

A Multimodal Sentiment Analysis Model with Multi-source Knowledge guided Visual Confidence Perception
-
摘要: 针对多模态情感分析中图文不一致、视觉模态置信度低、模态贡献不均衡等问题,该文提出一种多源知识引导的视觉置信度感知模型(MKVP)。首先,通过多源知识引导构建视觉置信度感知(VCP)模块,利用文本句法与细粒度属性先验对视觉特征进行质量评估,有效过滤图像中受环境干扰的冗余信息,并引导其特征分布。其次,为避免模型对文本模态产生过度依赖并平衡模态贡献,设计双流并行交互模块,通过跨模态注意力机制促进图文特征的深层对等交互,强化图像特征对文本语义的补充与修正作用。最后,引入全局门控融合机制,根据各模态的全局贡献程度动态调节融合权重,实现从单模态主导向多模态均衡协同决策的转变。在MVSA-Single, MVSA-Multiple及HFM数据集上识别准确率和F1分数分别达到了77.56%和76.70%、72.72%和70.66%、87.26%和86.78%,对比基线模型识别准确率和F1分数分别提升2.45%和3.68%、2.19%和2.21%、1.83%和1.91%。说明该模型能有效挖掘样本中图文之间更深层次的情感表达。Abstract:
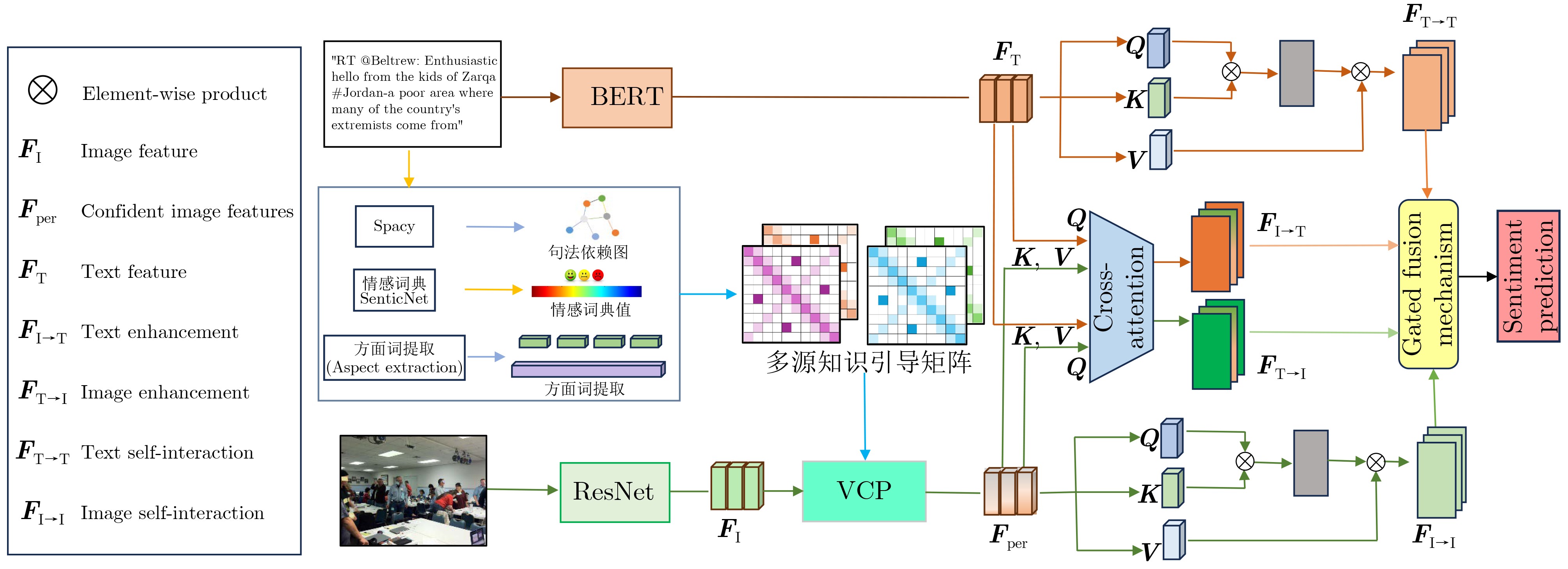
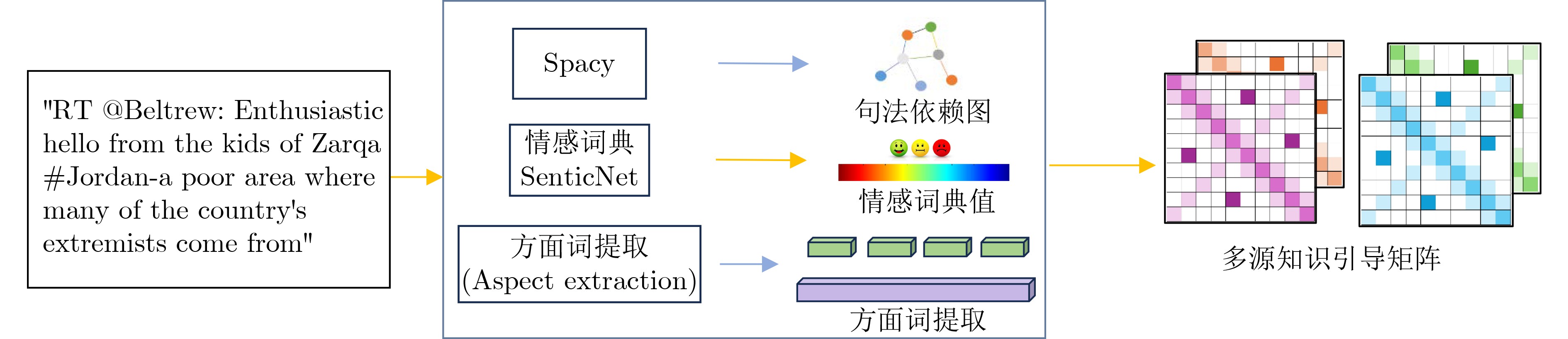
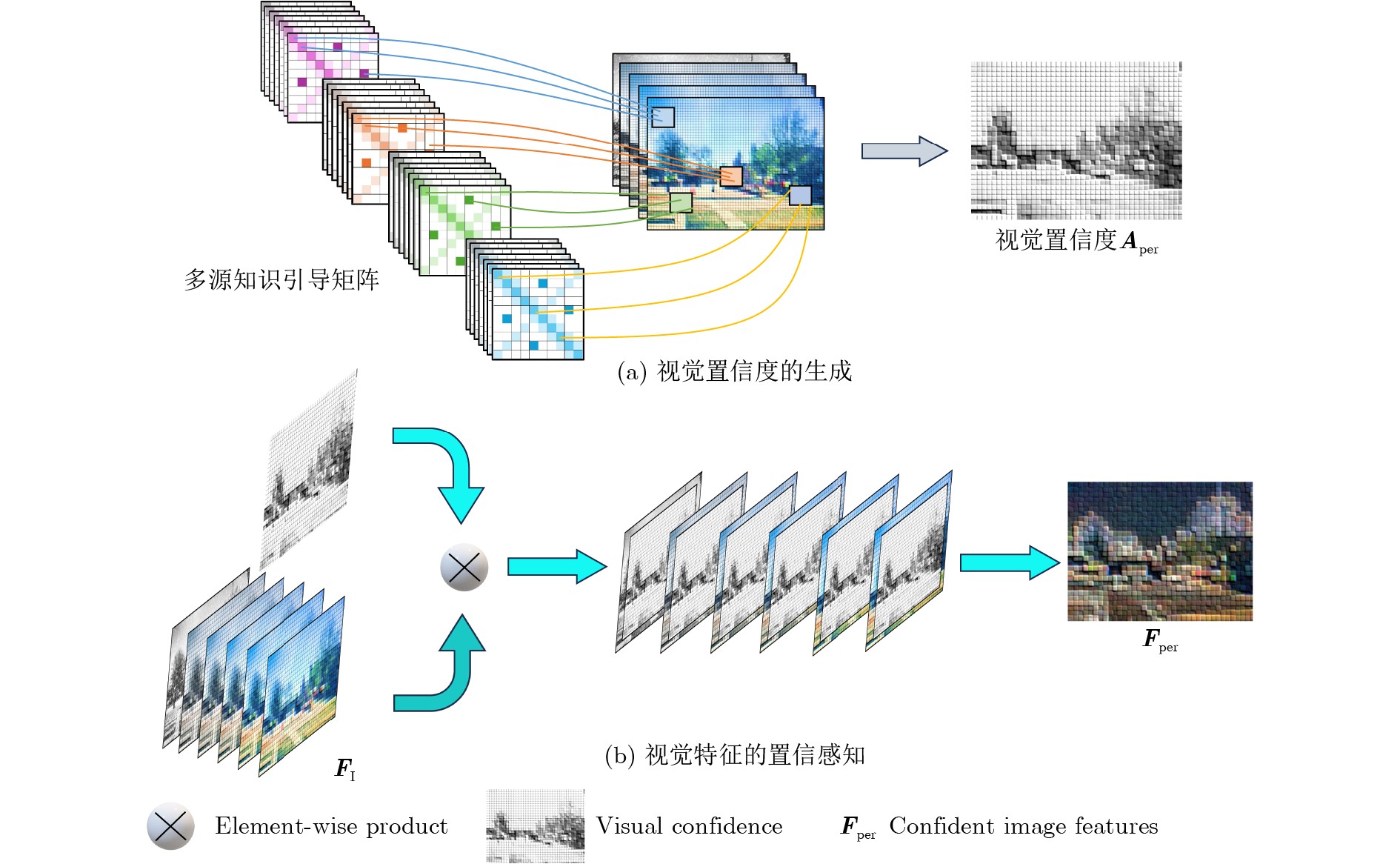
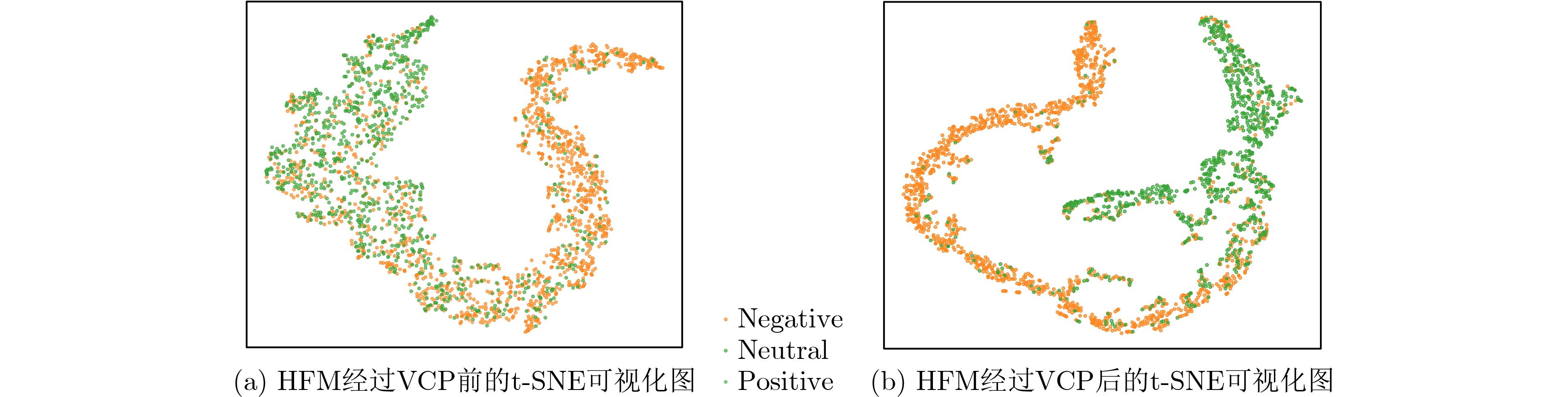
Objective Multimodal sentiment analysis is often affected by visual noise from complex environments, image-text sentiment inconsistency, and imbalanced modality contributions. When all modalities are treated without distinction, visual noise can degrade model performance. A robust mechanism is therefore needed to evaluate visual confidence and filter redundant visual information. Methods A Multimodal Sentiment Analysis Model with Multi-source Knowledge-guided Visual confidence Perception (MKVP) is proposed ( Fig. 1 ). A multi-source knowledge guidance matrix is constructed using syntactic-dependency, sentiment-intensity, and aspect-focused operators (Fig. 2 ). Guided by this matrix, the Visual Confidence Perception (VCP) module measures semantic affinity and dynamically suppresses irrelevant visual noise (Fig. 3 ). A dual-stream parallel interaction module is then used to support deep cross-modal alignment, and a global gated fusion mechanism further adjusts the fusion weights of different modalities.Results and Discussions Extensive experiments are conducted on the MVSA-Single, MVSA-Multiple, and HFM datasets. The proposed MKVP model achieves accuracy and F1 scores of 77.56% and 76.70%, 72.72% and 70.66%, and 87.26% and 86.78%, respectively. Compared with the baseline models, the accuracy and F1 score are improved by 2.45% and 3.68%, 2.19% and 2.21%, and 1.83% and 1.91%, respectively ( Table 3 ). Ablation studies show that each component contributes to performance, especially the VCP module, which filters visual noise and improves feature quality (Table 5 ). Feature-space visualization further confirms that the VCP module refines semantic representations by promoting clearer clustering of samples with the same sentiment polarity (Fig. 4 ). Case studies on mismatched image-text samples also verify the ability of the model to resolve cross-modal semantic conflicts (Table 6 ). Model-complexity analysis shows that MKVP maintains high computational efficiency and low inference latency (Table 8 ).Conclusions The proposed MKVP framework reduces the effects of visual noise and image-text sentiment inconsistency in multimodal sentiment analysis. By using multi-source knowledge to guide visual confidence perception and combining dual-stream interaction with dynamic gated fusion, the model learns robust sentiment representations from noisy multimodal data. This method provides an efficient and reliable solution for complex social media scenarios. -
表 1 数据集的统计信息
Train Val. Test 总计 MVSA-Single 3611 450 450 4511 MVSA-Multiple 13624 1700 1700 17024 HFM 19816 2410 2409 24635  下载: 导出CSV
下载: 导出CSV
表 2 实验参数设置
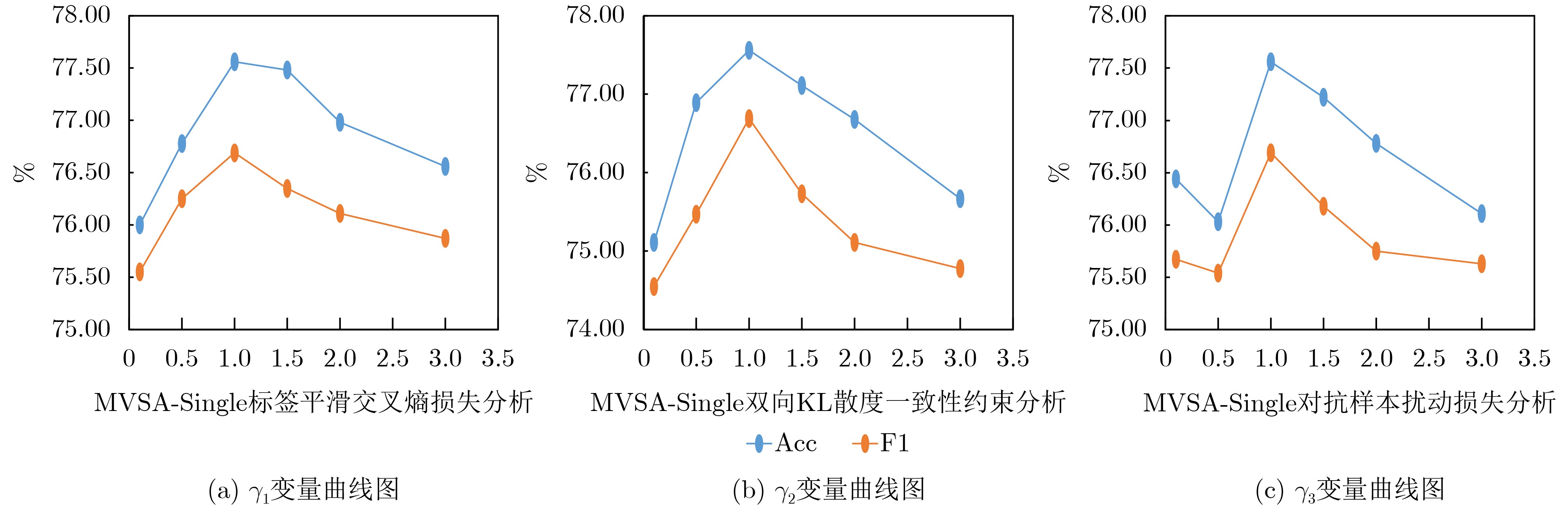
参数 MVSA-Single MVSA-Multiple HFM 批量大小 32 16 32 学习率 5E–5 2E–5 5E–5 迭代轮次 40 优化器 AdamW 嵌入维度 768 $ {\gamma }_{1} $, $ {\gamma }_{2} $, $ {\gamma }_{3} $ 1.0, 1.0, 1.0 1.0, 2.0, 1.0 1.0, 1.0, 1.0 Dropout 0.3 0.5 0.3
下载: 导出CSV
表 3 MKVP与所有基线模型在3个数据集上的对比结果
形式 模型 MVSA-Single MVSA-Multiple 模型 HFM Acc F1 Acc F1 Acc F1 文本 CNN 0.6819 0.5590 0.6564 0.5766 CNN 0.8003 0.7572 Bi-LSTM 0.7012 0.6506 0.6790 0.6790 Bi-LSTM 0.8190 0.7753 BERT 0.7111 0.6970 0.6759 0.6624 BERT 0.8339 0.8326 BiACNN 0.7036 0.6916 0.6847 0.6319 - - - TGNN 0.7034 0.6594 0.6967 0.6180 - - - 图像 ResNet-50 0.6467 0.6155 0.6188 0.6098 ResNet-50 0.7277 0.7138 ViT 0.6378 0.6226 0.6194 0.6119 Vit 0.7309 0.7152 文本+图像 MultiSentiNet 0.6984 0.6984 0.6886 0.6811 Concat(3) 0.8174 0.7874 MGNNS 0.7377 0.7270 0.7249 0.6934 D&R Net 0.8402 0.8060 CLMLF 0.7511 0.7302 0.7053 0.6845 CLMLF 0.8543 0.8487 GIGNN 0.7511 0.7333 0.7341 0.7096 GIGNN 0.8556 0.8487 DIB 0.7605 0.7520 - - - - - MVCN 0.7606 0.7455 0.7207 0.7001 MVCN 0.8568 0.8523 MFGFN 0.7622 0.7538 0.7082 0.6994 - - - D2R 0.7667 0.7559 0.7159 0.7085 D2R 0.8672 0.8625 DTN 0.7711 0.7646 0.7070 0.6810 DTN 0.8697 0.8646 MIGSIE 0.7640 0.7520 0.7272 0.7272 - - - MKVP 0.7756 0.7670 0.7272 0.7066 MKVP 0.8726 0.8678
下载: 导出CSV
表 4 多源知识注入位置对比结果
MVSA-Single MVSA-Multiple HFM Acc F1 Acc F1 Acc F1 MKVP-II 0.7356 0.7128 0.7165 0.6866 0.8701 0.8651 MKVP-IS 0.7289 0.7029 0.7200 0.6942 0.8651 0.8600 MKVP-GL 0.7511 0.7339 0.7159 0.6795 0.8622 0.8557 MKVP-LF 0.7489 0.7335 0.7165 0.6752 0.8552 0.8501 MKVP 0.7756 0.7669 0.7272 0.7066 0.8726 0.8678
下载: 导出CSV
表 5 消融实验结果
MVSA-Single MVSA-Multiple HFM Acc F1 Acc F1 Acc F1 w/o VCP 0.7522 0.7355 0.7078 0.6879 0.8564 0.8510 w/o JOL 0.7589 0.7428 0.7135 0.6890 0.8669 0.8523 w/o CMI 0.7611 0.7494 0.7106 0.6945 0.8597 0.8561 w/o GMF 0.7667 0.7558 0.7182 0.6987 0.8622 0.8552 w/o V-J 0.7511 0.7401 0.7006 0.6833 0.8497 0.8446 w/o V- J -C 0.7467 0.7361 0.7088 0.6814 0.8460 0.8413 w/o V-J-C-G 0.7422 0.7354 0.6917 0.6710 0.8447 0.8394 MKVP 0.7756 0.7669 0.7272 0.7066 0.8726 0.8678
下载: 导出CSV
表 6 案例对比结果
图像 图像标签 文本 文本标签 ResNet BERT MKVP-VCP CLMLF MKVP 
Pos Harshad’s second Missionn ? @har1603 what did you do??? #appalled Neu Pos Neg Neu Neu Pos 
Neu RT @crashspain: Wonderful Turner Field Tour today. So excited for baseball season. Thanks @Braves @BravesReddit Pos Pos Pos Pos Pos Pos 
Neg #abandoned #ruins #haikyo #urbex Neu Neu Neu Neg Neg Neg 
Neu RT@AUFAMILY: Good wins over evil as there are once again two lives oaks at Toomer’s Corner. War Eagle! #ToomersForever Neg Pos Pos Pos Pos Neg
下载: 导出CSV
表 7 文本抗噪声实验结果
噪声类型 噪声强度(%) MVSA-Multiple HFM Acc F1 Acc F1 Shuffle 10 0.7124 0.6820 0.8618 0.8622 30 0.7065 0.6769 0.8502 0.8511 50 0.6924 0.6620 0.8419 0.8428 无噪声 - 0.7272 0.7066 0.8726 0.8678
下载: 导出CSV
表 8 模型复杂度与效率计算结果
Params(M) FLOPs(G) Time(ms) MVSA-Single MGNNS 73.78 48.41 14.24 0.7377 CLMLF 205.52 24.07 9.46 0.7511 D2R 345.54 25.39 36.21 0.7667 MKVP 175.11 22.48 13.66 0.7756
下载: 导出CSV
-
[1] YUAN Yuan, LI Zhaojian, and ZHAO Bin. A survey of multimodal learning: Methods, applications, and future[J]. ACM Computing Surveys, 2025, 57(7): 167. doi: 10.1145/3713070. [2] LU Ming, DONG Zhiqiang, GUO Ziming, et al. A multi-modal sarcasm detection model based on cue learning[J]. Scientific Reports, 2025, 15(1): 10261. doi: 10.1038/s41598-025-94266-w. [3] ZHAO Kai, ZHENG Mingsheng, LI Qingguan, et al. Multimodal sentiment analysis—a comprehensive survey from a fusion methods perspective[J]. IEEE Access, 2025, 13: 64556–64583. doi: 10.1109/ACCESS.2025.3554665. [4] LIU Xinjing, LI Ruifan, YE Shuqin, et al. Multimodal aspect-based sentiment analysis under conditional relation[C]. The 31st International Conference on Computational Linguistics, Abu Dhabi, UAE, 2025: 313–323. [5] YU Bengong, LI Chenyue, and SHI Zhongyu. Multi-grained feature gating fusion network for multimodal sentiment analysis[J]. Knowledge and Information Systems, 2025, 67(8): 6879–6905. doi: 10.1007/s10115-025-02446-x. [6] HUANG Huiting, GONG Tieliang, HE Kai, et al. Robust multimodal sentiment analysis via double information bottleneck[J]. Information Fusion, 2026, 129: 103964. doi: 10.1016/j.inffus.2025.103964. [7] 胡泽, 陈志南, 杨宏宇. 多源特征融合增强的虚假新闻检测方法[J]. 电子与信息学报, 2025, 47(8): 2919–2934. doi: 10.11999/JEIT250041.HU Ze, CHEN Zhinan, and YANG Hongyu. A fake news detection approach enhanced by multi-source feature fusion[J]. Journal of Electronics & Information Technology, 2025, 47(8): 2919–2934. doi: 10.11999/JEIT250041. [8] ZI Lingling, PAN Xiangkai, and CONG Xin. MFSC: A multimodal aspect-level sentiment classification framework with multi-image gate and fusion networks[J]. Electronics, 2024, 13(12): 2349. doi: 10.3390/electronics13122349. [9] YANG Xiaocui, FENG Shi, ZHANG Yifei, et al. Multimodal sentiment detection based on multi-channel graph neural networks[C]. The 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021: 328–339. doi: 10.18653/v1/2021.acl-long.28. [10] WANG Hongbin, REN Chun, and YU Zhengtao. Multimodal sentiment analysis based on cross-instance graph neural networks[J]. Applied Intelligence, 2024, 54(4): 3403–3416. doi: 10.1007/s10489-024-05309-0. [11] ZHONG Qihuang, DING Liang, LIU Juhua, et al. Knowledge graph augmented network towards multiview representation learning for aspect-based sentiment analysis[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35(10): 10098–10111. doi: 10.1109/TKDE.2023.3250499. [12] KIM Y. Convolutional neural networks for sentence classification[C]. The 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 2014: 1746–1751. doi: 10.3115/v1/D14-1181. [13] ZHOU Peng, SHI Wei, TIAN Jun, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]. The 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 2016: 207–212. doi: 10.18653/v1/P16-2034. [14] LAI Siwei, XU Liheng, LIU Kang, et al. Recurrent convolutional neural networks for text classification[C]. The 29th AAAI Conference on Artificial Intelligence, Austin, USA, 2015: 2267–2273. doi: 10.1609/aaai.v29i1.9513. [15] HUANG Lianzhe, MA Dehong, LI Sujian, et al. Text level graph neural network for text classification[C]. The 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 2019: 3444–3450. doi: 10.18653/v1/D19-1345. [16] XU Nan and MAO Wenji. MultiSentiNet: A deep semantic network for multimodal sentiment analysis[C]. The 2017 ACM International Conference on Information and Knowledge Management, Singapore, Singapore, 2017: 2399–2402. doi: 10.1145/3132847.3133142. [17] SCHIFANELLA R, DE JUAN P, TETREAULT J, et al. Detecting sarcasm in multimodal social platforms[C]. The 24th ACM International Conference on Multimedia, Amsterdam, Netherlands, 2016: 1136–1145. doi: 10.1145/2964284.2964321. [18] XU Nan, ZENG Zhixiong, and MAO Wenji. Reasoning with multimodal sarcastic tweets via modeling cross-modality contrast and semantic association[C]. The 58th Annual Meeting of the Association for Computational Linguistics, 2020: 3777–3786. doi: 10.18653/v1/2020.acl-main.349. [19] LI Zhen, XU Bing, ZHU Conghui, et al. CLMLF: A contrastive learning and multi-layer fusion method for multimodal sentiment detection[C]. Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, USA, 2022: 2282–2294. doi: 10.18653/v1/2022.findings-naacl.175. [20] WEI Yiwei, YUAN Shaozu, YANG Ruosong, et al. Tackling modality heterogeneity with multi-view calibration network for multimodal sentiment detection[C]. The 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada, 2023: 5240–5252. doi: 10.18653/v1/2023.acl-long.287. [21] CHEN Yifan, LI Kuntao, MAI Weixing, et al. D2R: Dual-branch dynamic routing network for multimodal sentiment detection[C]. The 2024 Conference on Empirical Methods in Natural Language Processing, Miami, USA, 2024: 3536–3547. doi: 10.18653/v1/2024.emnlp-main.207. [22] 余本功, 石中玉. 深层注意力和两阶段融合的图文情感对比学习方法[J]. 计算机工程与应用, 2025, 61(3): 223–233. doi: 10.3778/j.issn.1002-8331.2309-0470.YU Bengong and SHI Zhongyu. Deep attention and two-stage fusion of image-text sentiment contrastive learning method[J]. Computer Engineering and Applications, 2025, 61(3): 223–233. doi: 10.3778/j.issn.1002-8331.2309-0470. [23] 卜韵阳, 卜凡亮, 张志江. 多通道交互下全局语义信息增强的多模态情感分析[J]. 计算机工程与应用, 2025, 61(19): 137–146. doi: 10.3778/j.issn.1002-8331.2406-0376.BU Yunyang, BU Fanliang, and ZHANG Zhijiang. Multimodal sentiment analysis of global semantic information enhancement under multi-channel interaction[J]. Computer Engineering and Applications, 2025, 61(19): 137–146. doi: 10.3778/j.issn.1002-8331.2406-0376. -

 下载:
下载:


图(5) / 表(8)
计量
- 文章访问数: 208
- HTML全文浏览量: 121
- PDF下载量: 19
- 被引次数: 0
