

Cross-domain Deepfake Detection with Dynamic Artifact Tracking and Spatio-frequency Interaction Analysis
-
摘要: 针对跨域深度伪造检测中存在依赖静态伪影与固定频段、局限单一分析域、全局关联能力不足的问题,提出一种融合动态伪影追踪与空频交互分析的金字塔式交互双流网络(PIDSNet)。首先,通过多分支特征提取模块与频谱卷积模块实现伪影特征的动态挖掘,降低针对固定参数和频段的依赖,显著提高伪影特征的自适应捕捉能力。其次,通过融合金字塔挤压注意力模块和多头自注意力机制,实现全局特征与局部特征提取的平衡。最后,在空域和频域分别构建高斯金字塔与拉普拉斯金字塔,多层次提取高频信息和低频信息并实现跨域特征融合,构建新型空频特征动态交互机制。实验结果表明,在包含25种生成对抗网络和扩散模型的伪造数据集中平均准确度提升7.4%,为深度伪造检测的跨域泛化性研究提供了新的方案。Abstract:
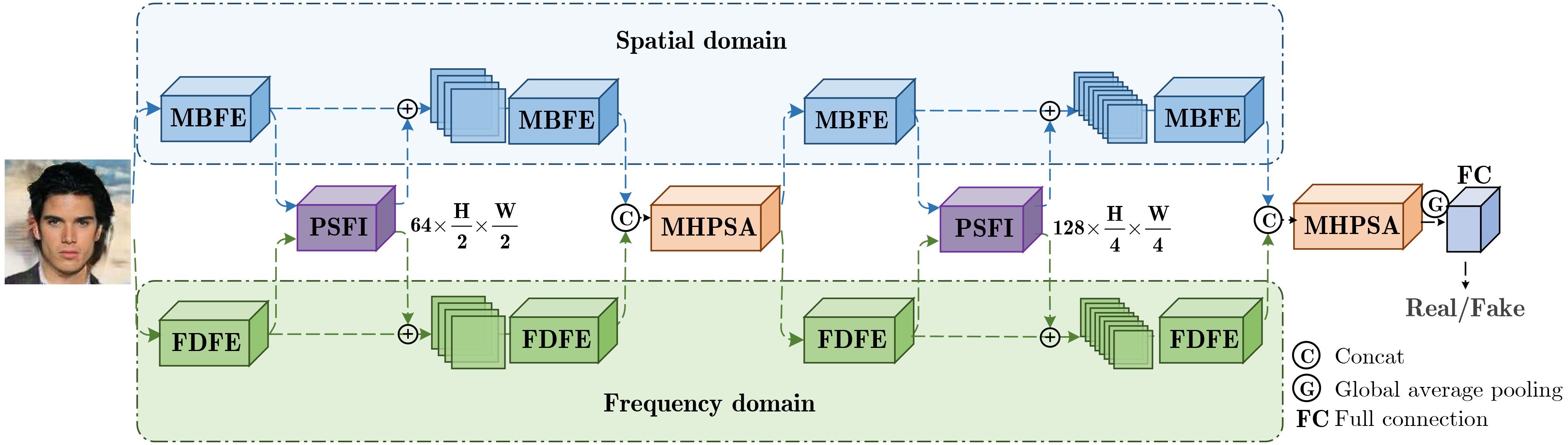
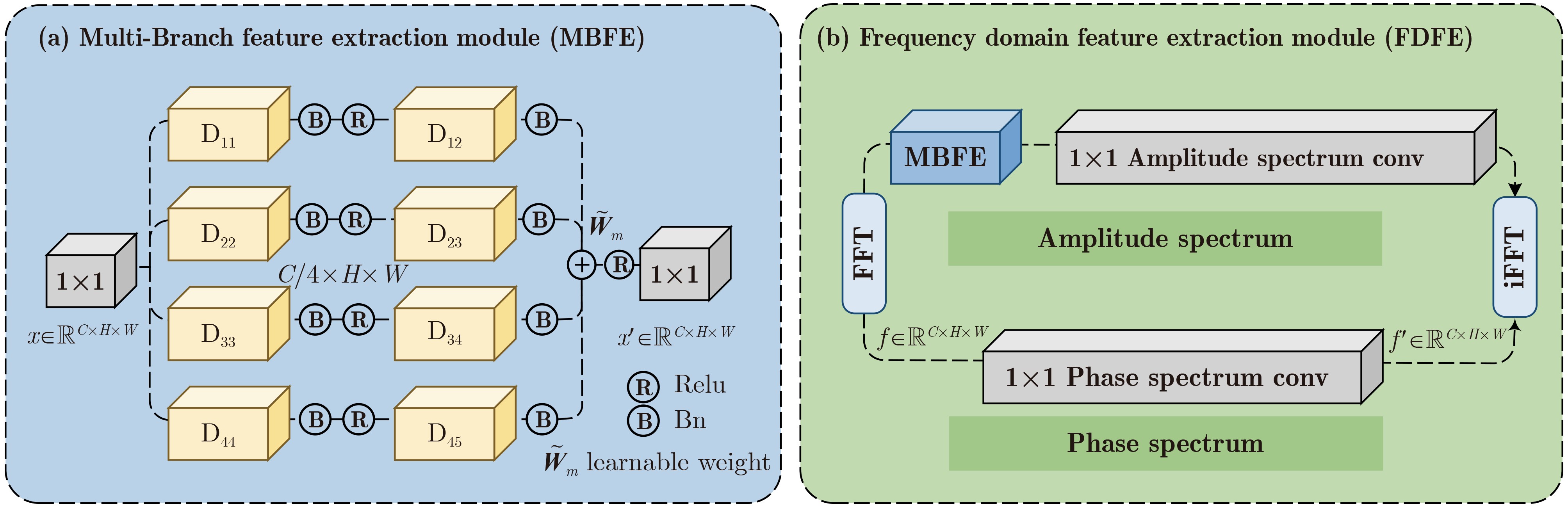
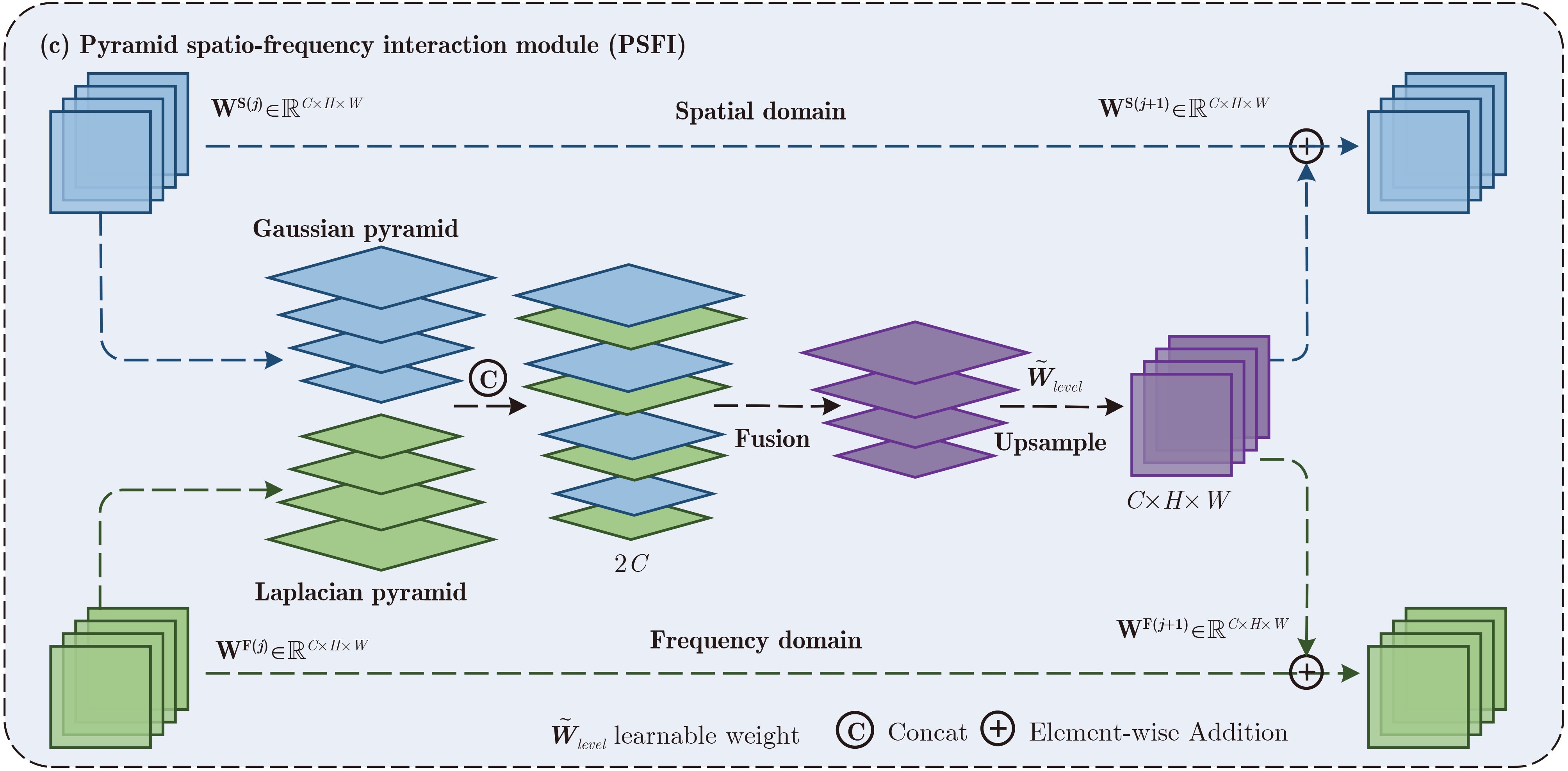
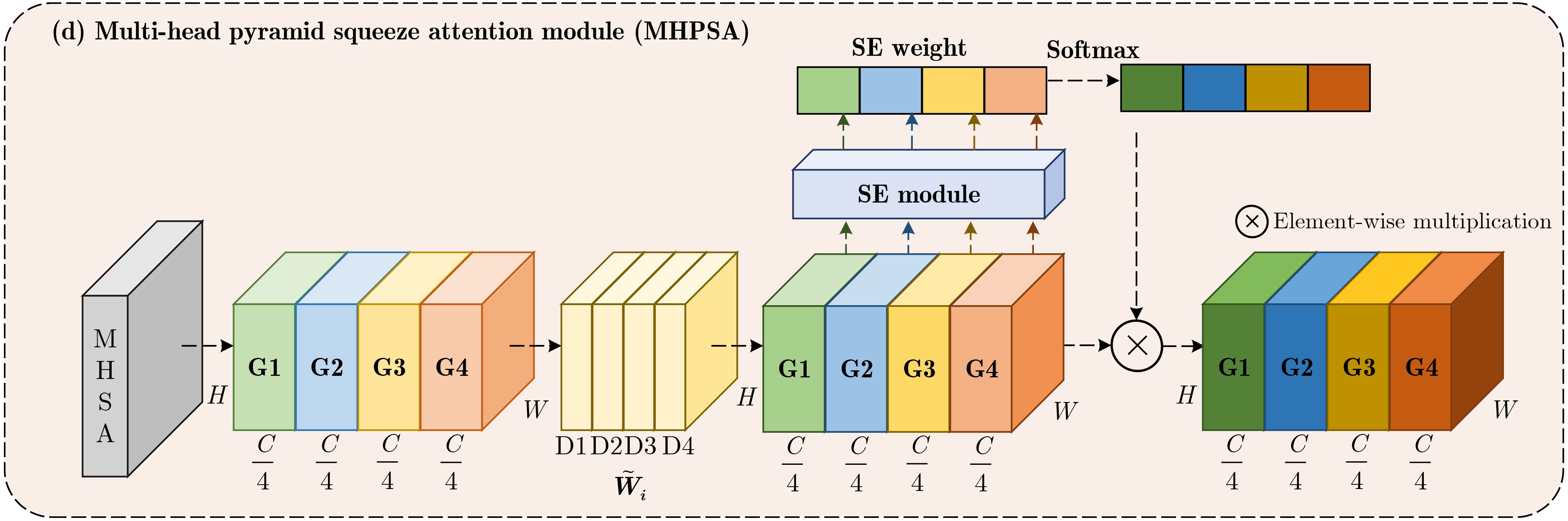
Objective The rapid development of Generative Adversarial Network (GAN) and Diffusion Model (DM) techniques has sharply increased the number of fake images. The wide dissemination of such images poses potential and unpredictable risks to individuals, society, and national security. Efficient and highly generalizable deepfake detection methods are therefore needed. Cross-domain detection has become a central task in deepfake detection. However, existing methods often rely on specific artifacts or fixed parameters for feature extraction. They also learn spatial and frequency modalities separately, lack dynamic interaction mechanisms, and provide insufficient global feature association. To address these limitations, a Pyramid Interactive Dual-Stream Network (PIDSNet) is proposed. This network integrates dynamic artifact tracking with spatio-frequency interaction analysis. Methods PIDSNet consists of spatial and frequency branches ( Fig. 1 ) and four cooperative modules: the Multi-Branch Feature Extraction (MBFE) module, the Frequency Domain Feature Extraction (FDFE) module, the Pyramid Spatio-Frequency Interaction (PSFI) module, and the Multi-Head Pyramid Squeeze Attention (MHPSA) module. MBFE (Fig. 2 ), which serves as the basic unit of the spatial branch, uses multilevel and multibranch dilated convolutions to reduce information loss as the receptive field expands. It extracts global and local features jointly. FDFE, which is central to the frequency branch, combines MBFE with spectral convolution to dynamically identify frequency-domain artifact features. This design reduces the reliance of traditional frequency-domain methods on fixed parameters and frequency bands. It also improves the adaptive capture of artifacts from different generative models. PSFI drives interaction between the two branches (Fig. 3 ). It constructs a Gaussian pyramid in the spatial domain and a Laplacian pyramid in the frequency domain to capture low-frequency global information and high-frequency details, respectively. Dynamic weighting at each pyramid level supports adaptive spatio-frequency feature fusion and builds a dynamic interaction mechanism. MHPSA integrates Multi-Head Self-Attention (MHSA) with dilated convolution (Fig. 4 ). It retains the local detail capture ability of the Pyramid Squeeze Attention (PSA) module and strengthens global feature modeling, thereby improving model adaptability and robustness.Results and Discussions To evaluate cross-domain detection across different generative paradigms, PIDSNet is trained on the ProGAN subset and tested on multiple GAN and DM datasets. For GAN detection, the mean Accuracy (Acc.) reaches 95.2% on the ForenSynths test set containing four GANs ( Table 3 ). This value is 5.3 and 5.2 percentage points higher than those of LGrad and FreqNet, respectively. On the GANGen dataset containing nine GANs (Tables 4 and5 ), the mean Acc. reaches 95.5%. This result represents a 20.1 percentage-point improvement over F3Net. Compared with FreqNet, PIDSNet improves mean Acc. and mean Average Precision (A.P.) by 4.1 and 1.3 percentage points, respectively. For DM detection, tests are conducted on the DiffusionForensics and Ojha datasets. On DiffusionForensics (Table 6 ), the mean Acc. reaches 95.4%, which is 4.8 and 13.2 percentage points higher than those of LGrad and FreqNet, respectively. On Ojha (Table 7 ), the mean Acc. and mean A.P. reach 96.1% and 99.4%, respectively. More importantly, PIDSNet has only 2.4M parameters (Table 8 ) and achieves mean Acc. and mean A.P. values of 95.7% and 98.7% across 25 datasets, outperforming competing methods. These experiments indicate that PIDSNet, although trained only on the ProGAN subset, adapts to multiple GAN types and effectively detects DM-generated images with different spatial and frequency artifact characteristics. This confirms its strong cross-model and cross-paradigm generalization ability. In addition, Gradient-weighted Class Activation Mapping (Grad-CAM) visualizations indicate that PIDSNet identifies detection-relevant regions in face images, although face images are absent from the training data (Fig. 5 ).Conclusions This study addresses the weak domain adaptability and poor generalization of current GAN and DM detection methods, which often rely on domain-specific artifacts or fixed parameters and have limited modality interaction. A spatio-frequency collaborative learning framework and a dynamic artifact tracking mechanism are constructed to reduce reliance on specific artifacts and fixed parameters. This design improves the extraction of general forgery features. The effectiveness of PIDSNet is validated on image datasets generated by 25 different GAN and DM models. Compared with current advanced models, the mean Acc. and A.P. are improved, confirming strong performance in cross-domain deepfake detection. However, PIDSNet still has limitations. For specific models such as S3GAN, whose high-frequency energy distribution is close to that of real images, performance can still be improved. Future work should further optimize frequency-domain feature extraction, improve detection under compression distortion and noise interference, and study artifact separation and detection for images generated by multiple models. These directions may further improve model adaptability in complex real-world settings. -
表 2 ForenSynths测试集2类训练设置评估(%)
方法 StyleGAN StyleGAN2 CycleGAN StarGAN 平均值 Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Wang[26] 52.8 82.8 75.7 96.6 58.6 81.5 51.2 74.3 59.6 83.8 F3Net[16] 84.5 99.5 82.2 99.8 81.2 89.7 100.0 100.0 87.0 97.3 Frank[27] 73.1 68.5 75.0 70.9 86.5 80.8 85.0 77.0 79.9 74.3 BiHPF[28] 71.6 74.1 77.0 81.1 86.0 86.6 93.8 80.8 82.1 80.7 FrePGAN[29] 80.8 92.0 72.2 94.0 69.1 70.3 98.5 100.0 80.2 89.1 LGrad[13] 88.3 97.6 87.5 97.5 82.7 90.7 96.5 97.7 88.8 95.9 FreqNet[15] 88.4 98.9 85.8 98.1 88.7 99.8 95.5 100.0 89.6 99.2 PIDSNet 90.5 98.4 92.7 99.3 90.4 99.2 97.1 100.0 92.7 99.2  下载: 导出CSV
下载: 导出CSV
表 3 ForenSynths测试集4类训练设置评估(%)
方法 StyleGAN StyleGAN2 CycleGAN StarGAN 平均值 Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Wang[26] 63.8 91.4 76.4 97.5 72.7 88.6 63.8 90.8 69.2 92.1 F3Net[16] 92.6 99.7 88.0 99.8 76.4 84.3 99.5 99.8 89.1 95.9 Frank[27] 74.5 72.0 73.1 71.4 75.5 71.2 99.5 99.5 80.7 78.5 BiHPF[28] 76.9 75.1 76.2 74.7 81.9 78.9 94.4 94.4 82.4 80.8 FrePGAN[29] 80.7 89.6 84.1 98.6 71.1 74.4 99.9 100.0 84.0 90.7 LGrad[13] 89.5 94.8 90.6 97.5 84.5 94.0 94.8 97.6 89.9 96.0 FreqNet[15] 90.2 99.7 88.0 99.5 95.8 99.6 85.7 99.8 90.0 99.7 PIDSNet 91.4 99.9 97.8 99.8 91.5 98.8 100.0 100.0 95.2 99.6
下载: 导出CSV
表 4 GANGen数据集4类训练设置评估(%)
方法 AttGAN BEGAN CramerGAN InfoMaxGAN MMDGAN Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Wang[26] 51.1 83.7 50.2 44.9 81.5 97.5 71.1 94.7 72.9 94.4 F3Net[16] 85.2 94.8 87.1 97.5 89.5 99.8 67.1 83.1 73.7 99.6 LGrad[13] 68.6 93.8 69.9 89.2 50.3 54.0 71.1 82.0 57.5 67.3 FreqNet[15] 88.6 98.1 97.5 99.4 93.5 97.8 92.1 96.6 91.7 97.6 PIDSNet 95.9 99.3 99.5 100.0 99.0 99.9 98.1 99.6 98.0 99.6
下载: 导出CSV
表 5 GANGen数据集4类训练设置评估(%)
方法 RelGAN S3GAN SNGAN STGAN 9 GANs 平均值 Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Wang[26] 53.3 82.1 55.2 66.1 62.7 90.4 63.0 92.7 62.3 82.9 F3Net[16] 98.8 100.0 65.4 70.0 51.6 93.6 60.3 99.9 75.4 93.1 LGrad[13] 89.1 99.1 78.5 86.0 78.0 87.4 54.8 68.0 68.6 80.8 FreqNet[15] 97.9 99.5 84.5 88.7 81.7 95.3 95.4 99.1 91.4 96.9 PIDSNet 100.0 100.0 80.5 87.1 94.5 98.4 94.1 100.0 95.5 98.2
下载: 导出CSV
表 6 DiffusionForensics数据集4类训练设置评估(%)
方法 LDM PNDM VQ-Diffusion Stable Diffusion V1 Stable Diffusion V2 平均值 Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. F3Net[16] 100.0 100.0 72.8 99.5 99.9 99.9 73.4 97.2 99.8 100.0 89.2 99.3 LGrad[13] 99.7 100.0 69.5 98.5 96.2 100.0 90.4 99.4 97.1 100.0 90.6 99.6 Ojha[11] 82.2 97.1 75.3 92.5 83.5 97.7 56.4 90.4 71.5 92.4 73.8 94.0 FreqNet[15] 94.2 99.2 78.8 99.7 97.8 100.0 62.4 93.4 78.0 92.1 82.2 96.9 PIDSNet 99.7 100.0 79.3 99.9 98.0 99.8 99.4 100.0 99.8 100.0 95.4 98.2
下载: 导出CSV
表 7 Ojha数据集4类训练设置评估(%)
方法 Glide100_10 Glide100_27 Glide50_27 LDM100 LDM200 LDM200_cfg Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. F3Net[16] 88.3 95.4 87.0 94.5 88.5 95.4 74.1 84.0 73.4 83.3 80.7 89.1 LGrad[13] 89.4 94.9 87.4 93.2 90.7 95.1 94.8 99.2 94.2 99.1 95.9 99.2 Ojha[11] 90.1 97.0 90.7 97.2 91.1 97.4 90.5 97.0 90.2 97.1 77.3 88.6 FreqNet[15] 78.8 89.3 76.2 86.9 78.0 88.5 94.3 99.3 93.8 99.2 93.0 98.8 PIDSNet 96.5 99.5 95.1 99.1 95.9 99.2 96.5 99.6 96.7 99.5 96.0 99.4
下载: 导出CSV
表 8 各数据集4类训练设置评估(%)
方法 参数量 ForenSynths GANGen DiffusionForensics Ojha 平均值 Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Acc. A.P. Wang[26] 18.6M 73.5 93.5 62.3 82.9 - - - - - - F3Net[16] 48.9M 91.0 96.7 75.4 93.1 89.2 99.3 82.0 90.3 82.9 94.4 LGrad[13] 46.6M 91.6 96.8 68.6 80.8 90.6 99.6 92.1 96.8 83.2 91.6 FreqNet[15] 2.1M 91.9 99.7 91.4 96.9 82.2 96.9 85.7 93.7 88.3 96.7 PIDSNet 2.4M 96.1 99.7 95.5 98.2 95.4 98.2 96.1 99.4 95.7 98.7
下载: 导出CSV
表 9 ForenSynths数据集消融实验(%)
MBFE FDFE PSFI MHPSA 平均Acc. √ √ √ 91.3 √ √ √ 90.9 √ √ 87.1 √ √ √ 92.7 √ √ √ 92.8 √ √ √ √ 95.2
下载: 导出CSV
-
[1] LIU Zhian, LI Maomao, ZHANG Yong, et al. Fine-grained face swapping via regional GAN inversion[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 8578–8587. doi: 10.1109/CVPR52729.2023.00829. [2] ZHAO Wenliang, RAO Yongming, SHI Weikang, et al. DiffSwap: High-fidelity and controllable face swapping via 3D-aware masked diffusion[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 8568–8577. doi: 10.1109/CVPR52729.2023.00828. [3] BALIAH S, LIN Qinliang, LIAO Shengcai, et al. Realistic and efficient face swapping: A unified approach with diffusion models[C]. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, USA, 2025: 1062–1071. doi: 10.1109/WACV61041.2025.00112. [4] YUAN Shuaiwei, DONG Junyu, and LI Yuezun. Where the devil hides: Deepfake detectors can no longer be trusted[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 8764–8774. doi: 10.1109/CVPR52734.2025.00819. [5] HUANG Zhenglin, HU Jinwei, LI Xiangtai, et al. SIDA: Social media image deepfake detection, localization and explanation with large multimodal model[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 28831–28841. doi: 10.1109/CVPR52734.2025.02685. [6] 丁峰, 匡仁盛, 周越, 等. 深度伪造及其取证技术综述[J]. 中国图象图形学报, 2024, 29(2): 295–317. doi: 10.11834/jig.230088.DING Feng, KUANG Rensheng, ZHOU Yue, et al. A survey of deepfake and related digital forensics[J]. Journal of Image and Graphics, 2024, 29(2): 295–317. doi: 10.11834/jig.230088. [7] CAO Junyi, MA Chao, YAO Taiping, et al. End-to-end reconstruction-classification learning for face forgery detection[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 4113–4122. doi: 10.1109/CVPR52688.2022.00408. [8] SHIOHARA K and YAMASAKI T. Detecting deepfakes with self-blended images[C]. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, USA, 2022: 18720–18729. doi: 10.1109/CVPR52688.2022.01816. [9] 张晶, 许盼, 刘文君, 等. 多样性负实例生成的跨域人脸伪造检测[J]. 中国图象图形学报, 2025, 30(2): 421–434 doi: 10.11834/jig.240160.ZHANG Jing, XU Pan, LIU Wenjun, et al. Negative instance generation for cross-domain facial forgery detection[J]. Journal of Image and Graphics, 2025, 30(2): 421–434. doi: 10.11834/jig.240160. [10] YAN Zhiyuan, LUO Yuhao, LYU Siwei, et al. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 8984–8994. doi: 10.1109/CVPR52733.2024.00858. [11] OJHA U, LI Yuheng, and LEE Y J. Towards universal fake image detectors that generalize across generative models[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 24480–24489. doi: 10.1109/CVPR52729.2023.02345. [12] KASHIANI H, TALEMI N A, and AFGHAH F. FreqDebias: Towards generalizable deepfake detection via consistency-driven frequency debiasing[C]. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2025: 8775–8785. doi: 10.1109/CVPR52734.2025.00820. [13] TAN Chuangchuang, ZHAO Yao, WEI Shikui, et al. Learning on gradients: Generalized artifacts representation for GAN-generated images detection[C]. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023: 12105–12114. doi: 10.1109/CVPR52729.2023.01165. [14] TAN Chuangchuang, LIU Huan, ZHAO Yao, et al. Rethinking the up-sampling operations in CNN-based generative network for generalizable deepfake detection[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 28130–28139. doi: 10.1109/CVPR52733.2024.02657. [15] TAN Chuangchuang, ZHAO Yao, WEI Shikui, et al. Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning[C]. The 38th AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2024: 5052–5060. doi: 10.1609/aaai.v38i5.28310. [16] QIAN Yuyang, YIN Guojun, SHENG Lu, et al. Thinking in frequency: Face forgery detection by mining frequency-aware clues[C]. The 16th European Conference on Computer Vision, Glasgow, UK, 2020: 86–103. doi: 10.1007/978-3-030-58610-2_6. [17] BINH L M and WOO S. ADD: Frequency attention and multi-view based knowledge distillation to detect low-quality compressed deepfake images[C]. The 36th AAAI Conference on Artificial Intelligence, Washington, USA, 2022: 122–130. doi: 10.1609/aaai.v36i1.19886. [18] WANG Bo, WU Xiaohan, WANG Fei, et al. Spatial-frequency feature fusion based deepfake detection through knowledge distillation[J]. Engineering Applications of Artificial Intelligence, 2024, 133: 108341. doi: 10.1016/j.engappai.2024.108341. [19] 孙磊, 张洪蒙, 毛秀青, 等. 基于超分辨率重建的强压缩深度伪造视频检测[J]. 电子与信息学报, 2021, 43(10): 2967–2975. doi: 10.11999/JEIT200531.SUN Lei, ZHANG Hongmeng, MAO Xiuqing, et al. Super-resolution reconstruction detection method for deepfake hard compressed videos[J]. Journal of Electronics & Information Technology, 2021, 43(10): 2967–2975. doi: 10.11999/JEIT200531. [20] 王艳, 孙钦东, 荣东柱, 等. 伪影间共性机理驱动的多域感知社交网络深度伪造视频检测[J]. 电子与信息学报, 2024, 46(9): 3713–3721. doi: 10.11999/JEIT240025.WANG Yan, SUN Qindong, RONG Dongzhu, et al. Deepfake video detection on social networks using multi-domain aware driven by common mechanism analysis between artifacts[J]. Journal of Electronics & Information Technology, 2024, 46(9): 3713–3721. doi: 10.11999/JEIT240025. [21] WANG Zhendong, BAO Jianmin, ZHOU Wengang, et al. Dire for diffusion-generated image detection[C]. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 22445–22455. doi: 10.1109/ICCV51070.2023.02051. [22] HOODA A, MANGAOKAR N, FENG R, et al. D4: Detection of adversarial diffusion deepfakes using disjoint ensembles[C]. 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2024: 3812–3822. doi: 10.1109/WACV57701.2024.00377. [23] LIU Baoping, LIU Bo, DING Ming, et al. Detection of diffusion model-generated faces by assessing smoothness and noise tolerance[C]. 2024 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Toronto, Canada, 2024: 1–6. doi: 10.1109/BMSB62888.2024.10608232. [24] ZHANG Hu, ZU Keke, LU Jian, et al. EPSANet: An efficient pyramid squeeze attention block on convolutional neural network[C]. The 16th Asian Conference on Computer Vision, Macao, China, 2023: 1161–1177. doi: 10.1007/978-3-031-26313-2_33. [25] COOLEY J W, LEWIS P A W, and WELCH P D. The fast Fourier transform and its applications[J]. IEEE Transactions on Education, 1969, 12(1): 27–34. doi: 10.1109/TE.1969.4320436. [26] WANG Shengyu, WANG O, ZHANG R, et al. CNN-generated images are surprisingly easy to spot. for now[C]. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2020: 8695–8704. doi: 10.1109/CVPR42600.2020.00872. [27] FRANK J, EISENHOFER T, SCHÖNHERR L, et al. Leveraging frequency analysis for deep fake image recognition[C]. The 37th International Conference on Machine Learning, 2020: 3247–3258. [28] JEONG Y, KIM D, MIN S, et al. BiHPF: Bilateral high-pass filters for robust deepfake detection[C]. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2022: 48–57. doi: 10.1109/WACV51458.2022.00293. [29] JEONG Y, KIM D, RO Y, et al. FrePGAN: Robust deepfake detection using frequency-level perturbations[C]. The 36th AAAI Conference on Artificial Intelligence, Washington, USA, 2022: 1060–1068. doi: 10.1609/aaai.v36i1.19990. -

 下载:
下载:



图(5) / 表(11)
计量
- 文章访问数: 156
- HTML全文浏览量: 87
- PDF下载量: 14
- 被引次数: 0
