

A Hierarchical Cross-layer Closed-loop Learning Framework andCoordination Mechanism for Complex Multi-agent Systems
-
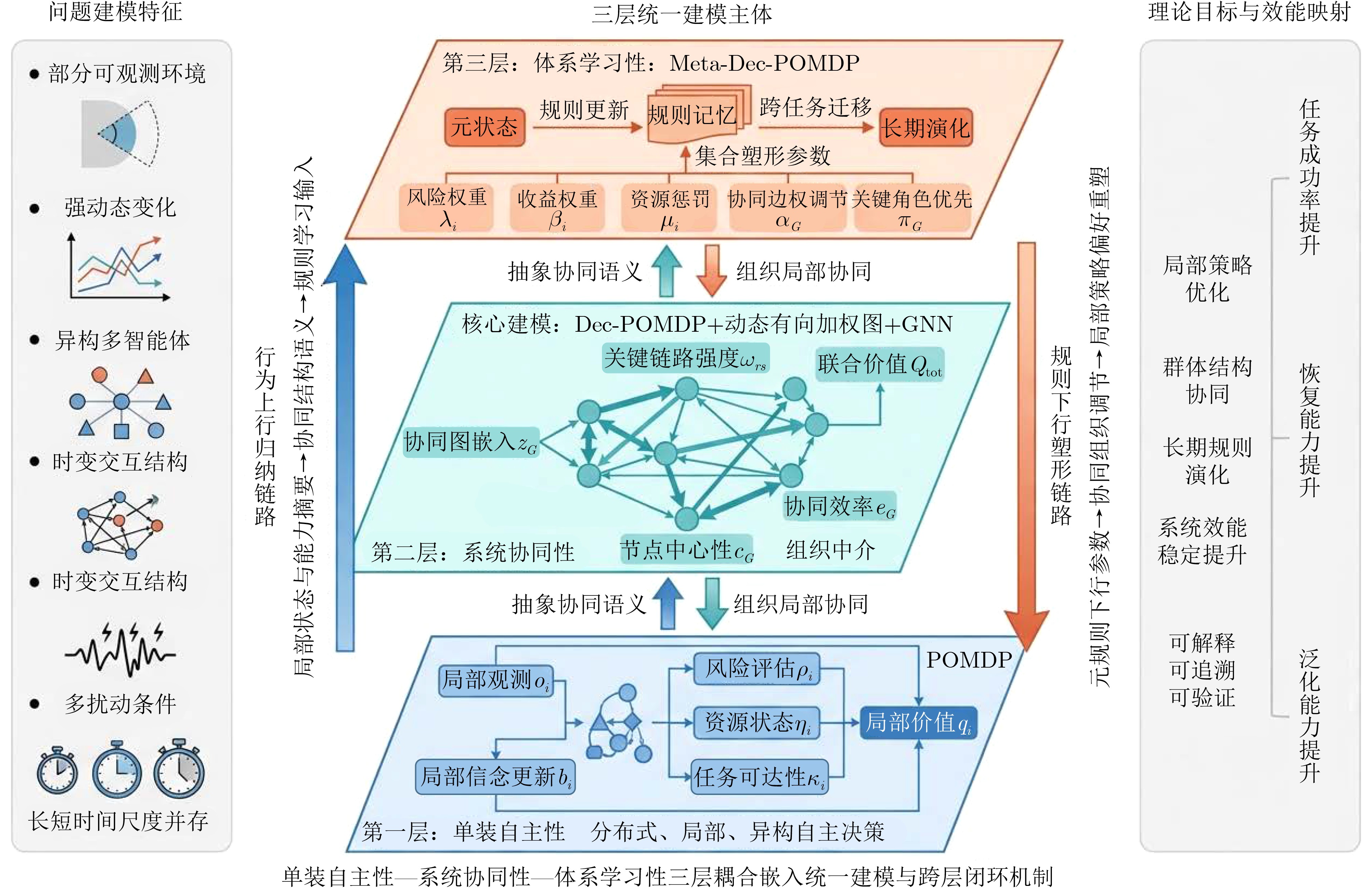
摘要: 面向复杂动态环境下智能化装备体系效能评估中存在的层级割裂、协同机理弱显式和长期适应能力难表征等问题,该文围绕单装自主性、系统协同性和体系学习性,提出面向复杂多智能体系统的跨层规则演化与协同优化框架。首先,在单装层采用部分可观测马尔可夫决策过程(POMDP)描述异构个体在部分可观测条件下的局部感知、风险评估与自主决策过程;其次,在系统层构建分布式部分可观测马尔可夫决策过程(Dec-POMDP)与动态有向加权图结合的协同建模框架,并引入图神经网络(GNN)刻画多智能体交互结构、联合价值与关键支撑链路;进一步,在体系层构建元分布式部分可观测马尔可夫决策过程(Meta-Dec-POMDP)规则演化模型,通过元状态、规则记忆与任务上下文条件化设计长期认知演化的收敛趋势、多样性保持与振荡抑制机制,实现跨任务学习与长期自适应。在此基础上,设计了行为上行归纳—规则下行塑形的跨层闭环机制,实现局部状态特征、协同结构语义与规则参数之间的复用传递和统一约束。仿真实验表明,所提完整闭环模型在基准及多类非平稳场景下均优于对比模型。研究表明,跨层闭环并非附加结构,而是将局部学习优势稳定转化为整体效能提升的关键机制,可为复杂多智能体系统的效能评估与自适应协同优化提供理论依据和方法支撑。
-
关键词:
- 多智能体系统 /
- 分层演化学习 /
- 部分可观测马尔可夫决策过程 /
- 分布式部分可观测马尔可夫决策过程 /
- 图神经网络 /
- 体系效能评估
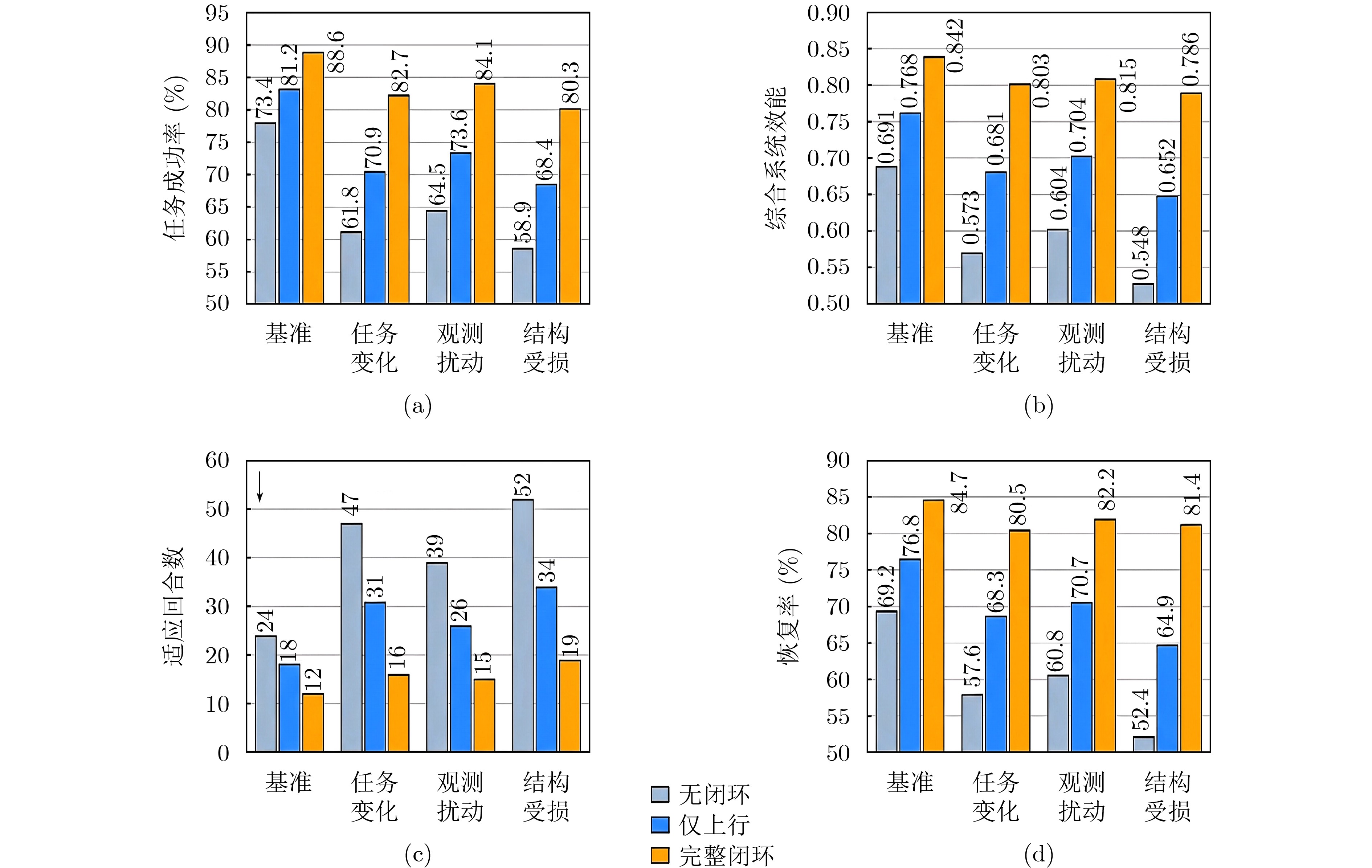
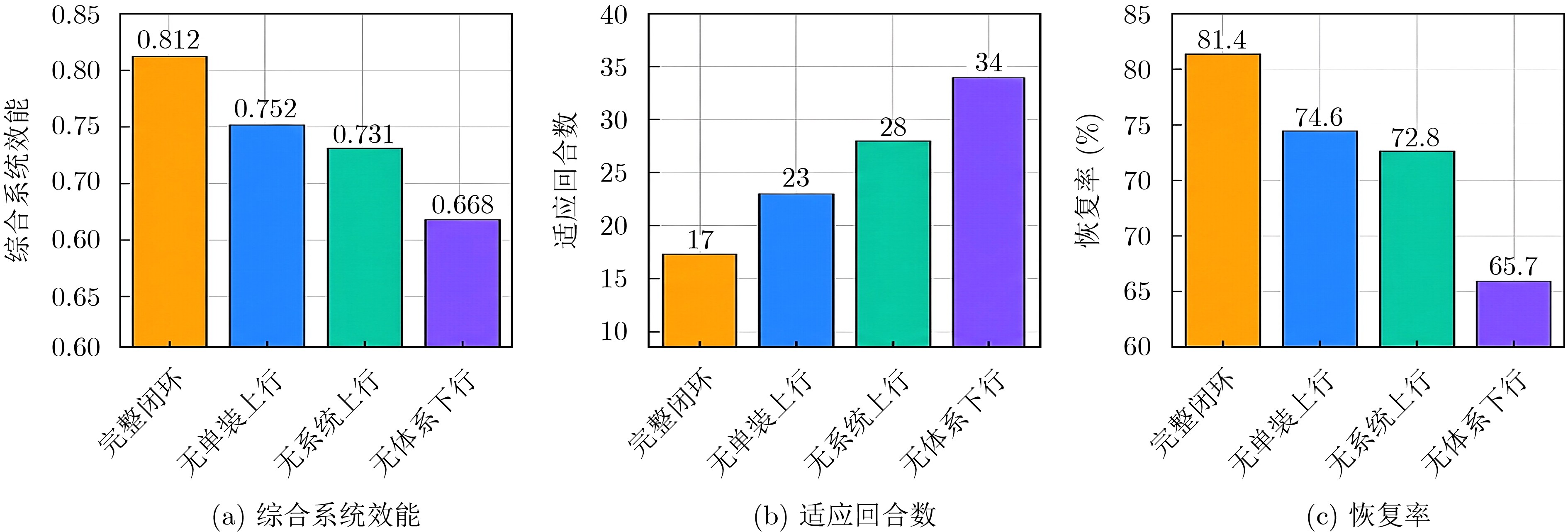
Abstract:Objective Complex Multi-Agent Systems (MAS) in dynamic and uncertain environments face challenges in unified modeling, adaptive coordination, and interpretable effectiveness evaluation. Existing methods usually address individual decision-making, inter-agent coordination, and high-level policy evolution separately. This separation leads to fragmented decision chains and weak cross-layer coupling. It also makes it difficult to explain how local learning gains are transformed into global effectiveness improvements under mission variation, observation disturbance, and structural damage. To address this issue, a Hierarchical Cross-layer Closed-loop Learning (HCCL) framework is proposed. The framework couples individual autonomy, system-level coordination, and system-of-systems learning to build a computable path from local policy optimization to overall effectiveness enhancement. Methods HCCL adopts a unified three-layer architecture. At the individual autonomy layer, each agent is modeled as a Partially Observable Markov Decision Process (POMDP) to describe decision-making under partial observability. At the system-level coordination layer, multi-agent coordination is formulated as a Decentralized Partially Observable Markov Decision Process (Dec-POMDP) and represented by a dynamic directed weighted coordination graph. A Graph Neural Network (GNN) is used to encode interaction dependencies, structural coupling, and joint value information. At the system-of-systems learning layer, a Meta-Decentralized Partially Observable Markov Decision Process (Meta-Dec-POMDP) is established to describe task-context adaptation and rule evolution. A cross-layer closed-loop mechanism is further designed. In the bottom-up behavior induction pathway, local state and capability features are aggregated into graph-level structural representations and supplied to the upper rule-learning process. In the top-down rule-shaping pathway, learned high-level rules are converted into control parameters and fed back to lower layers to regulate local policies and coordination relationships. Simulations are conducted under baseline, mission-variation, observation-disturbance, and structural-damage scenarios. The full HCCL model is compared with a non-closed-loop model and an upward-induction-only model. Interface ablation studies are also performed to analyze the contributions of cross-layer feature reporting, structural induction, and rule shaping. Results and Discussions The full HCCL model consistently outperforms the comparison models and ablated variants. In the baseline scenario, it achieves a task success rate of 88.6% and a comprehensive system effectiveness of 0.842. Under mission variation, it reduces the adaptation process to 16±2 rounds. Under structural damage, it achieves a recovery rate of 81.4% and restores coordination-structure stability to 0.742 within 20 steps. These results indicate that HCCL improves task performance, adaptation speed, and structural recovery. Ablation results show that removing any cross-layer interface reduces performance, while removing the top-down rule-shaping pathway causes the largest loss. This result indicates that upward structural perception alone is insufficient for sustained system-level improvement. The effectiveness gain mainly arises from closed-loop coupling between bottom-up behavior induction and top-down rule shaping, rather than from simple hierarchical stacking. Conclusions The HCCL framework is proposed for complex MAS by integrating POMDP-based individual autonomy modeling, Dec-POMDP- and graph-based coordination modeling, and Meta-Dec-POMDP-based rule evolution. Through bottom-up behavior induction and top-down rule shaping, HCCL provides a computable and interpretable path from local learning to overall effectiveness enhancement. Experimental results verify its advantages in task completion, adaptation, recovery, and coordination stability under multiple disturbances. Future work will focus on larger-scale heterogeneous systems, communication-constrained networking, online continual adaptation, and data-driven evaluation in realistic environments. -
[1] ANNE T, SYRKIS N, ELHOSNI M, et al. Harnessing language for coordination: A framework and benchmark for LLM-driven multi-agent control[EB/OL]. https://arxiv.org/abs/2412.11761, 2024. [2] KOIFMAN Y, BAREL A, and BRUCKSTEIN A M. Distributed and decentralized task allocation for heterogeneous swarms[J]. Artificial Life and Robotics, 2026, 31(1): 302–316. doi: 10.1007/s10015-025-01104-3. [3] MARTIN F, KIM H J, SILKA L, et al. Artbotics: Challenges and opportunities for multi-disciplinary, community-based learning in computer science, robotics, and art[J]. 2007. [4] MEULEMANS A, KOBAYASHI S, VON OSWALD J, et al. Multi-agent cooperation through learning-aware policy gradients[C]. The 13th International Conference on Learning Representations, Singapore, Singapore, 2025. [5] KHUSHIYANT. Emergent collective memory in decentralized multi-agent AI systems[EB/OL]. https://arxiv.org/abs/2512.10166, 2025. [6] HADY M A, HU Siyi, PRATAMA M, et al. Multi-agent reinforcement learning for resources allocation optimization: A survey[J]. Artificial Intelligence Review, 2025, 58(11): 354. doi: 10.1007/s10462-025-11340-5. [7] ZHU Changxi, DASTANI M, and WANG Shihan. A survey of multi-agent deep reinforcement learning with communication[J]. Autonomous Agents and Multi-Agent Systems, 2024, 38(1): 4. doi: 10.1007/s10458-023-09633-6. [8] GUPTA N, HARE J Z, MILZMAN J, et al. Action-graph policies: Learning action co-dependencies in multi-agent reinforcement learning[EB/OL]. https://arxiv.org/abs/2602.17009, 2026. [9] REN Tianyu, YAO Xuan, LI Yang, et al. Bottom-up reputation promotes cooperation with multi-agent reinforcement learning[C]. The 24th International Conference on Autonomous Agents and Multiagent Systems, Detroit, USA, 2025: 1745–1754. doi: 10.65109/fdxo1013. [10] HU Tianmeng, LUO Biao, YANG Chunhua, et al. MO-MIX: Multi-objective multi-agent cooperative decision-making with deep reinforcement learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(10): 12098–12112. doi: 10.1109/tpami.2023.3283537. [11] 鲁旭涛, 智超群, 张丽娜, 等. 应急搜索UAV集群协同任务规划策略[J]. 电子与信息学报, 2022, 44(1): 187–194. doi: 10.11999/JEIT210219.LU Xutao, ZHI Chaoqun, ZHANG Lina, et al. Multi-UAV regional patrol mission planning strategy[J]. Journal of Electronics & Information Technology, 2022, 44(1): 187–194. doi: 10.11999/JEIT210219. [12] PAOLO G, BENECHEHAB A, CHERKAOUI H, et al. TAG: A decentralized framework for multi-agent hierarchical reinforcement learning[EB/OL]. https://arxiv.org/abs/2502.15425, 2025. [13] LIU Biyuan, XU Daigang, JIANG Lei, et al. Modeling the mental world for embodied AI: A comprehensive review[EB/OL]. https://arxiv.org/abs/2601.02378, 2025. [14] 徐俊杰, 李斌, 杨敬松. 禁飞区约束下的无人机可重构智能表面辅助通信网络性能优化[J]. 电子与信息学报, 2026, 48(2): 743–751. doi: 10.11999/JEIT250681.XU Junjie, LI Bin, and YANG Jingsong. Performance optimization of UAV-RIS-assisted communication networks under no-fly zone constraints[J]. Journal of Electronics & Information Technology, 2026, 48(2): 743–751. doi: 10.11999/JEIT250681. [15] NATH S, PERIDIS C, BENJAMIN E, et al. Policy search, retrieval, and composition via task similarity in collaborative agentic systems[C]. The 40th AAAI Conference on Artificial Intelligence, Singapore, Singapore, 2026: 24504–24512. doi: 10.1609/aaai.v40i29.39633. [16] 唐伦, 蒲昊, 汪智平, 等. 基于注意力机制ConvLSTM的UAV节能预部署策略[J]. 电子与信息学报, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368.TANG Lun, PU Hao, WANG Zhiping, et al. Energy-efficient predictive deployment strategy of UAVs based on ConvLSTM with attention mechanism[J]. Journal of Electronics & Information Technology, 2022, 44(3): 960–968. doi: 10.11999/JEIT211368. [17] LIU Yanli, FENG Haonan, and HATZIARGYRIOU N D. Multi-stage collaborative resilient enhancement strategy for coupling faults in distribution cyber physical systems[J]. Applied Energy, 2023, 348: 121560. doi: 10.1016/j.apenergy.2023.121560. [18] DEVLIN J and CHANG M W. AI-assisted pipeline for dynamic generation of trustworthy health supplement content at scale[EB/OL]. https://openalex.org/works/w2896457183, 2018. [19] ZHAI Lidong, QIU Zhijie, ZHANG Lvyang, et al. The Athenian academy: A seven-layer architecture model for multi-agent systems[EB/OL]. https://arxiv.org/abs/2504.12735, 2025. [20] BARONI M, DESSI R, and LAZARIDOU A. Emergent language-based coordination in deep multi-agent systems[C]. 2022 Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts, Abu Dubai, UAE, 2022: 11–16. doi: 10.18653/v1/2022.emnlp-tutorials.3. -

 下载:
下载:


图(3)
计量
- 文章访问数: 168
- HTML全文浏览量: 69
- PDF下载量: 28
- 被引次数: 0
