

MG-MoE: Routed Multi-Granularity Expert Ensemble
-
摘要: 细粒度图像识别任务中,模型需在类间差异较小的条件下,同时捕捉局部判别线索与全局结构特征,且在复杂背景、姿态变化及长尾数据分布下,仍能保持稳定的泛化性能。该文提出一种基于路由机制的多粒度专家集成模型(MG-MoE),依托样本自适应条件计算机制,在可控推理开销内实现判别性能的提升。针对路由学习的稳定性与泛化性问题,提出两阶段优化策略。第1阶段为动态簇级训练,基于验证集统计构建簇级软教师分布,借助KL散度正则化稳定路由行为,推动专家间形成有效分工;第2阶段为残差微调,在保持特征驱动路由形式不变的前提下,按簇对Top-2专家的分类头进行解冻,并以分组学习率对门控与专家头联合微调,从而缓解专家融合偏差并增强模型对困难样本与长尾类别的判别能力。在CUB-200-2011与Bird-1445两个基准数据集上的实验结果表明,所提MG-MoE具有较好的有效性。其中,在CUB-200-2011上,MG-MoE取得了92.89%的准确率;在Bird-1445抽样集上,MG-MoE的准确率达到96.80%,均达到常见模型中的最佳准确率;消融分析进一步表明,受控的Top-2融合与4专家互补结构共同决定了性能上限,并在专家过少或同质扩展时呈现出可解释的退化规律。该研究为细粒度场景下的多粒度专家建模与路由训练提供了可复用的实现范式与分析框架。Abstract:
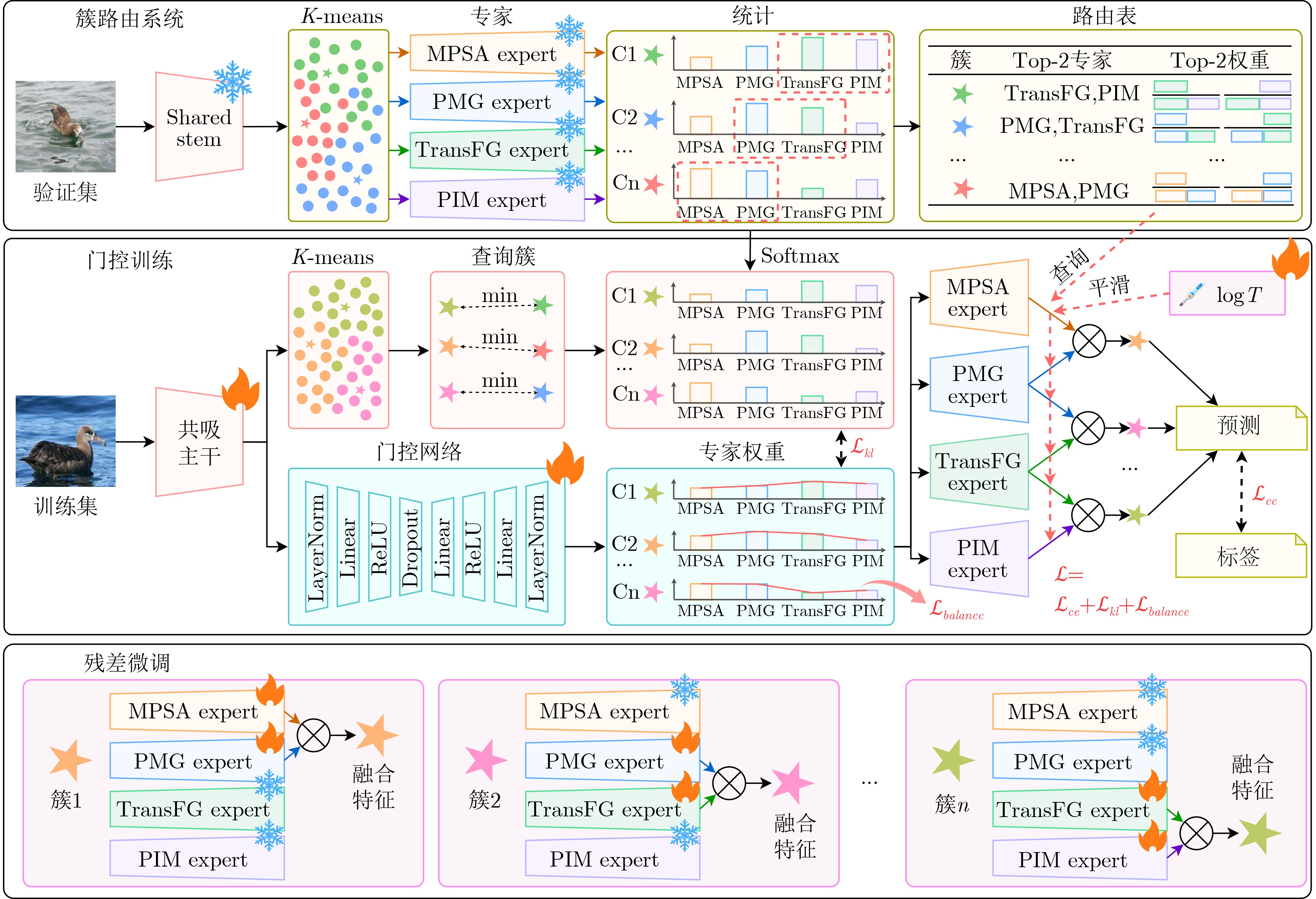
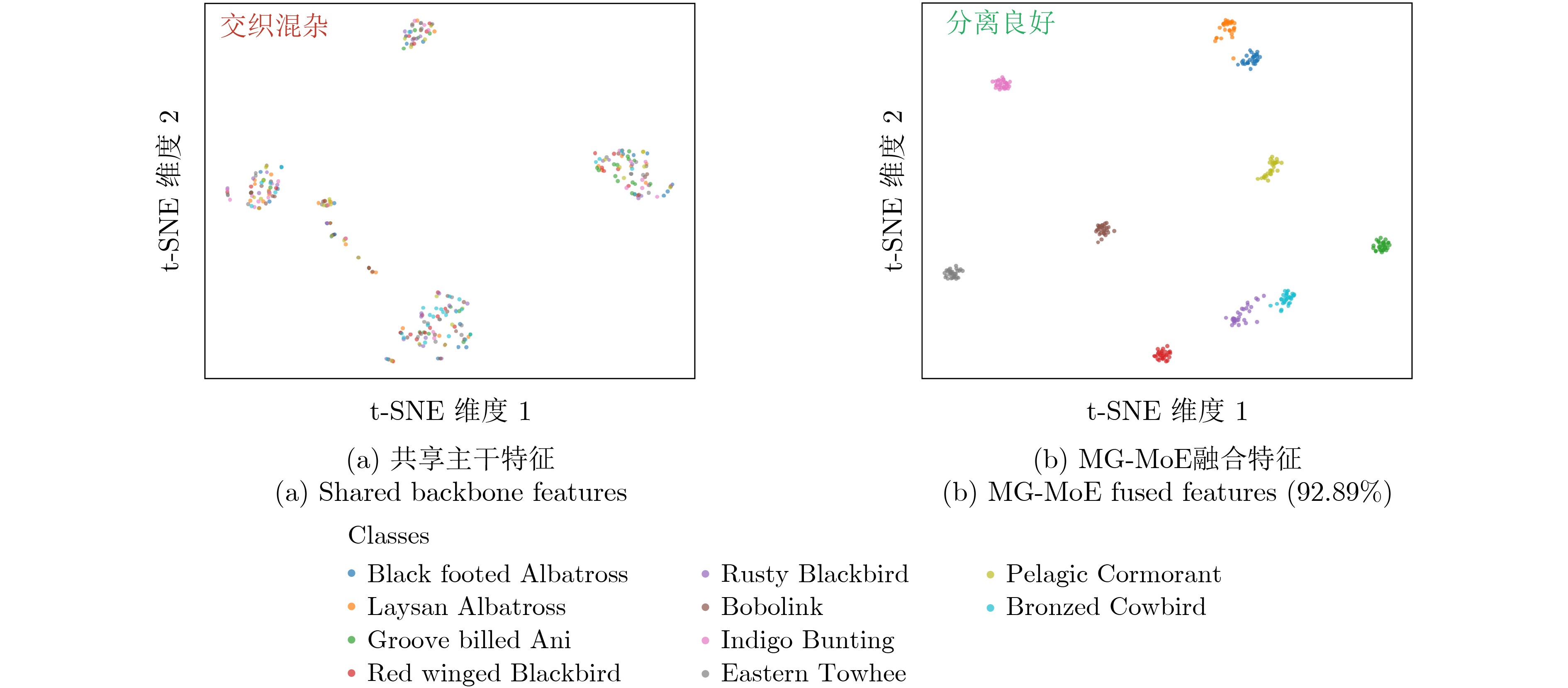
Objective Fine-Grained Image Recognition (FGIR) aims to distinguish visually similar subcategories that differ only in subtle local patterns. It must also remain robust to large intra-class variations caused by pose changes, occlusion, illumination shifts, and complex backgrounds. In real-world scenarios, these challenges are further intensified by long-tailed category distributions. Rare or difficult classes are more likely to overfit spurious contextual cues and suffer from unstable decision boundaries. Therefore, a conditional computation paradigm is needed, in which complementary inductive biases are separated into specialized expert branches and adaptively combined for each sample. This work aims to develop a routed multi-granularity mixture-of-experts framework that improves discriminative performance under controllable inference cost. It also enhances robustness for difficult samples and long-tailed categories through adaptive sparse expert activation. Methods A Multi-Granularity Mixture-of-Experts (MG-MoE) model is proposed. It is a routed ensemble architecture composed of a shared backbone, four heterogeneous experts, and a learnable router that predicts input-conditioned expert weights ( Fig. 2 ). The experts are designed with complementary inductive biases to address key factors in FGIR. MPSA emphasizes global structure and contour-level semantics. PMG captures fine local details through multi-granularity part modeling. TransFG focuses on pose and deformation modeling. PIM improves robustness in cluttered backgrounds through background suppression. To limit interference and reduce unnecessary computation, MG-MoE adopts sparse fusion. Only the Top-K experts, with K=2 by default, contribute to the final prediction during inference. To improve routing stability and generalization, a two-stage optimization strategy is designed. In the first stage, dynamic cluster-level training is performed. A cluster-level soft teacher distribution is constructed from validation-set statistics and imposed through Kullback-Leibler (KL) divergence regularization. This process stabilizes routing behavior and promotes effective expert specialization. In the second stage, residual fine-tuning is conducted. The feature-driven routing mechanism is kept unchanged, while the classification heads of the Top-2 experts associated with each cluster are selectively unfrozen. The router and expert heads are then jointly optimized with grouped learning rates. This design reduces fusion bias and strengthens discrimination for difficult samples and long-tailed categories.Results and Discussions MG-MoE achieves strong performance on standard FGIR benchmarks. On CUB-200-2011, it obtains 92.89% Top-1 accuracy. This result is higher than those of representative expert backbones used individually, including MPSA (91.23%), PIM (91.17%), and TransFG (90.49%). It also outperforms the multi-granularity baseline PMG (88.32%) ( Table 1 ). On the Bird-1445 sampled set, MG-MoE achieves 96.80% Top-1 accuracy and consistently improves over strong baselines (Table 2 ). These results indicate that routed multi-expert specialization remains effective in data-limited and highly similar fine-grained scenarios. The efficiency-accuracy trade-off is summarized in Table 3. With Top-2 sparse routing, MG-MoE reaches 92.89% accuracy with a compute budget of 143.9 GFLOPs. It avoids dense expert activation during inference by selecting only the Top-2 experts for each sample, thereby achieving a favorable balance between accuracy and efficiency. Ablation experiments show that increasing K beyond 2 does not yield consistent gains, which suggests that indiscriminate fusion can dilute discriminative evidence. Top-2 fusion produces the best performance, whereas Top-1 fusion is more sensitive to routing errors and larger K values may introduce noise and reduce accuracy (Table 4 ). The role of expert diversity and composition is also analyzed. Two- and three-expert variants generally underperform the full four-expert configuration, indicating that each inductive bias contributes to different fine-grained difficulty factors. In contrast, adding homogeneous experts without new functional diversity brings diminishing or negative gains, which is consistent with increased routing ambiguity and limited expert complementarity (Table 5 ). These results support the use of a compact set of heterogeneous experts combined with sparse routing. To interpret the learned specialization, category-wise routing statistics are visualized. The expert-category heatmap shows that MPSA receives dominant routing weights across many categories, reflecting the central role of global structure in fine-grained discrimination. PIM and TransFG show higher activation for specific difficult categories, which is consistent with their roles in background suppression and pose and deformation modeling (Fig. 3 ). Finally, t-SNE visualizations illustrate the qualitative effect of expert fusion on class separability. Shared backbone features show stronger inter-class entanglement among visually similar subcategories. In contrast, fused outputs form clearer clusters with better between-class separation and within-class compactness, indicating a more reliable decision space shaped by routed expert aggregation (Fig. 4 ).Conclusions MG-MoE is a multi-granularity routed mixture-of-experts framework for fine-grained recognition. By combining four complementary experts, Top-2 sparse fusion, and a two-stage optimization strategy for stable routing and calibrated fusion, MG-MoE improves recognition accuracy on CUB-200-2011 and the Bird-1445 sampled set. It also provides interpretable evidence of expert specialization ( Table 1 ,Table 2 ,Fig. 3 ,Fig. 4 ). Ablation results confirm that controlled Top-2 fusion and heterogeneous expert design are key to the observed performance gains. Overly dense fusion or homogeneous expert expansion provides limited benefit (Table 4 ,Table 5 ). -
表 2 Bird-
1445 抽测试集(200类)Top-1准确率对比(%)方法 Top-1准确率 相对提升(pp) ResNet-50 88.90 — DCL 89.40 +0.50 CrossX 90.60 +1.70 ConvNeXt 90.70 +1.80 PMG 93.10 +4.20 TransFG 93.60 +4.70 PIM 94.80 +5.90 MPSA 95.10 +6.20 MG-MoE(本文) 96.80 +7.90  下载: 导出CSV
下载: 导出CSV
表 3 多专家模型CUB-200-2011效率分析对比
模型 Acc(%) GFLOPs Params(M) Latency(ms) fps PMG 88.32 37.4 45.1 7.5 133.3 MPSA 91.23 62.7 94.2 18.4 54.3 PIM 91.17 73.2 94.3 7.7 130.5 TransFG 90.49 99.1 87.6 22.1 45.2 MG-MoE(Full) 92.89 275.5 330.9 56.9 17.6 MG-MoE(Top-2) 92.89 143.9 330.9 37 27 注:MG-MoE(Full)指稠密计算全部4个专家、但输出仍采用Top-2融合,故精度与Top-2稀疏版相同,差异仅在计算量。
下载: 导出CSV
表 4 MG-MoE模型Top-K消融实验结果(CUB-200-2011)(%)
模型数量 Top-1 相对最优(pp) Top-1 91.95 –0.94 Top-2 92.89 0 Top-3 92.62 –0.27 Top-4 92.10 –0.79
下载: 导出CSV
表 5 MG-MoE模型不同专家数量Top-2融合消融实验结果(CUB-200-2011)(%)
专家总数 专家组合 Top-1 相对最优(pp) 2 MPSA+TransFG 91.28 –1.61 2 PMG+PIM 91.22 –1.67 2 MPSA+PIM 92.03 –0.86 3 MPSA+TransFG+PIM 92.36 –0.53 3 MPSA+PMG+PIM 92.15 –0.74 3 MPSA+PMG+TransFG 92.01 –0.88 4 MPSA+PMG+TransFG+PIM 92.89 - 5 4专家+1个同质专家 92.78 –0.11 6 4专家+2个同质专家 92.60 –0.29
下载: 导出CSV
-
[1] SUN Hongbo, HE Xiangteng, XU Jinglin, et al. SIM-OFE: Structure information mining and object-aware feature enhancement for fine-grained visual categorization[J]. IEEE Transactions on Image Processing, 2024, 33: 5312–5326. doi: 10.1109/TIP.2024.3459788. [2] YANG Shengying, YANG Xinqi, WU Jianfeng, et al. Significant feature suppression and cross-feature fusion networks for fine-grained visual classification[J]. Scientific Reports, 2024, 14(1): 24051. doi: 10.1038/s41598-024-74654-4. [3] WANG Jiahui, XU Qin, JIANG Bo, et al. Multi-granularity part sampling attention for fine-grained visual classification[J]. IEEE Transactions on Image Processing, 2024, 33: 4529–4542. doi: 10.1109/TIP.2024.3441813. [4] MA Bing, LI Junyi, JIN Zhengbei, et al. Fine-grained image recognition with bio-inspired gradient-aware attention[J]. Biomimetics, 2025, 10(12): 834. doi: 10.3390/biomimetics10120834. [5] CHANG Dongliang, TONG Yujun, DU Ruoyi, et al. An erudite fine-grained visual classification model[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 2023: 7268–7277. doi: 10.1109/CVPR52729.2023.00702. [6] SU J C, CHENG Zezhou, and MAJI S. A realistic evaluation of semi-supervised learning for fine-grained classification[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2021: 12966–12975. doi: 10.1109/CVPR46437.2021.01277. [7] SHU Yangyang, YU Baosheng, XU Haiming, et al. Improving fine-grained visual recognition in low data regimes via self-boosting attention mechanism[C]. The 17th European Conference on Computer Vision, Tel Aviv, Israel, 2022: 449–465. doi: 10.1007/978-3-031-19806-9_26. [8] FEDUS W, ZOPH B, and SHAZEER N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity[J]. Journal of Machine Learning Research, 2022, 23(120): 1–39. [9] JACOBS R A, JORDAN M I, NOWLAN S J, et al. Adaptive mixtures of local experts[J]. Neural Computation, 1991, 3(1): 79–87. doi: 10.1162/neco.1991.3.1.79. [10] SHAZEER N, MIRHOSEINI A, MAZIARZ K, et al. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer[C]. The 5th International Conference on Learning Representations, Toulon, France, 2017. [11] RIQUELME C, PUIGCERVER J, MUSTAFA B, et al. Scaling vision with sparse mixture of experts[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 657. [12] HAN Xumeng, WEI Longhui, DOU Zhiyang, et al. ViMoE: An empirical study of designing vision mixture-of-experts[J]. IEEE Transactions on Image Processing, 2025, 34: 7209–7221. doi: 10.1109/TIP.2025.3626887. [13] ZHU Jinguo, ZHU Xizhou, WANG Wenhai, et al. Uni-perceiver-MoE: Learning sparse generalist models with conditional MoEs[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 193. [14] MUSTAFA B, RIQUELME C, PUIGCERVER J, et al. Multimodal contrastive learning with LIMoE: The language-image mixture of experts[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 695. [15] SHEN Leyang, CHEN Gongwei, SHAO Rui, et al. MoME: Mixture of multimodal experts for generalist multimodal large language models[C]. The 38th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2024: 1330. [16] ZHENG Haiyang, PU Nan, LI Wenjing, et al. Generalized fine-grained category discovery with multi-granularity conceptual experts[J]. arXiv preprint arXiv: 2509.26227, 2025. [17] HE Ju, CHEN Jieneng, LIU Shuai, et al. TransFG: A transformer architecture for fine-grained recognition[C]. The 36th AAAI Conference on Artificial Intelligence, 2022: 852–860. doi: 10.1609/aaai.v36i1.19967. [18] DU Ruoyi, CHANG Dongliang, BHUNIA A K, et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 153–168. doi: 10.1007/978-3-030-58565-5_10. [19] CHOU P Y, LIN C H, and KAO W C. A novel plug-in module for fine-grained visual classification[J]. arXiv preprint arXiv: 2202.03822, 2022. [20] XU Zhikang, YUE Xiaodong, LV Ying, et al. Trusted fine-grained image classification through hierarchical evidence fusion[C]. The 37th AAAI Conference on Artificial Intelligence, Washington, USA, 2023: 10657–10665. doi: 10.1609/aaai.v37i9.26265. [21] LEPIKHIN D, LEE H, XU Yuanzhong, et al. GShard: Scaling giant models with conditional computation and automatic sharding[C]. The 9th International Conference on Learning Representations, Austria, 2021. [22] GURURANGAN S, LEWIS M, HOLTZMAN A, et al. DEMix layers: Disentangling domains for modular language modeling[C]. The 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, United States, 2022: 5557–5576. doi: 10.18653/v1/2022.naacl-main.407. [23] RAJBHANDARI S, LI Conglong, YAO Zhewei, et al. DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale[C]. The 39th International Conference on Machine Learning, Baltimore, USA, 2022: 18332–18346. [24] WANG Lean, GAO Huazuo, ZHAO Chenggang, et al. Auxiliary-loss-free load balancing strategy for mixture-of-experts[J]. arXiv preprint arXiv: 2408.15664, 2024. [25] ROLLER S, SUKHBAATAR S, SZLAM A, et al. Hash layers for large sparse models[C]. The 35th International Conference on Neural Information Processing Systems, 2021: 1343. [26] JIANG A Q, SABLAYROLLES A, ROUX A, et al. Mixtral of experts[J]. arXiv preprint arXiv: 2401.04088, 2024. [27] DAI Damai, DENG Chengqi, ZHAO Chenggang, et al. DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models[C]. The 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 2024. doi: 10.18653/v1/2024.acl-long.70. [28] CHEN Tianlong, CHEN Xuxi, DU Xianzhi, et al. AdaMV-MoE: Adaptive multi-task vision mixture-of-experts[C]. 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 17346–17357. doi: 10.1109/ICCV51070.2023.01591. [29] 王洪昌, 咸凤羽, 谢子晖, 等. BIRD1445: 面向生态监测的大规模多模态鸟类数据集[J]. 电子与信息学报, 2026, 48(2): 873–888. doi: 10.11999/JEIT250647.WANG Hongchang, XIAN Fengyu, XIE Zihui, et al. BIRD1445: Large-scale multimodal bird dataset for ecological monitoring[J]. Journal of Electronics & Information Technology, 2026, 48(2): 873–888. doi: 10.11999/JEIT250647. [30] CHEN Yue, BAI Yalong, ZHANG Wei, et al. Destruction and construction learning for fine-grained image recognition[C]. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019: 5157–5166. doi: 10.1109/CVPR.2019.00530. [31] LUO Wei, YANG Xitong, MO Xianjie, et al. Cross-x learning for fine-grained visual categorization[C]. 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 2019: 8242–8251. doi: 10.1109/ICCV.2019.00833. [32] LIU Zhuang, MAO Hanzi, WU Chaoyuan, et al. A ConvNet for the 2020s[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, USA, 2022: 11976–11986. doi: 10.1109/CVPR52688.2022.01167. [33] HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]. 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 770–778. doi: 10.1109/CVPR.2016.90. -


 下载:
下载:



图(4) / 表(5)
计量
- 文章访问数: 188
- HTML全文浏览量: 81
- PDF下载量: 12
- 被引次数: 0
