

HWT-SRNet: Heterogeneous Windows Transformer Network for Image Super-Resolution
-
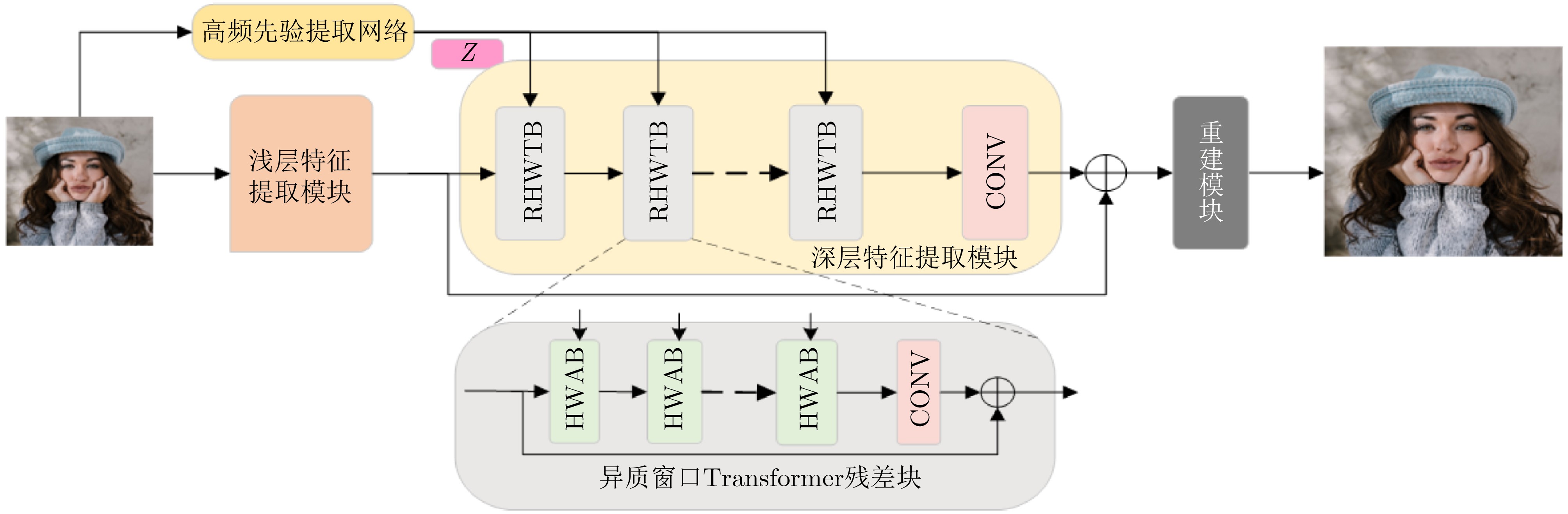
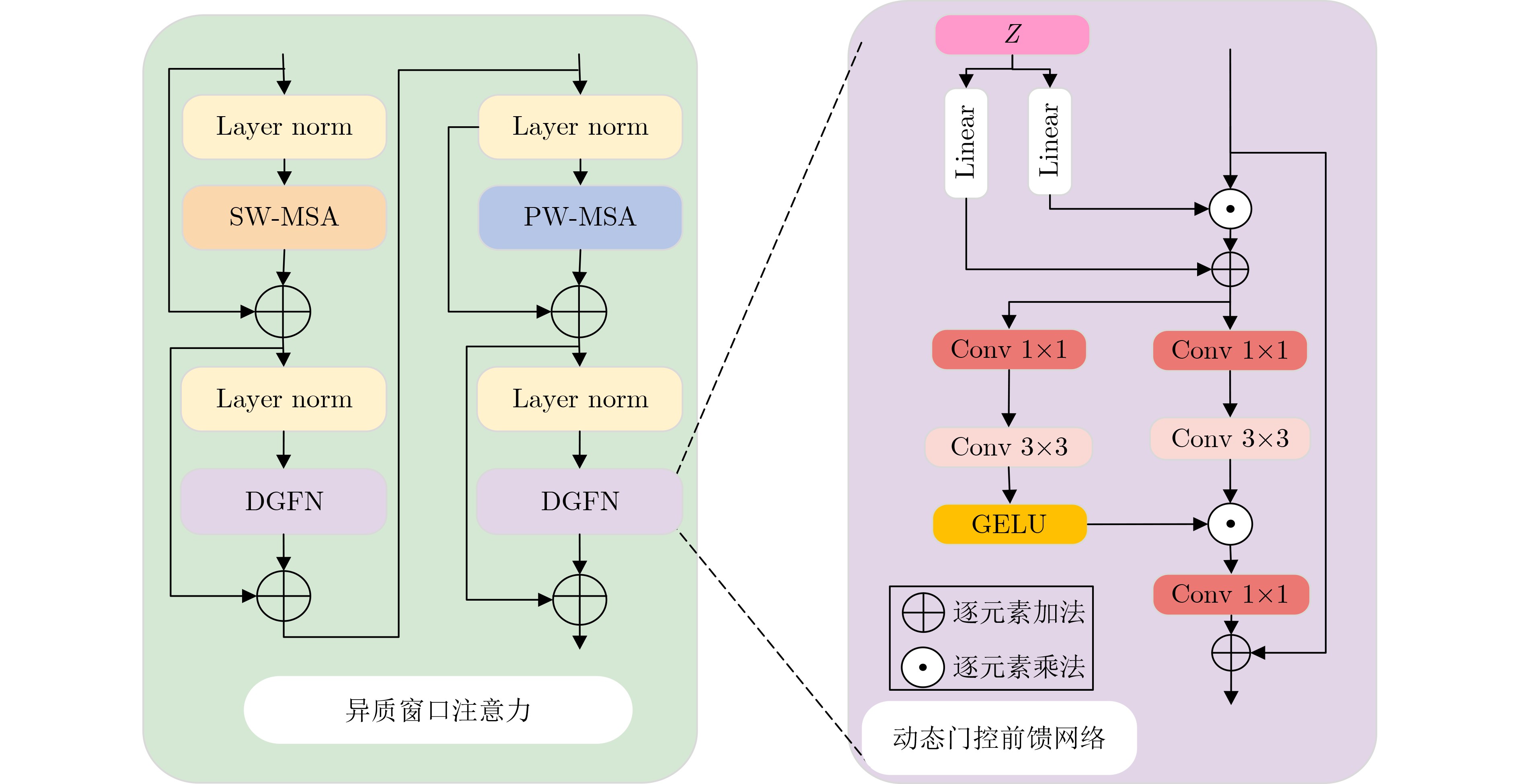
摘要: 在大数据时代,图像质量参差不齐,对低质量图像进行高分辨率重建具有重要的研究与应用价值。基于 Transformer的单图像超分辨率方法通常将自注意力机制限制在局部非重叠窗口中,导致感受野受限、窗口边界失真以及高频细节重构能力不足等问题。为此,该文提出一种基于Swin IR的异质窗口注意力网络(Heterogeneous Window Transformer Network for Image Super-Resolution, HWT-SRNet)。首先,设计异质窗口注意力机制,充分融合多尺度特征,以缓解窗口边界失真问题并有效扩大感受野。其次,针对Transformer在高频信息重构能力上的不足,提出一种高频先验特征提取网络,增强网络对边缘与纹理细节的恢复能力。实验结果表明,HWT-SRNet在Set5, Set14, BSD100, Urban100, Manga109五个基准测试集上,PSNR指标相比基线模型Swin IR提升0.10~0.37 dB,同时,与其他具有代表性的超分模型CAT, ACT, ART等相比,在图像细节和纹理方面也取得了更优的视觉效果。
-
关键词:
- 超分辨率重建 /
- Transformer /
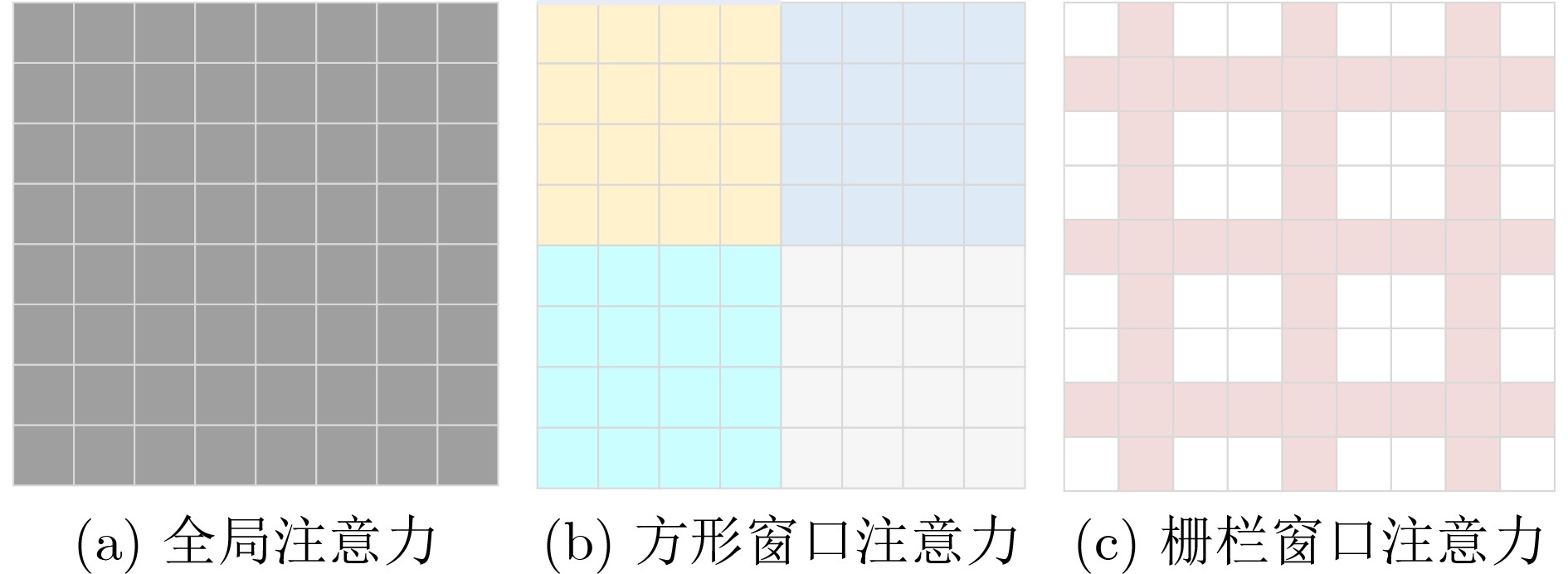
- 异质窗口 /
- 高频先验
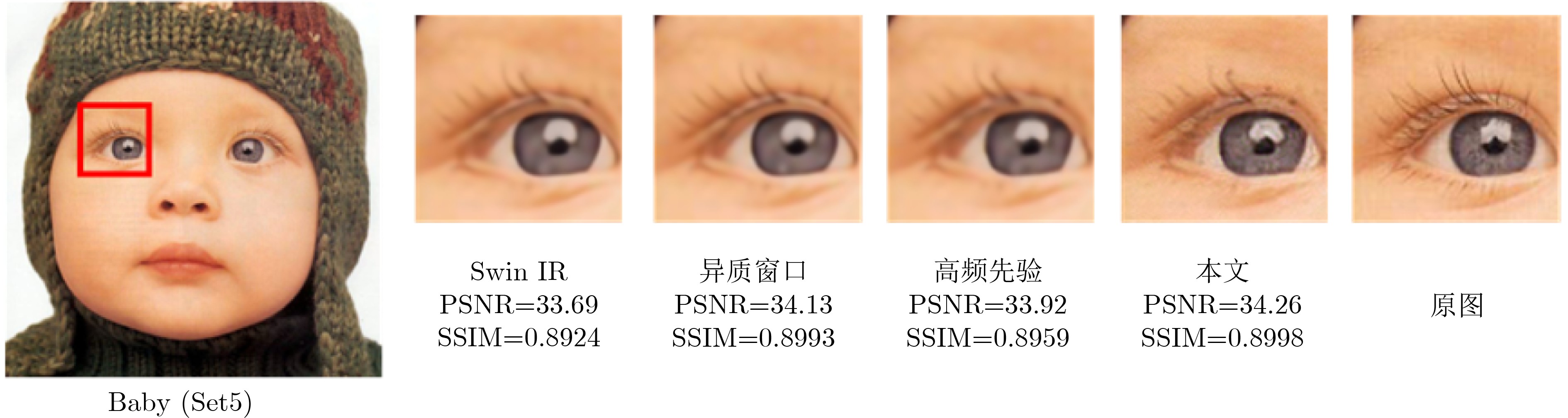
Abstract:In the era of big data, image quality varies greatly. Reconstructing high-resolution images from low-quality inputs is therefore an important task in computer vision. Existing super-resolution methods based on window self-attention, such as SwinIR, have limited receptive fields and insufficient ability to capture high-frequency details. These limitations weaken the reconstruction of fine image structures. To address these issues, this study proposes the Heterogeneous Windows Transformer Network for Image Super-Resolution (HWT-SRNet), a new architecture built on SwinIR. Through targeted module design, HWT-SRNet improves high-frequency detail extraction while expanding the receptive field, providing an effective solution for image super-resolution. Methods Based on SwinIR, this study designs two key modules to improve super-resolution reconstruction. First, the Residual Heterogeneous Windows Transformer Block (RHWTB) alternates square windows and pale-shaped windows. This design preserves local feature extraction while expanding the receptive field, enabling the network to model both fine-grained details and global structural information. The window size and alternation frequency are optimized to balance computational efficiency and feature extraction. Second, the High-Frequency Prior Feature Extraction Network (HFPFEN) is used to compensate for the limited high-frequency modeling ability of Transformer-based super-resolution models. HFPFEN extracts high-frequency prior information from images using a Difference of Gaussians (DoG) filter. The DoG filter emphasizes edges and textures by computing the difference between lightly and heavily blurred images. The extracted high-frequency information is then fused with the heterogeneous window attention mechanism. This design allows HWT-SRNet to enhance fine details while maintaining structural coherence. Because the DoG filter is applied in the spatial domain, the model can capture and reconstruct sharp edges and textures without frequency-domain transformation. Results and Discussions Experiments are conducted on five widely used benchmark datasets: Set5, Set14, BSD100, Urban100, and Manga109. HWT-SRNet is compared with representative advanced methods, including ACT, ART, and CAT. The results show superior performance across key evaluation metrics ( Table 1 ). Compared with baseline models, HWT-SRNet improves the Peak Signal-to-Noise Ratio (PSNR) by 0.10 dB to 0.37 dB, confirming its effect in improving image quality. The Structural Similarity Index Measure (SSIM) also shows consistent improvement, indicating better perceptual quality and more accurate reconstruction. Qualitative results further show that HWT-SRNet restores sharper edges, preserves textures more effectively, and reduces blurring artifacts. Ablation studies are conducted to evaluate the contributions of RHWTB and HFPFEN (Table 2 ). The results confirm that heterogeneous window attention and high-frequency prior extraction jointly improve local feature refinement and global context modeling. Therefore, HWT-SRNet provides an efficient solution for receptive field expansion and high-frequency detail reconstruction.Conclusion This paper proposes HWT-SRNet to address the limited receptive fields and insufficient high-frequency detail capture of existing super-resolution algorithms. By integrating heterogeneous window attention with high-frequency prior feature extraction, the model achieves more effective fusion of local and global features. Experimental results confirm that HWT-SRNet improves both PSNR and SSIM and outperforms representative advanced methods. However, this study does not specifically examine the model’s adaptability to noise interference in real-world scenarios. Future research can further improve the robustness of HWT-SRNet to noisy and degraded inputs and evaluate its generalization on specialized datasets, such as medical and satellite images. -
表 1 不同方法各数据集的PSNR和SSIM均值比较
算法 缩放因子 Set5 Set14 BSD100 Urban100 Manga109 PSNR/SSIM/ PSNR/SSIM PSNR/SSIM PSNR/SSIM PSNR/SSIM ESWT[8] ×2 38.33/ 0.9615 34.22/ 0.9233 32.47/ 0.9034 33.27/ 0.9397 39.79/ 0.9790 CAT-R[7] 38.48/ 0.9625 34.53/ 0.9251 32.56/ 0.9045 34.08/ 0.9443 40.09/ 0.9804 Swin IR[6] 38.42/ 0.9623 34.46/ 0.9250 32.53/ 0.9041 33.81/ 0.9427 39.92/ 0.9797 ACT[14] 38.46/ 0.9626 34.60/ 0.9256 32.56/ 0.9048 34.07/ 0.9443 39.95/ 0.9804 CRAFT[18] 38.23/ 0.9615 33.92/ 0.9211 32.33/ 0.9016 32.86/ 0.9343 39.39/ 0.9786 ART[11] 38.56/ 0.9629 34.59/ 0.9267 32.58/ 0.9048 34.30/ 0.9452 40.24/ 0.9808 DFDN[20] 38.19/ 0.9612 33.85/ 0.9199 32.30/ 0.9013 32.68/ 0.9335 —— MDIESR[21] 38.17/ 0.9613 33.83/ 0.9200 32.31/ 0.9013 32.65/ 0.9331 —— HWT-SRNet 38.59/ 0.9632 34.81/ 0.9287 32.58/ 0.9050 34.42/ 0.9453 40.25/ 0.9812 ESWT[8] ×3 34.63/ 0.9290 30.55/ 0.8464 29.23/ 0.8088 28.70/ 0.8628 34.05/ 0.9479 CAT-R[7] 34.99/ 0.9320 31.00/ 0.8539 29.49/ 0.8154 29.91/ 0.8848 35.29/ 0.9542 Swin IR[6] 34.97/ 0.9318 30.93/ 0.8534 29.46/ 0.8145 29.75/ 0.8826 35.12/ 0.9537 ACT[14] 35.03/ 0.9321 31.08/ 0.8541 29.51/ 0.8164 30.08/ 0.8858 35.27/0.954 CRAFT[18] 34.71/ 0.9295 30.61/ 0.8469 29.24/ 0.8093 28.77/ 0.8635 34.29/ 0.9491 ART[11] 35.07/ 0.9325 31.02/ 0.8541 29.51/ 0.8159 30.10/ 0.8871 35.39/ 0.9548 DFDN[20] 34.69/ 0.9293 30.55/ 0.8464 29.25/ 0.8089 28.70/ 0.8630 —— MDIESR[21] 34.69/ 0.9295 30.58/ 0.8465 29.25/ 0.8087 28.72/ 0.8634 —— HWT-SRNet 35.12/ 0.9344 31.06/ 0.8551 29.57/ 0.8173 30.18/ 0.8889 35.48/ 0.9552 ESWT[8] ×4 32.46/ 0.8979 28.80/ 0.7866 27.70/ 0.7410 26.56/ 0.8006 30.94/ 0.9136 CAT-R[7] 32.89/ 0.9044 29.13/ 0.7955 27.95/ 0.7500 27.62/ 0.8292 32.16/ 0.9269 Swin IR[6] 32.92/ 0.9044 29.09/ 0.7950 27.92/ 0.7489 27.45/ 0.8254 32.03/ 0.9260 ACT[14] 32.97/ 0.9031 29.18/ 0.7954 27.95/ 0.7507 27.74/ 0.8305 32.20/ 0.9267 CRAFT[18] 32.52/ 0.8989 28.85/ 0.7872 27.72/ 0.7418 26.56/ 0.7995 31.18/ 0.9168 ART[11] 33.04/ 0.9051 29.16/ 0.7958 27.97/ 0.7510 27.77/ 0.8321 32.31/ 0.9283 DFDN[20] 32.56/ 0.8989 28.87/ 0.7880 27.73/ 0.7414 26.59/ 0.8008 —— MDIESR[21] 32.49/ 0.8986 28.84/ 0.7867 27.73/ 0.7399 26.59/ 0.8007 —— HWT-SRNet 33.08/ 0.9060 29.23/ 0.7975 28.02/ 0.7520 27.82/ 0.8370 32.35/ 0.9296  下载: 导出CSV
下载: 导出CSV
表 2 不同方法各数据集的LPIPS均值比较(×4)
算法 Set5 Set14 BSD100 Urban100 Manga109 ESWT[8] 0.2078 0.2977 0.3383 0.2812 0.1912 CAT-R[7] 0.2061 0.2927 0.3279 0.2496 0.1819 Swin IR[6] 0.2079 0.2957 0.3321 0.2602 0.1847 ACT[14] 0.2078 0.2904 0.3235 0.2506 0.1840 CRAFT[18] 0.2136 0.3044 0.3389 0.2816 0.1920 ART[11] 0.2068 0.2913 0.3259 0.2464 0.1804 HWT-SRNet 0.2050 0.2907 0.3255 0.2448 0.1799
下载: 导出CSV
表 4 不同窗口大小对比实验结果
序号 窗口形状 窗口大小 Multi-adds(GMac) PSNR/SSIM 1 方形窗口 (8,8) 53.6 32.92/ 0.9044 (16,16) 63.8 32.98/ 0.9050 (32,32) 119.3 33.01/ 0.9051 2 栅栏形窗口 2 79.5 32.56/ 0.8989 4 82.4 32.82/ 0.9029 8 94.1 32.99/ 0.9049 16 120.3 33.01/ 0.9050 3 异质窗口 (8,8),8 81.4 33.00/ 0.9050 (8,8),16 87.5 33.01/ 0.9052 (16,16),4 73.1 32.90/ 0.9040 (16,16),8 87.0 33.03/ 0.9054
下载: 导出CSV
表 5 不同模块对比实验结果
序号 Swin IR 异质窗口 高频先验特征提取网络 PSNR/SSIM 1 √ × × 32.92/ 0.9044 2 √ √ × 33.03/ 0.9054 3 √ × √ 32.98/ 0.9049 4 √ √ √ 33.08/ 0.9060
下载: 导出CSV
-
[1] DONG Chao, LOY C C, HE Kaiming, et al. Learning a deep convolutional network for image super-resolution[C]. The 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 184–199. doi: 10.1007/978-3-319-10593-2_13. [2] DONG Chao, LOY C C, and TANG Xiaoou. Accelerating the super-resolution convolutional neural network[C]. 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 391–407. doi: 10.1007/978-3-319-46475-6_25. [3] ZHANG Yulun, LI Kunpeng, LI Kai, et al. Image super-resolution using very deep residual channel attention networks[C]. The 15th European Conference on Computer Vision, Munich, Germany, 2018: 294–310. doi: 10.1007/978-3-030-01234-2_18. [4] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[C]. The 9th International Conference on Learning Representations, Vienna, Austria, 2021: 1–21. [5] LIU Ze, LIN Yutong, CAO Yue, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]. The 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, Canada, 2021: 9992–10002. doi: 10.1109/ICCV48922.2021.00986. [6] LIANG Jingyun, CAO Jiezhang, SUN Guolei, et al. SwinIR: Image restoration using Swin transformer[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, Canada, 2021: 1833–1844. doi: 10.1109/ICCVW54120.2021.00210. [7] CHEN Zheng, ZHANG Yulun, GU Jinjin, et al. Cross aggregation transformer for image restoration[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1847. [8] SHI Jinpeng, LI Hui, LIU Tianle, et al. Image super-resolution using efficient striped window transformer[EB/OL]. https://arxiv.org/abs/2301.09869, 2023. [9] WU Sitong, WU Tianyi, TAN Haoru, et al. Pale transformer: A general vision transformer backbone with pale-shaped attention[C]. The 36th AAAI Conference on Artificial Intelligence, Palo Alto, USA, 2022: 2731–2739. doi: 10.1609/aaai.v36i3.20176. [10] WU Gang, JIANG Junjun, JIANG Kui, et al. Content-aware transformer for all-in-one image restoration[EB/OL]. https://arxiv.org/abs/2504.04869v1, 2025. [11] ZHANG Jiale, ZHANG Yulun, GU Jinjin, et al. Accurate image restoration with attention retractable transformer[C]. The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 2023: 1–13. [12] CHEN Zheng, ZHANG Yulun, GU Jinjin, et al. Recursive generalization transformer for image super-resolution[C]. The Twelfth International Conference on Learning Representations, Vienna, Austria, 2024: 1–12. [13] CHU Shuchuan, DOU Zhichao, PAN J S, et al. HMANet: Hybrid multi-axis aggregation network for image super-resolution[C].The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, USA, 2024: 6257–6266. doi: 10.1109/CVPRW63382.2024.00629. [14] YOO J, KIM T, LEE S, et al. Enriched CNN-transformer feature aggregation networks for super-resolution[C]. The 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, USA, 2023: 4945–4954. doi: 10.1109/WACV56688.2023.00493. [15] SI Chenyang, YU Weihao, ZHOU Pan, et al. Inception transformer[C]. The 36th International Conference on Neural Information Processing Systems, New Orleans, USA, 2022: 1707. [16] KORKMAZ C, TEKALP A M, and DOGAN Z. Training generative image super-resolution models by wavelet-domain losses enables better control of artifacts[C]. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, USA, 2024: 5926–5936. doi: 10.1109/CVPR52733.2024.00566. [17] 韩玉兰, 崔玉杰, 罗轶宏, 等. 基于密集残差和质量评估引导的频率分离生成对抗超分辨率重构网络[J]. 电子与信息学报, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388.HAN Yulan, CUI Yujie, LUO Yihong, et al. Frequency separation generative adversarial super-resolution reconstruction network based on dense residual and quality assessment[J]. Journal of Electronics & Information Technology, 2024, 46(12): 4563–4574. doi: 10.11999/JEIT240388. [18] LI Ao, ZHANG Le, LIU Yun, et al. Feature modulation transformer: Cross-refinement of global representation via high-frequency prior for image super-resolution[C]. The 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2023: 12480–12490. doi: 10.1109/iccv51070.2023.01150. [19] YAO Hongdou, HAN Pengfei, WANG Xiaofen, et al. Super-resolution via hierarchical attention and detail enhancement transformer network[J]. Optics & Laser Technology, 2025, 188: 112836. doi: 10.1016/j.optlastec.2025.112836. [20] 程德强, 袁航, 钱建生, 等. 基于深层特征差异性网络的图像超分辨率算法[J]. 电子与信息学报, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179.CHENG Deqiang, YUAN Hang, QIAN Jiansheng, et al. Image super-resolution algorithms based on deep feature differentiation network[J]. Journal of Electronics & Information Technology, 2024, 46(3): 1033–1042. doi: 10.11999/JEIT230179. [21] 寇旗旗, 刘规, 江鹤, 等. 基于多域信息增强的轻量级图像超分辨率网络[J]. 通信学报, 2025, 46(4): 144–159. doi: 10.11959/j.issn.1000-436x.2025059.KOU Qiqi, LIU Gui, JIANG He, et al. Lightweight image super-resolution network based on muti-domain information enhancement[J]. Journal on Communications, 2025, 46(4): 144–159. doi: 10.11959/j.issn.1000-436x.2025059. [22] WANG Xintao, XIE Liangbin, DONG Chao, et al. Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data[C]. The 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, Canada, 2021: 1905–1914. doi: 10.1109/ICCVW54120.2021.00217. [23] WANG Yufei, YANG Wenhan, CHEN Xinyuan, et al. SinSR: Diffusion-based image super-resolution in a single step[C]. The 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, 2024: 25796–25805. doi: 10.1109/CVPR52733.2024.02437. -

 下载:
下载:





图(7) / 表(5)
计量
- 文章访问数: 162
- HTML全文浏览量: 141
- PDF下载量: 23
- 被引次数: 0
