

LLMA-GCN: A Semantically Enhanced Hierarchical Spatiotemporal Graph Convolutional Network for Skeleton-based Action Recognition
-
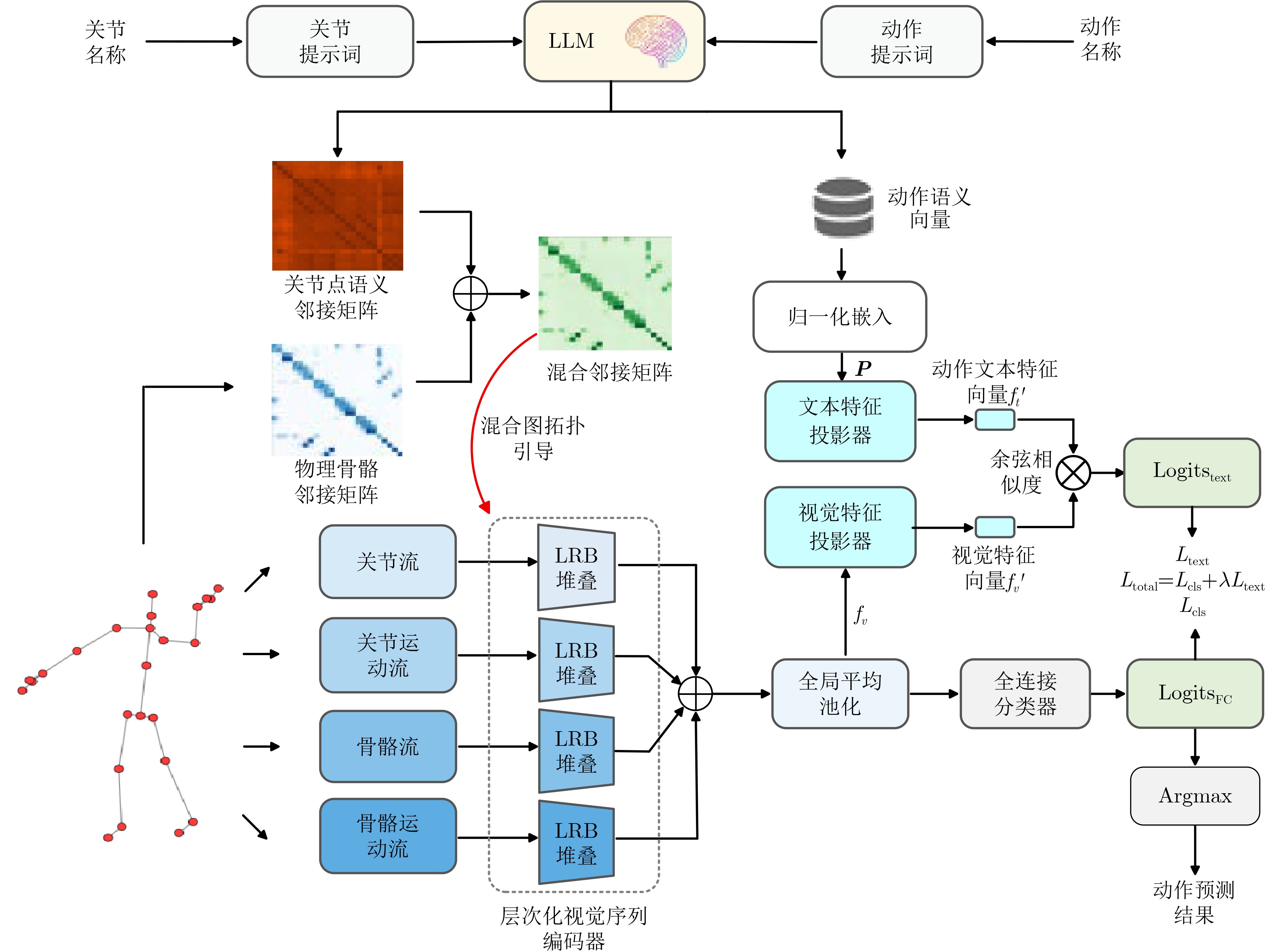
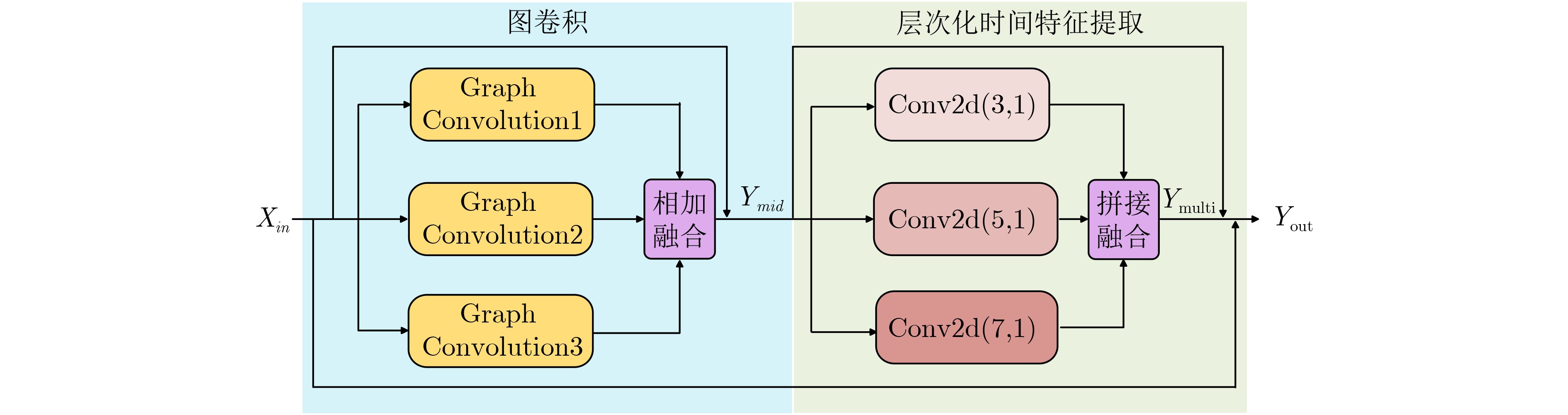
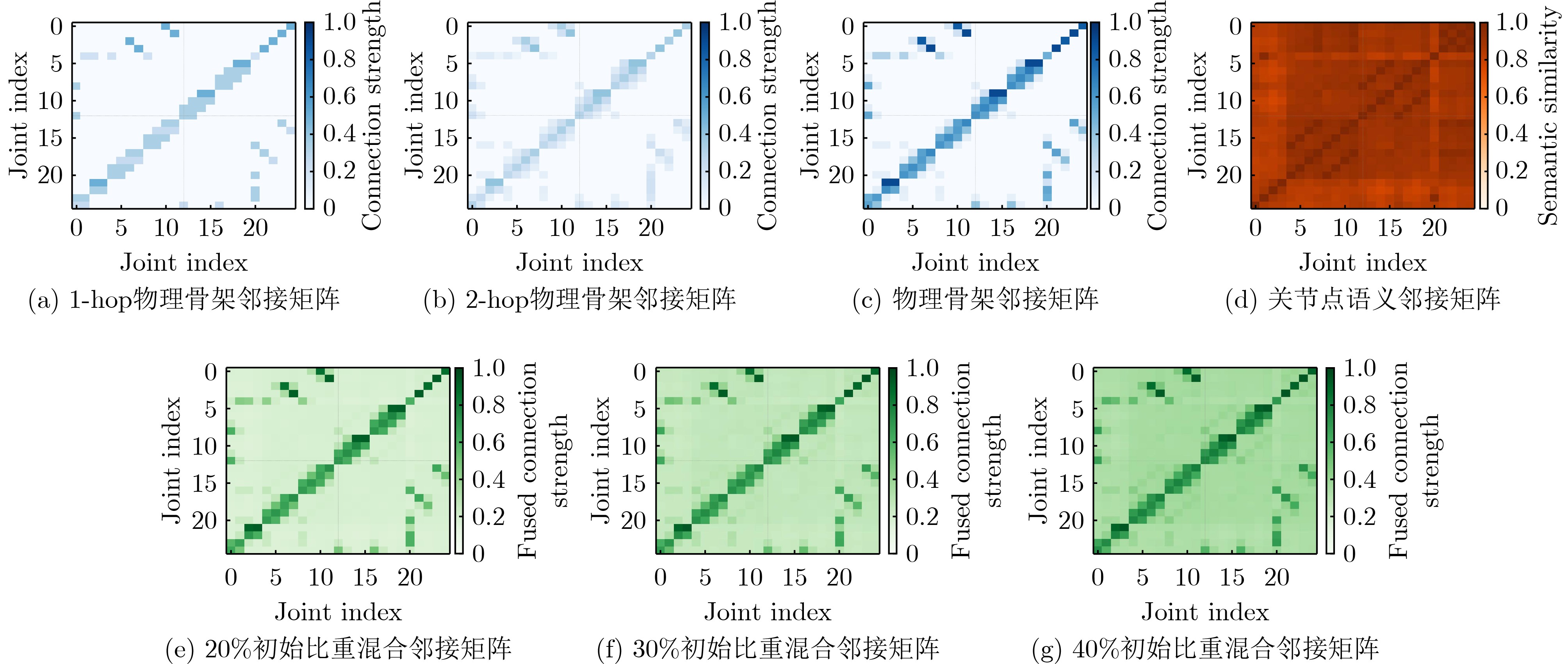
摘要: 针对当前骨架动作识别方法在引入大语言模型(LLM)时存在的语义引导与空间拓扑学习脱节、时间建模缺乏层次化语义支持、传统分类范式泛化能力不足的3大问题,该文提出一种基于LLM增强的骨架动作识别新方法(LLMA-GCN)。该方法首先提出一种基于LLM的混合图拓扑学习策略,将物理骨架结构先验知识与LLM提取的动作语义信息深度融合以指导空间建模;其次,将混合图拓扑学习策略与层次化视觉序列编码器相结合,通过设计的LLM精炼块实现语义引导下的多尺度时空特征提取;最后,构建了LLM驱动的文本原型引导决策学习机制,实现语义引导的视觉-文本对齐和分类决策联合学习,从而提升模型整体性能。在NTU RGB+D 60, NTU RGB+D 120以及PKU-MMD公开数据集上进行了大量对比实验及消融实验,证明了新方法的有效性和先进性。Abstract:
Objective Current methods that introduce the Large Language Model (LLM) into skeleton-based action recognition face three main limitations. Semantic guidance remains decoupled from spatial topology learning, temporal modeling lacks hierarchical semantic support, and traditional classification paradigms have limited generalization. To address these issues, this paper proposes LLMA-GCN, a semantically enhanced graph convolutional framework. The proposed framework integrates LLM-derived semantic prior knowledge with graph convolution to improve spatiotemporal feature learning and action classification. Methods LLMA-GCN uses visual skeleton data and semantic inputs in a dual-branch framework. Frozen LLMs and prompt engineering are used to precompute the joint semantic adjacency matrix and action text prototypes. The framework consists of three main components: an LLM-based hybrid graph topology learning strategy, a hierarchical visual sequence encoder based on the LLM Refinement Block (LRB), and an action text-prototype-guided decision learning mechanism. These components enable semantic guidance in graph topology learning, hierarchical spatiotemporal feature extraction, and visual-text alignment. Results and Discussions Experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD I show that LLMA-GCN achieves competitive or superior performance compared with state-of-the-art methods. Ablation studies confirm the key roles of the hybrid graph topology, the LRB, and the action text-prototype-guided decision learning mechanism. Model-complexity analysis further indicates the potential of the proposed framework for practical application. Conclusions By fusing the joint semantic adjacency matrix and the physical adjacency matrix, LLMA-GCN enables action semantics to directly guide graph convolution and improves semantic perception. The LRB embeds semantic information into hierarchical spatiotemporal feature extraction, which strengthens the modeling of complex actions. The action text-prototype-guided decision learning mechanism further shifts skeleton-based action recognition from purely visual classification to text-prototype-guided visual-text alignment. Overall, LLMA-GCN provides a robust and generalizable framework for skeleton-based action recognition through deep fusion of visual and semantic features. -
表 1 动作文本原型提示词配置
构建维度 提示词模板 侧重点 描述性 "Describe the action '{action name}': A person is performing {action name}." 动作的执行过程与动态流程 观察性 "What does '{action name}' look like? Someone is doing {action name}." 动作的视觉表征与外观特征 陈述性 "Action description for '{action name}': The person is {action name}." 动作的定义与状态  下载: 导出CSV
下载: 导出CSV
表 2 3个公开数据集上的对比实验结果(%)
动作识别模型 NTU RGB+D 60 NTU RGB+D 120 PKU-MMDⅠ X-sub X-view X-sub X-set X-sub X-view ST-GCN[8](2018) 81.5 88.3 70.7 73.2 - - DS-STGCN[10](2024) 93.2 97.5 89.4 91.2 - - DSDC-GCN[22](2024) 93.0 97.1 89.9 90.6 97.6 - STA-GCN-Transformer[9](2025) 86.0 91.9 - - - - BlockGCN[23](2024) 93.1 97.0 90.3 91.5 - - SMS-GCN[24](2025) 92.6 96.9 89.3 90.7 - - TSGCNeXt[25](2025) 93.2 97.0 90.2 91.7 - - GAP+CTR-GCN[11](2023) 92.9 97.0 89.9 91.1 - - MICA[12](2025) 85.3 90.6 77.4 76.0 93.0 - CEPCLR[13](2025) 86.9 91.3 80.5 81.9 95.3 - HS-Rep[14](2025) 87.8 93.7 78.9 82.2 - - LLM-AR[15](2024) 95.0 98.4 88.7 91.5 - - KEHCN[26](2025) 93.5 97.3 90.4 91.8 - - MMNet[27](2025) 96.0 98.8 92.9 94.4 97.4 98.6 MMINet[28](2022) 94.3 96.5 91.7 92.6 93.6 94.2 TBCNet[29](2025) 96.3 97.1 91.5 92.9 93.8 93.6 LLMA-GCN 96.5 97.5 91.8 92.5 98.3 97.4
下载: 导出CSV
表 3 LLMA-GCN框架消融实验结果(%)
实验设置 M S T X-sub 实验设置 M S T X-sub B × × × 90.8 B+M+S √ √ × 97.0 B+M √ × × 93.9 B+M+T √ × √ 97.3 B+S × √ × 96.8 B+S+T × √ √ 97.8 B+T × × √ 94.3 LLMA-GCN √ √ √ 98.3
下载: 导出CSV
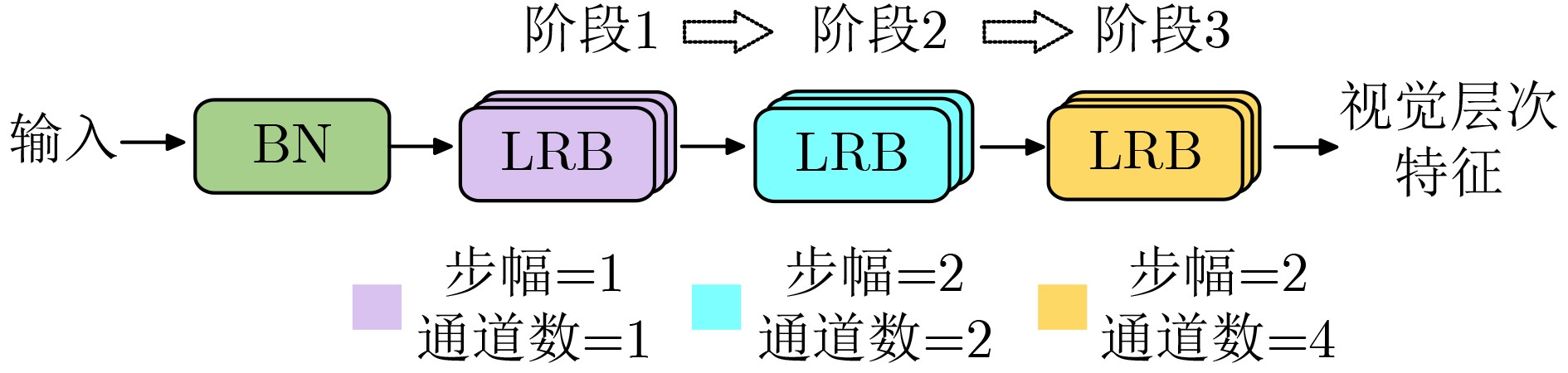
表 5 层次化时间特征提取模块细粒度消融实验结果(%)
具体设置 3 5 7 9 11 (3,5) (3,7) (5,7) (3,5,7) (5,7,9) (3,5,9) (3,7,11) 准确率 94.56 95.12 95.23 94.23 94.05 94.23 94.93 95.19 98.30 95.04 94.93 93.57
下载: 导出CSV
-
[1] GODASE V V. Edge AI for smart surveillance: Real-time human activity recognition on low-power devices[J]. International Journal of AI and Machine Learning Innovations in Electronics and Communication Technology, 2025, 1(1): 29–46. doi: 10.2139/ssrn.5383804. [2] 孙中华, 吴双, 贾克斌, 等. 基于对比学习的动作识别研究综述[J]. 电子与信息学报, 2025, 47(8): 2473–2485. doi: 10.11999/JEIT250131.SUN Zhonghua, WU Shuang, JIA Kebin, et al. A review on action recognition based on contrastive learning[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2473–2485. doi: 10.11999/JEIT250131. [3] SUN Zehua, KE Qiuhong, RAHMANI H, et al. Human action recognition from various data modalities: A review[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45(3): 3200–3225. doi: 10.1109/TPAMI.2022.3183112. [4] ZHANG Yumin and WANG Yanyong. A comprehensive survey on RGB-D-based human action recognition: Algorithms, datasets, and popular applications[J]. EURASIP Journal on Image and Video Processing, 2025, 2025(1): 15. doi: 10.1186/s13640–025-00677–0. [5] XIA Lu, CHEN C C, and AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 20–27. doi: 10.1109/CVPRW.2012.6239233. [6] HUSSEIN M E, TORKI M, GOWAYYED M A, et al. Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations[C]. The Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 2013: 2466–2472. [7] KE Qiuhong, BENNAMOUN M, AN Senjian, et al. A new representation of skeleton sequences for 3D action recognition[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 4570–4579. doi: 10.1109/CVPR.2017.486. [8] YAN Sijie, XIONG Yuanjun, and LIN Dahua. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]. The 32nd AAAI Conference on Artificial Intelligence, New Orleans, USA, 2018. doi: 10.1609/aaai.v32i1.12328. [9] 韩宗旺, 杨涵, 吴世青, 等. 时空自适应图卷积与Transformer结合的动作识别网络[J]. 电子与信息学报, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551.HAN Zongwang, YANG Han, WU Shiqing, et al. Action recognition network combining spatio-temporal adaptive graph convolution and transformer[J]. Journal of Electronics & Information Technology, 2024, 46(6): 2587–2595. doi: 10.11999/JEIT230551. [10] XIE Jianyang, MENG Yanda, ZHAO Yitian, et al. Dynamic semantic-based spatial-temporal graph convolution network for skeleton-based human action recognition[J]. IEEE Transactions on Image Processing, 2024, 33: 6691–6704. doi: 10.1109/TIP.2024.3497837. [11] XIANG Wangmeng, LI Chao, ZHOU Yuxuan, et al. Generative action description prompts for skeleton-based action recognition[C]. The IEEE/CVF International Conference on Computer Vision, Paris, France, 2023: 10242–10251. doi: 10.1109/ICCV51070.2023.00943. [12] XIN Wentian, TENG Yue, ZHANG Jikang, et al. Modeling the internal and contextual attention for self-supervised skeleton-based action recognition[J]. Sensors, 2025, 25(21): 6532. doi: 10.3390/s25216532. [13] XIN Wentian, LIU Yi, FU Xianping, et al. LLMs encounter critical elements prompts: Semantically guided partial supervision skeleton-based action recognition[J]. IEEE Sensors Journal, 2025, 25(10): 17350–17363. doi: 10.1109/JSEN.2025.3556580. [14] WANG Hongsong, MA Xiaoyan, KUANG Jidong, et al. Heterogeneous skeleton-based action representation learning[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, 2025: 19154–19164. doi: 10.1109/CVPR52734.2025.01784. [15] QU Haoxuan, CAI Yujun, and LIU Jun. LLMs are good action recognizers[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 18395–18406. doi: 10.1109/CVPR52733.2024.01741. [16] YAN Tingbing, ZENG Wenzheng, XIAO Yang, et al. CrossGLG: LLM guides one-shot skeleton-based 3D action recognition in a cross-level manner[C]. The 18th European Conference on Computer Vision, Milan, Italy, 2024: 113–131. doi: 10.1007/978-3-031-72661-3_7. [17] REIMERS N and GUREVYCH I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 2019: 3982–3992. doi: 10.18653/v1/D19-1410. [18] SHAHROUDY A, LIU Jun, NG T T, et al. NTU RGB+D: A large scale dataset for 3D human activity analysis[C]. The IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1010–1019. doi: 10.1109/CVPR.2016.115. [19] LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873. [20] LIU Chunhui, HU Yueyu, LI Yanghao, et al. PKU-MMD: A large scale benchmark for continuous multi-modal human action understanding[C]. The Workshop on Visual Analysis in Smart and Connected Communities, Mountain View, USA, 2017: 1–8. doi: 10.1145/3132734.3132739. [21] YANG An, LI Anfeng, YANG Baosong, et al. Qwen3 technical report[J]. arXiv preprint arXiv: 2505.09388, 2025. [22] ZHUANG Tianming, QIN Zhen, DING Yi, et al. DSDC-GCN: Decoupled static-dynamic co-occurrence graph convolutional networks for skeleton-based action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2025, 35(3): 2101–2117. doi: 10.1109/TCSVT.2024.3491133. [23] ZHOU Yuxuan, YAN Xudong, CHENG Zhiqi, et al. BlockGCN: Redefine topology awareness for skeleton-based action recognition[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 2049–2058. doi: 10.1109/CVPR52733.2024.00200. [24] 曹毅, 李杰, 叶培涛, 等. 利用可选择多尺度图卷积网络的骨架行为识别[J]. 电子与信息学报, 2025, 47(3): 839–849. doi: 10.11999/JEIT240702.CAO Yi, LI Jie, YE Peitao, et al. Skeleton-based action recognition with selective multi-scale graph convolutional network[J]. Journal of Electronics & Information Technology, 2025, 47(3): 839–849. doi: 10.11999/JEIT240702. [25] LIU Dongjingdian, LI Xiaomeng, CAI Zijie, et al. TSGCNeXt: Dynamic-static multi-graph convolution for efficient skeleton-based action recognition[J]. Expert Systems with Applications, 2025, 276: 127081. doi: 10.1016/j.eswa.2025.127081. [26] MA Nan, SUN Beining, HAN Yiheng, et al. Kinematic enhanced hypergraph convolutional network for skeleton-based human action recognition with LLM training guides[C]. The 33rd ACM International Conference on Multimedia, Dublin, Ireland, 2025: 1920–1928. doi: 10.1145/3746027.3755538. [27] YU B X B, LIU Yan, ZHANG Xiang, et al. MMNet: A model-based multimodal network for human action recognition in RGB-D videos[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(3): 3522–3538. doi: 10.1109/TPAMI.2022.3177813. [28] CHENG Qin, LIU Zhen, REN Ziliang, et al. Spatial-temporal information aggregation and cross-modality interactive learning for RGB-D-based human action recognition[J]. IEEE Access, 2022, 10: 104190–104201. doi: 10.1109/ACCESS.2022.3201227. [29] YANG Yingyuan, LIANG Guoyuan, WANG Can, et al. Trunk-branch contrastive network with multi-view deformable aggregation for multi-view action recognition[J]. Pattern Recognition, 2026, 169: 111923. doi: 10.1016/j.patcog.2025.111923. -



图(4) / 表(6)
计量
- 文章访问数: 74
- HTML全文浏览量: 24
- PDF下载量: 13
- 被引次数: 0
 下载:
下载:
