobile Computing, 2026, 25(6): 9348–9364. doi: 10.1109/TMC.2026.3656239. [6] KIM Y B, HAN S S, and LEE H L. Cost-effective FMCW radar with enhanced tracking coverage for smart healthcare applications[J]. IEEE Transactions on Consumer Electronics, 2026, 72(2): 3330–3340. doi: 10.1109/TCE.2026.3667885. [7] YANG Huanqi, HAN Mingda, LI Xinyue, et al. iradar: Synthesizing millimeter-waves from wearable inertial inputs for human gesture sensing[C]. Proceedings of 2025 IEEE Conference on Computer Communications, London, United Kingdom, 2025: 1–10. doi: 10.1109/INFOCOM55648.2025.11044481. [8] DING Fangqiang, LUO Zhen, ZHAO Peijun, et al. milliFlow: Scene flow estimation on mmWave radar point cloud for human motion sensing[C]. Proceedings of the 18th European Conference on Computer Vision, Milan, Italy, 2024: 202–221. doi: 10.1007/978-3-031-72691-0_12. [9] 冉鑫怡, 陈前斌, 徐勇军, 等. 基于深度学习的通感一体化系统综述[J]. 通信学报, 2025, 46(6): 233–250. doi: 10.11959/j.issn.1000-436x.2025103.RAN Xinyi, CHEN Qianbin, XU Yongjun, et al. Survey on deep learning-based integrated sensing and communication systems[J]. Journal on Communications, 2025, 46(6): 233–250. doi: 10.11959/j.issn.1000-436x.2025103. [10] JIN Can, MENG Xiangzhu, LI Xuanheng, et al. Rodar: Robust gesture recognition based on mmWave radar under human activity interference[J]. IEEE Transactions on Mobile Computing, 2024, 23(12): 11735–11749. doi: 10.1109/TMC.2024.3402356. [11] CHOI J, HOR S, YANG Shubo, et al. MVDoppler-Pose: Multi-modal multi-view mmWave sensing for long-distance self-occluded human walking pose estimation[C]. Proceedings of 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 27750–27759. doi: 10.1109/CVPR52734.2025.02584. [12] MARIKYAN D, PAPAGIANNIDIS S, RANA O F, et al. Working in a smart home environment: Examining the impact on productivity, well-being and future use intention[J]. Internet Research, 2024, 34(2): 447–473. doi: 10.1108/INTR-12-2021-0931. [13] KRIZHEVSKY A, SUTSKEVER I, and HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84–90. doi: 10.1145/3065386. [14] YANG Pinci, WANG Xin, DUAN Xuguang, et al. AVQA: A dataset for audio-visual question answering on videos[C]. Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 2022: 3480–3491. doi: 10.1145/3503161.3548291. [15] Khowaja S A, KHUWAJA P, DHAREJO F A, et al. ReFuSeAct: Representation fusion using self-supervised learning for activity recognition in next generation networks[J]. Information Fusion, 2024, 102: 102044. doi: 10.1016/j.inffus.2023.102044. [16] KWON H, TONG C, HARESAMUDRAM H, et al. IMUTube: Automatic extraction of virtual on-body accelerometry from video for human activity recognition[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2020, 4(3): 87. doi: 10.1145/3411841. [17] LENG Zikang, BHATTACHARJEE A, RAJASEKHAR H, et al. IMUGPT 2.0: Language-based cross modality transfer for sensor-based human activity recognition[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2024, 8(3): 112. doi: 10.1145/3678545. [18] SEYFIOGLU M S, EROL B, GURBUZ S Z, et al. Diversified radar micro-Doppler simulations as training data for deep residual neural networks[C]. Proceedings of 2018 IEEE Radar Conference, Oklahoma City, USA, 2018: 612–617. doi: 10.1109/RADAR.2018.8378629. [19] EROL B and GURBUZ S Z. A Kinect-based human micro-Doppler simulator[J]. IEEE Aerospace and Electronic Systems Magazine, 2015, 30(5): 6–17. doi: 10.1109/MAES.2015.7119820. [20] XUE Hongfei, CAO Qiming, MIAO Chenglin, et al. Towards generalized mmWave-based human pose estimation through signal augmentation[C]. Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2023: 88. doi: 10.1145/3570361.3613302. [21] EROL B, GURBUZ S Z, and AMIN M G. Motion classification using kinematically sifted ACGAN-synthesized radar micro-Doppler signatures[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020, 56(4): 3197–3213. doi: 10.1109/TAES.2020.2969579. [22] RAHMAN M M, MALAIA E A, GURBUZ A C, et al. Effect of kinematics and fluency in adversarial synthetic data generation for ASL recognition with RF sensors[J]. IEEE Transactions on Aerospace and Electronic Systems, 2022, 58(4): 2732–2745. doi: 10.1109/TAES.2021.3139848. [23] CHEN Xingyu and ZHANG Xinyu. RF genesis: Zero-shot generalization of mmWave sensing through simulation-based data synthesis and generative diffusion models[C]. Proceedings of the 21st ACM Conference on Embedded Networked Sensor Systems, Istanbul, Turkiye, 2023: 28–42. doi: 10.1145/3625687.3625798. [24] CHI Guoxuan, YANG Zheng, WU Chenshu, et al. RF-diffusion: Radio signal generation via time-frequency diffusion[C]. Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, Washington, USA, 2024: 77–92. doi: 10.1145/3636534.3649348. [25] AHUJA K, JIANG Yue, GOEL M, et al. Vid2doppler: Synthesizing Doppler radar data from videos for training privacy-preserving activity recognition[C]. Proceedings of 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 2021: 292. doi: 10.1145/3411764.3445138. [26] ZHANG Xiaotong, LI Zhenjiang, and ZHANG Jin. Synthesized millimeter-waves for human motion sensing[C]. Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, Boston, USA, 2022: 377–390. doi: 10.1145/3560905.3568542. [27] DENG Kaikai, ZHAO Dong, HAN Qiaoyue, et al. Midas: Generating mmWave radar data from videos for training pervasive and privacy-preserving human sensing tasks[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2023, 7(1): 9. doi: 10.1145/3580872. [28] DENG Kaikai, ZHAO Dong, ZHANG Zihan, et al. Midas++: Generating training data of mmWave radars from videos for privacy-preserving human sensing with mobility[J]. IEEE Transactions on Mobile Computing, 2024, 23(6): 6650–6666. doi: 10.1109/TMC.2023.3325399. [29] LI Jiamu, ZHANG Dongheng, WU Zhi, et al. SBRF: A fine-grained radar signal generator for human sensing[J]. IEEE Transactions on Mobile Computing, 2024, 23(12): 13114–13130. doi: 10.1109/TMC.2024.3427406. [30] DENG Kaikai, ZHAO Dong, ZHENG Wenxin, et al. G3R: Generating rich and fine-grained mmWave radar data from 2D videos for generalized gesture recognition[J]. IEEE Transactions on Mobile Computing, 2025, 24(4): 2917–2934. doi: 10.1109/TMC.2024.3502668. [31] LING Yue, ZHAO Dong, DENG Kaikai, et al. Uranus: Empowering generalized gesture recognition with mobility through generating large-scale mmWave radar data[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2024, 8(4): 204. doi: 10.1145/3699754. [32] ZHOU Yunjiao, YANG Jianfei, ZOU Han, et al. TENT: Connect language models with IoT sensors for zero-shot activity recognition[J]. IEEE Transactions on Mobile Computing, 2026, 25(6): 8314–8326. doi: 10.1109/TMC.2025.3650710. [33] KINGMA D P and WELLING M. Auto-encoding variational Bayes[C]. Proceedings of the 2nd International Conference on Learning Representations, Banff, Canada, 2024. [34] ZHANG JIAN, He Kaihao, YU Ting, et al. Semi-supervised RGB-D hand gesture recognition via mutual learning of self-supervised models[J]. ACM Transactions on Multimedia Computing, Communications and Applications, 2025, 21(4): 104. doi: 10.1145/3689644. [35] AMESAKA T, WATANABE H, SUGIMOTO M, et al. Gesture recognition method using acoustic sensing on usual garment[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2022, 6(2): 41. doi: 10.1145/3534579. [36] MA Zijing, ZHANG Shigeng, LIU Jia, et al. RF-Siamese: Approaching accurate RFID gesture recognition with one sample[J]. IEEE Transactions on Mobile Computing, 2024, 23(1): 797–811. doi: 10.1109/TMC.2022.3217487. [37] GAO Ruiyang, LI Wenwei, XIE Yaxiong, et al. Towards robust gesture recognition by characterizing the sensing quality of WiFi signals[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2022, 6(1): 11. doi: 10.1145/3517241. [38] 赵雅琴, 宋雨晴, 吴晗, 等. 基于DenseNet和卷积注意力模块的高精度手势识别[J]. 电子与信息学报, 2024, 46(3): 967–976. doi: 10.11999/JEIT230165.ZHAO Yaqin, SONG Yuqing, WU Han, et al. High-precision gesture recognition based on DenseNet and convolutional block attention module[J]. Journal of Electronics & Information Technology, 2024, 46(3): 967–976. doi: 10.11999/JEIT230165. [39] HAYASHI E, LIEN J, GILLIAN N, et al. RadarNet: Efficient gesture recognition technique utilizing a miniature radar sensor[C]. Proceedings of 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 2021: 5. doi: 10.1145/3411764.3445367. [40] CAI Hong, KORANY B, KARANAM C R, et al. Teaching RF to sense without RF training measurements[J]. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2020, 4(4): 120. doi: 10.1145/3432224. [41] LI Ruihui, LI Xianzhi, FU C W, et al. Pu-GAN: A point cloud upsampling adversarial network[C]. Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 7202–7211. doi: 10.1109/ICCV.2019.00730. -

 下载:
下载:




图(20)
计量
- 文章访问数: 218
- HTML全文浏览量: 143
- PDF下载量: 13
- 被引次数: 0
