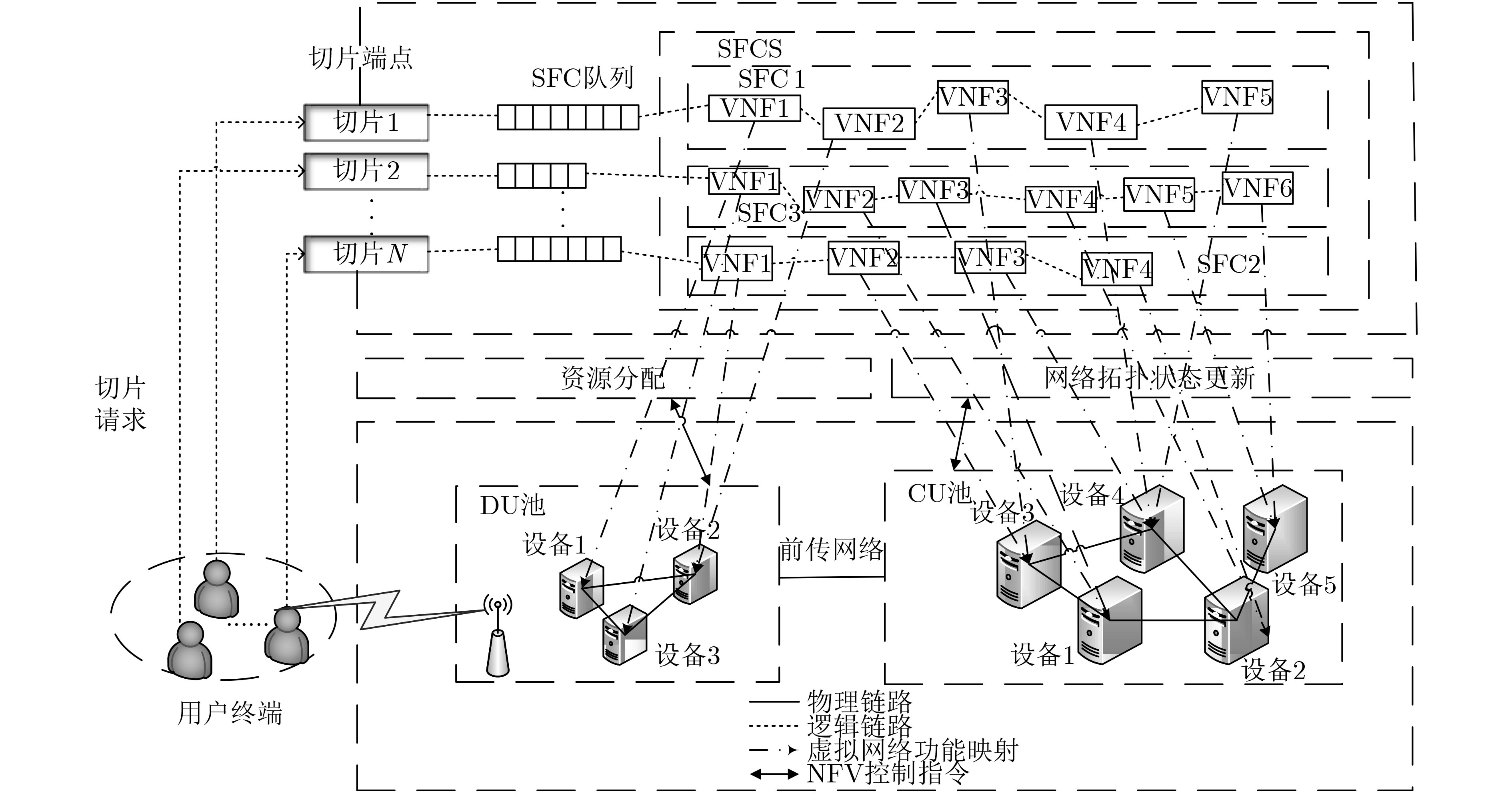
图
1
系统架构
| Citation: | Lun TANG, Xiaoyu HE, Xiao WANG, Qianbin CHEN. Deployment Algorithm of Service Function Chain Based on Transfer Actor-Critic Learning[J]. Journal of Electronics & Information Technology, 2020, 42(11): 2671-2679. doi: 10.11999/JEIT190542

|
网络切片是指将一个完整的物理网络切割成为多个独立的适用不同应用场景的逻辑虚拟网络。每个切片网络包含有若干条相同服务类型的服务功能链(Service Function Chain, SFC),每条SFC由若干有序虚拟网络功能(Virtual Network Function, VNF)组成。系统需要根据用户需求和相关约束,合理地将VNF放置在底层网络并为其分配CPU、内存、带宽等物理资源[1]。
目前,大多数研究都是以成本最小化为目标,将端到端时延作为约束条件。文献[2]旨在最小化运营成本中的激活、能耗和传输成本,得到VNF部署和路由分配优化方案。文献[3]考虑时变工作负载和实例化VNF的基本资源消耗,以优化资源利用率。文献[4]和文献[5]都提出了时延感知的优化算法来保证端到端时延,但是把各类时延设为固定值,与资源分配无关。文献[6]针对核心网切片的SFC部署,最大限度减少VNF调度时延,使得运营商能够服务更多用户。首先,上述文献的方案只针对核心网切片,无法直接支持在基于集中式单元/分布式单元(Centralized Unit/Distributed Unit, CU/DU)的两级云无线接入网(Cloud-Radio Access Network, C-RAN)架构下的SFC部署[7]。其次,这些方案忽略了实际网络中动态随机变化的业务到达和队列积压情况,如果不及时针对当前环境进行方案调整,系统端到端时延会显著增加。此外,上述算法均只针对某一特定的网络参数配置,即SFC数目、业务数据包到达率等设置固定,一旦这些参数发生变化,其求解策略将无法适应新网络,需要对算法本身进行调整。
针对上述问题,本文提出了一种基于迁移演员-评论家算法(Transfer Actor-Critic Algorithm, TACA)的面向时延优化的接入网切片SFC部署方案。主要贡献包括:
(1) 考虑采用基于CU/DU的两级C-RAN架构,以最小化系统端到端时延为目标,建立排队时延、节点处理时延及链路传输时延与VNF放置和资源分配的关联性;
(2) 考虑环境中SFC业务请求数据包到达的随机性和队列长度的动态性,将SFC的部署问题建立为马尔可夫决策过程(Markov Decision Process, MDP),并通过A-C算法不断与环境进行交互实现SFC部署策略的动态调整;
(3) 考虑一个系统在不同时段SFC的部署任务不尽相同,如在目标任务中需部署SFC条数较少但业务数据包到达率更高。为了降低针对目标任务模型的训练成本,提高学习的效果,在传统A-C学习中引入迁移学习的思想,实现利用源任务中的部署知识来学习新的部署策略。
图1所示为基于5G C-RAN上行条件的SFC部署的系统架构图。首先,网络中的各协议层功能在通用设备被虚拟化为不同的VNF,共享基础设施资源。其次,该架构采用DU和CU独立部署的方式,DU池和CU池之间通过下一代前传网络接口(Next Generation Fronthaul Interface, NGFI)进行数据传输。
在5G C-RAN上行链路中,3GPP总结了8种接入网切片的VNF放置方式。切片一旦选择某种VNF放置方式,即意味着SFC部署在CU池和DU池的VNF数量确定,基于此,再进行VNF放置节点的选择以及池内计算资源和链路资源分配。此外,不同的VNF放置方式对SFC的最大可容忍NGFI传输时延要求不同,因此放置方式还会影响SFC的NGFI带宽资源分配。本文中将接入网切片的VNF放置和资源分配方式统称为SFC部署策略。
用带权无向图
本文将系统的时间维度分为若干个时隙,用
首先,假定每台设备包含有多个CPU,单个CPU的计算能力为
| τ1(t)=∑k∈K∑m∈Mk∑j∈Fm,k∑nu∈N′fjm,kxfjm,knu⋅wk,m(t)cfjm,knu(t) | (1) |
然后,令
| τ2(t)=∑k∈K∑m∈Mk(23ak,m(t)⋅¯pk,mbfm,kNG(t)+∑j∈F′m,k∑lv∈Lyfjm,klv⋅ak,m(t)⋅¯pk,mbfjm,klv(t)) | (2) |
最后,令
| τ3(t)=∑k∈K∑m∈Mkqk,m(t)λk,m(t) | (3) |
从而时隙
| τ=limT→∞1TE{T∑t=0τ(t)} | (4) |
本文的接入网切片SFC部署问题可建立为基于VNF放置选择、计算资源、链路带宽资源和NGFI带宽资源联合分配的时延最小化数学模型
| minaop(t),αc(t),αb(t){τ}s.t.∀k∈K,∀m∈Mk,∀j∈Fm,k,∀nu∈N,∀lv∈LC1:∑k∈K∑m∈Mk∑j∈Fm,kxfjm,knu⋅cfjm,knu≤CnuC2:∑k∈K∑m∈Mk∑j∈F′m,kyfjm,klv⋅bfjm,klv≤BlvC3:∑k∈K∑m∈Mkyfm,kNGFI⋅bfm,kNGFI≤BNGFIC4:∑nu∈N′fjm,kxfjm,knu=1C5:∑lv∈Lyfjm,klv≤1C6:xfjm,knu=∑nu=lv.headyfjm,klvC7:xfjm,knu=∑nu=lv.tailyfj−1m,klvC8:xfjm,knu⋅cfjm,knu=cfjm,knuC9:yfjm,klv⋅bfjm,klv=bfjm,klv} | (5) |
上述约束条件中,C1表示任意物理节点上的计算资源限制。C2和C3分别代表任意物理链路和NGFI上的带宽资源限制。C4确保任意VNF只能实例化在一个物理节点上。C5确保任意VNF至多只能选择一条链路发送数据。C6和C7代表SFC上相邻的两个VNF若部署在不同的物理节点上,则这两个节点必须相邻。C8和C9分别代表只有当SFC的虚拟节点映射到物理节点、虚拟链路映射到物理链路时,才分配计算资源和带宽资源。
上述VNF放置以及资源分配过程可以建立为一个具有连续状态和动作空间的离散时间MDP[13]。MDP定义为一个多元组
由于本文动作空间也连续,因此假设动作
解决MDP的许多方法都依赖于环境动态变化的先验知识,然而要提前精确获知未来的队列长度和数据包到达率很困难,因此本文采用无需先验知识的A-C学习方法来解决MDP问题。在A-C学习中,状态-动作值函数
| Qπ(s,a)=Eπ{∞∑t=1βtRt|s(1)=s,a(1)=a}=E{Rt+βQπ(s(t+1),a(t+1))} | (6) |
其中,
A-C学习的目标是寻找一个策略
| J(π)=Eπ{Qπ(s,a)}=∫Sdπ(s)∫Aπ(a|s)Qπ(s,a)dads | (7) |
其中,
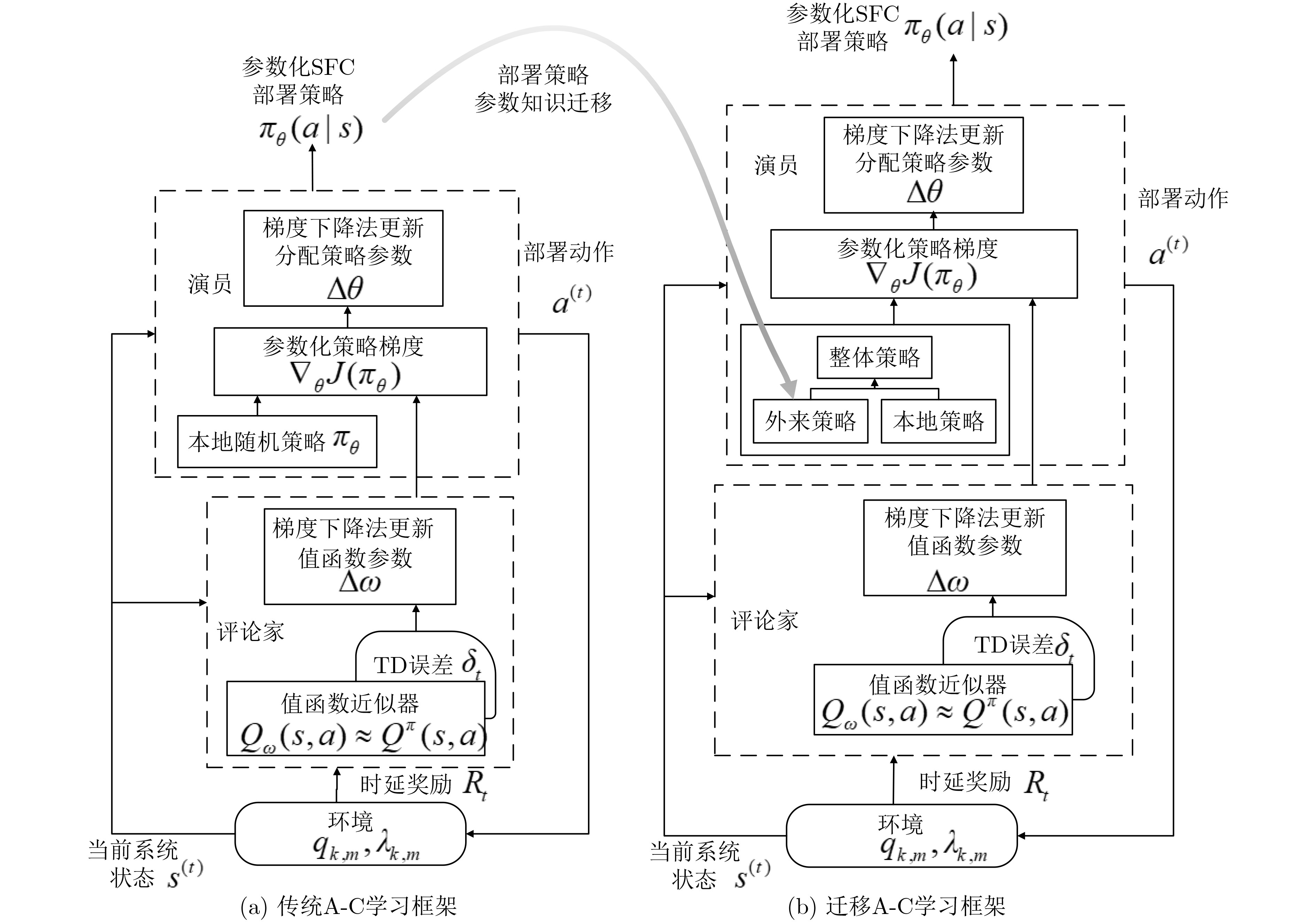
A-C学习算法结合了强化学习中的策略方案和值函数方案,能够在连续动作空间中有效学习随机策略,并获得较好的收敛性[14]。算法框架如图2(a)所示。其中演员定义随机参数化策略并根据环境中的队列长度和数据包到达情况生成SFC部署动作。而后评论家根据执行部署动作后获得的时延奖励对当前策略进行评判,并通过时间差分(Time Difference, TD)误差更新值函数。在评论家部分完成值函数近似和参数更新后,演员使用评论家的输出更新其策略,以选择所获奖励更多的动作。
在演员阶段,首先采用向量
| Δθ=εa,t∇θJ(πθ) | (8) |
其中,
| ∇θJ(πθ)=∫Sdπ(s)∫A∇θπθ(s,a)Qπθ(s,a)dads | (9) |
采用高斯分布[15]构造动作选择的随机策略,参数化策略写为
| Z(s)=(q11,···,q1M1,q21,···,q2M2,···,q|K|1,···,q|K|M|K|,λ11,···,λ1M1,λ21,···,λ2M2,···,λ|K|1,···,λ|K|M|K|)T | (10) |
评论家部分具有评估策略优劣的能力。由于本文中状态和动作空间无限,
| Qω(s,a)=ωT⋅Ψ(s,a)=n∑j=1ωjψj(s,a) | (11) |
其中,
而后,给出状态转移样本
| δt=Rt+1+βQω(s(t+1),a(t+1))−Qω(s(t),a(t)) | (12) |
采用梯度下降法近似真实值函数,并在梯度方向上不断更新近似值。由于采用线性函数近似器,
| Δω=εc,tδtΨ(s,a) | (13) |
式(9)所示的策略梯度公式表明了演员过程(策略梯度
| ∇θlnπθ(s,a)=(a−μ(s))⋅Z(s)σ2 | (14) |
采用策略梯度近似可能会引起一定偏差,因此不能保证采用该有偏差的策略梯度能够找到最优解。为了避免偏差实现精确策略梯度,需要对值函数近似值采用相容特征并最小化误差,其中相容特征满足
由于本文采用线性近似器,即
| Ψ(s,a)=∇θlnπθ(s,a) | (15) |
根据相容特征公式,可得值函数
但是,采用相容近似的梯度策略梯度法仍然存在方差较大的问题。为了有效降低梯度计算中的方差,进一步提高评论家函数近似精度,引入优势函数
同理,需采用线性函数近似器对状态值函数进行估计
| Vυ(s)=υT⋅Z(s) | (16) |
状态值函数参数向量的更新过程类似于状态-动作值函数,即
| δυt=Rt+1+βVυ(s(t+1))−Vυ(s(t)) | (17) |
| Δυ=εc,tδvtZ(s) | (18) |
| ∇θJ(πθ)=∫Sdπ(s)∫A∇θπθ(s,a)A⋅(s(t+1),a(t+1))dads | (19) |
在本节中,为了实现并加速该A-C学习算法在其他相似环境和学习任务中的收敛过程,考虑利用源任务学习到的SFC部署知识来寻找目标任务中时延最优的SFC部署策略。当学习过程收敛时,在特定状态下选择特定动作的机率比其他动作大得多,但这样的一个学习策略是适应当前环境和部署任务的,现在考虑将该部署策略的参数知识
在TACA中,整体策略
| πo(t+1)θ(s(t),a(t))=(1−ζ(t))πn(t+1)θ(s(t),a(t))+ζ(t)πe(t+1)θ(s(t),a(t)) | (20) |
其中,
| 输入:高斯策略πθ(s,a)∼N(μ(s),σ2),以及其梯度∇θlnπθ(s,a),状态分布dπ(s),学习率εa,t和εc,t,折扣因子β |
| (1) for epsoide=0,1,2,···,Epmax do |
| (2) 初始化:策略参数向量θt,状态-动作值函数参数向量ωt,状态值函数参数向量υt,初始状态s0∼dπ(s),本地部署策略πnθ(s,a),外 来迁移部署策略πeθ(s,a) |
| (3) for 回合每一步t=0,1,···,Tdo |
| (4) 由式(20)得到整体部署策略,遵循整体策略πθ(s,a)选择动作a(t),进行VNF放置和资源分配,而后更新环境状态s(t+1),并得到立即 奖励Rt=−τ(t) |
| (5) end for |
| (6) 评论家过程: |
| (a) 计算相容特征:由式(10)得处于状态s的基函数向量,结合式(14),式(15)得相容特征 |
| (b) 相容近似:由式(11)得状态-动作值函数近似,由式(16)得状态值函数近似 |
| (c) TD误差计算:由式(12),式(17)分别得状态-动作值函数、状态值函数的TD误差 |
| (d) 更新评论家参数:由式(13)得状态-动作值函数参数向量更新,由式(18)得状态值函数参数向量更新 |
| (7) 演员过程: |
| (a) 计算优势函数 |
| (b) 重写策略梯度:代入优势函数由式(19)得策略梯度 |
| (c) 更新演员参数:由式(8)得策略参数向量更新 |
| (8) end for |
为了评估本文模型与算法的有效性,利用Tensorflow和Matlab工具进行了仿真。假设有3个不同服务规模的接入网切片,数据包到达服从泊松分布且到达率分别为:
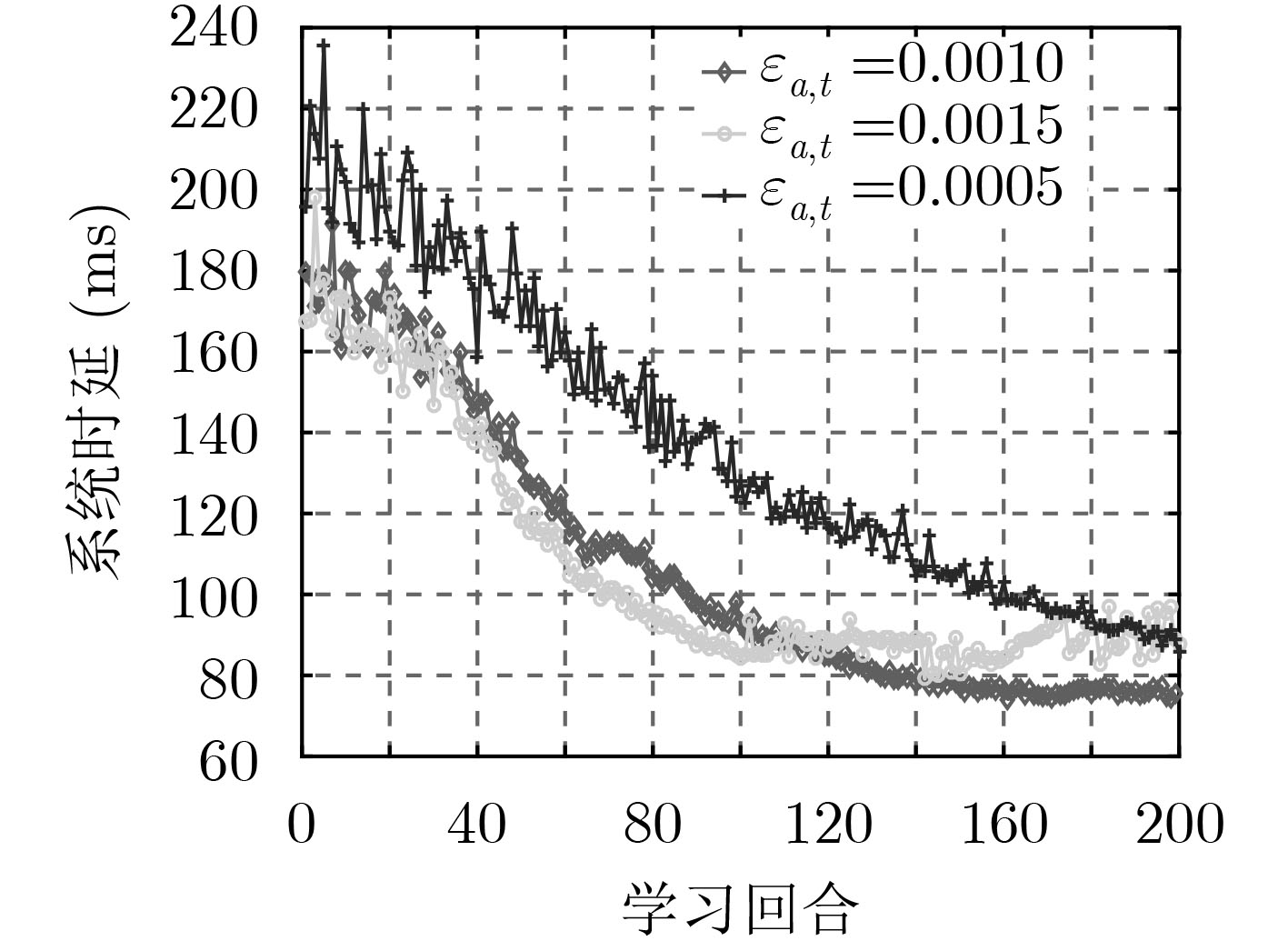
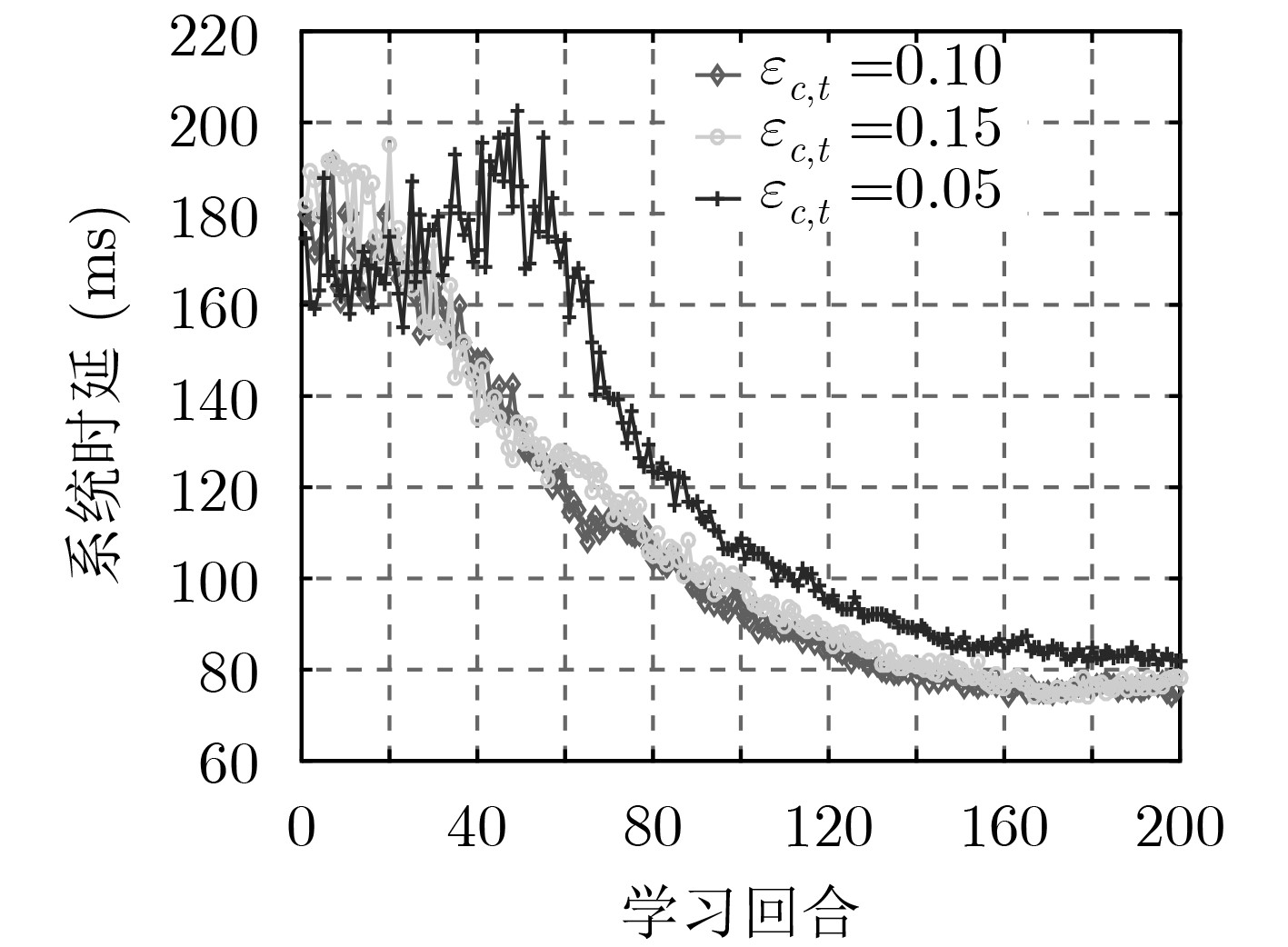
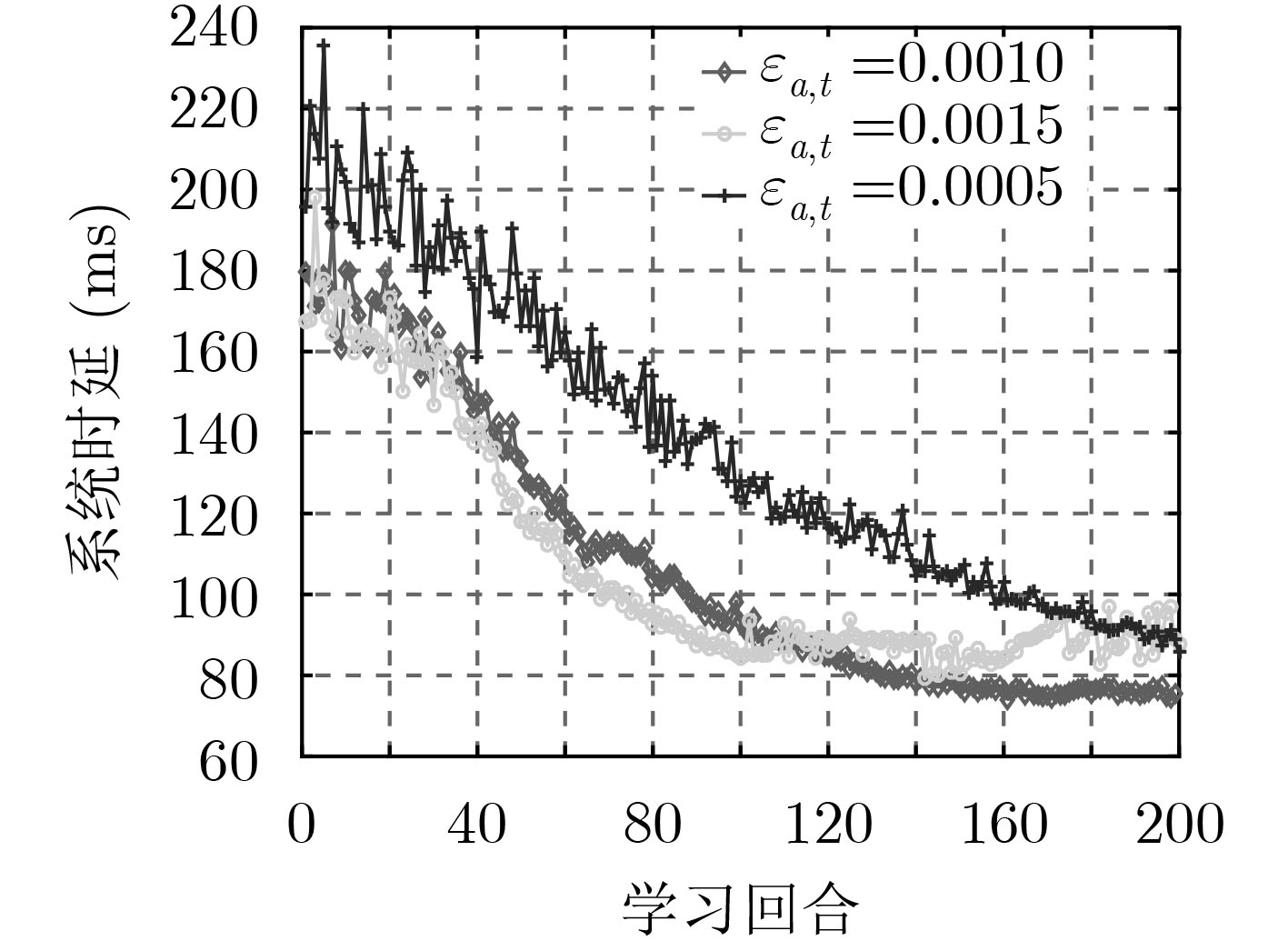
为了讨论方便,先将系统中SFC总数量设置为50。首先,采用不同的学习率会影响A-C学习的收敛性能。如图3、图4所示,图3固定评论家学习率
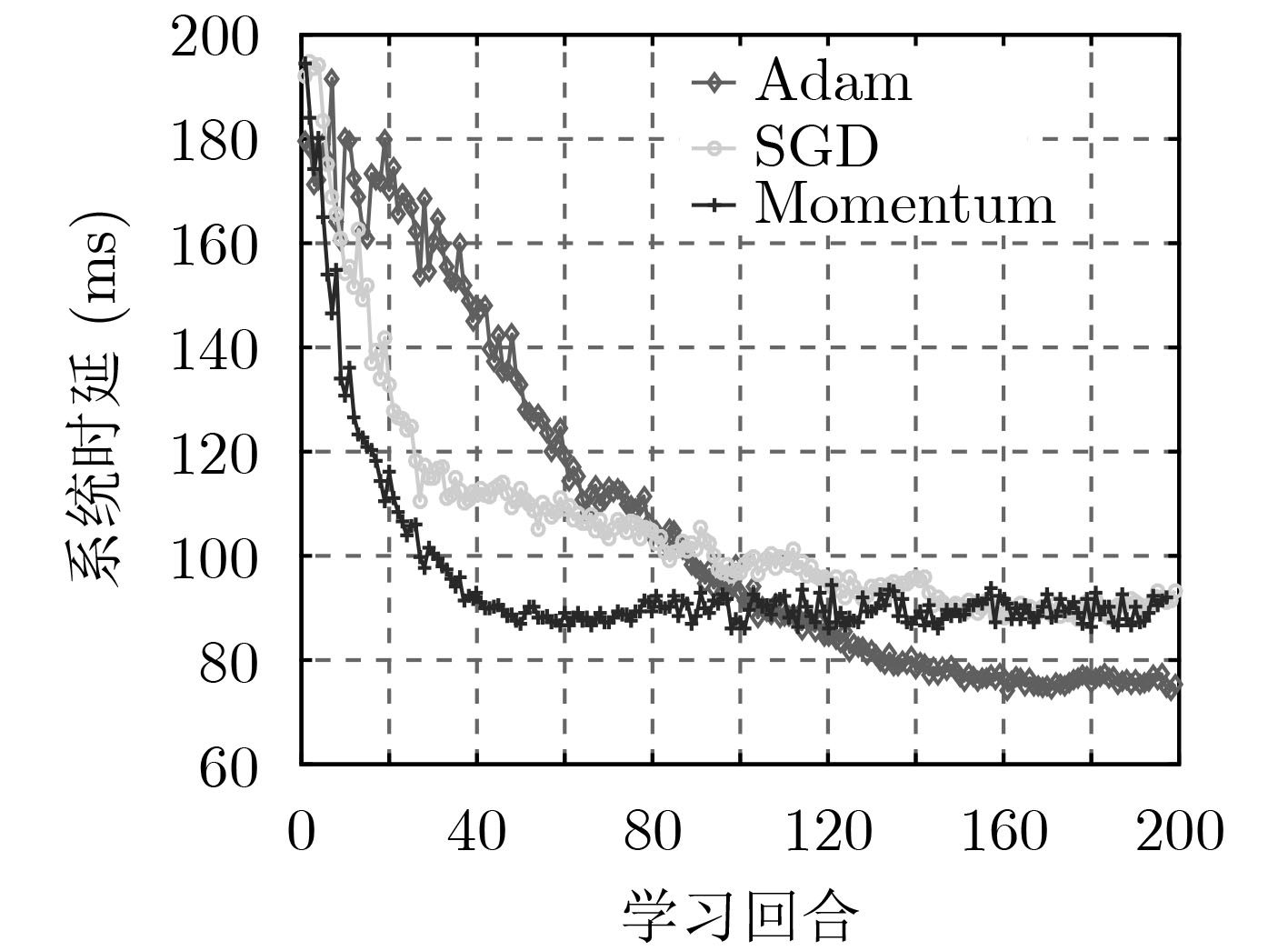
采用不同优化器也会对A-C算法的收敛性能产生一定的影响。本文采用最常用的3种优化器进行比较,分别是随机梯度下降优化器(Stochastic Gradient Descent optimizer, SGD)、动量优化器(Momemtum optimizer)以及Adam优化器。如图5所示,在前100个回合中,Adam曲线的收敛速度优于另外两个优化器,但就最终收敛效果而言,Adam的系统时延收敛值更低且震荡幅度更小。这是因为SGD和Momentum在参数向量更新过程中都是固定学习率,而Adam却能够动态调整各个参数的学习率。
接下来,将从队列稳定性方面评估该算法。如图6,随着学习过程的进行,尽管系统中的切片数据包到达率持续变化,但切片的队列积压情况会逐渐改善并最终收敛到一个较小的范围。这说明本文算法能够很好地实现与环境的交互,在每个学习回合中根据不断变化的数据包到达率逐步动态调整SFC的部署策略,稳定并减小队列积压。
图7所示为VNF放置方式的选择频率与切片服务数据规模的关系。仿真参数中已设置切片3服务数据规模最大,其次是切片2,切片1最小。由图7可知,切片3选择方式3的频率最高,其次是方式4。这是因为这两种VNF放置方式对前传网络的传输时延要求较为宽松,能够减小切片对NGFI的带宽资源消耗。切片2的数据服务规模适中,选择方式5的频率较高,说明其可以适当选择时延较为严格的VNF放置方式。切片1对NGFI带宽资源的依赖性最小,因此选择方式7的频率最高。
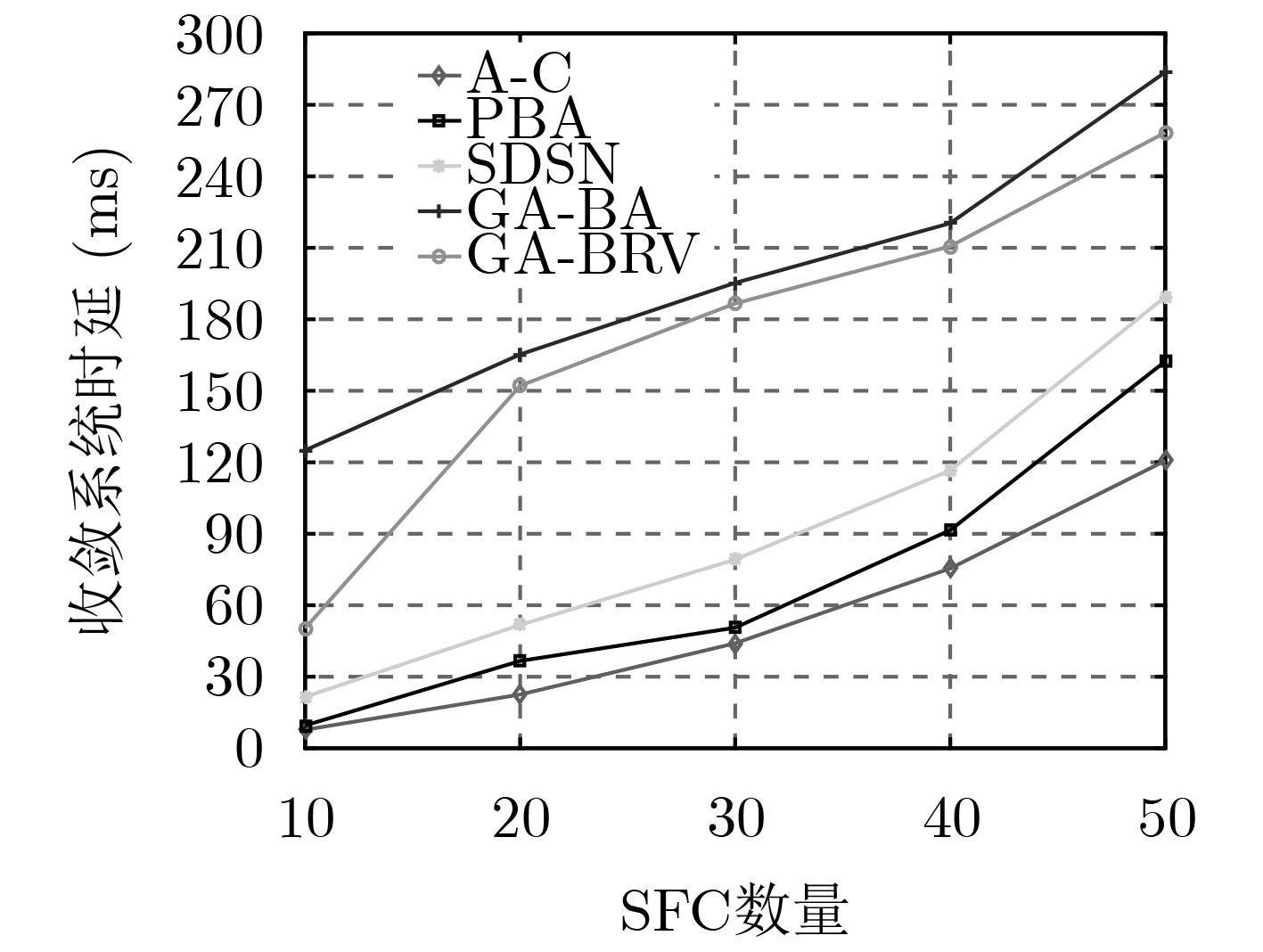
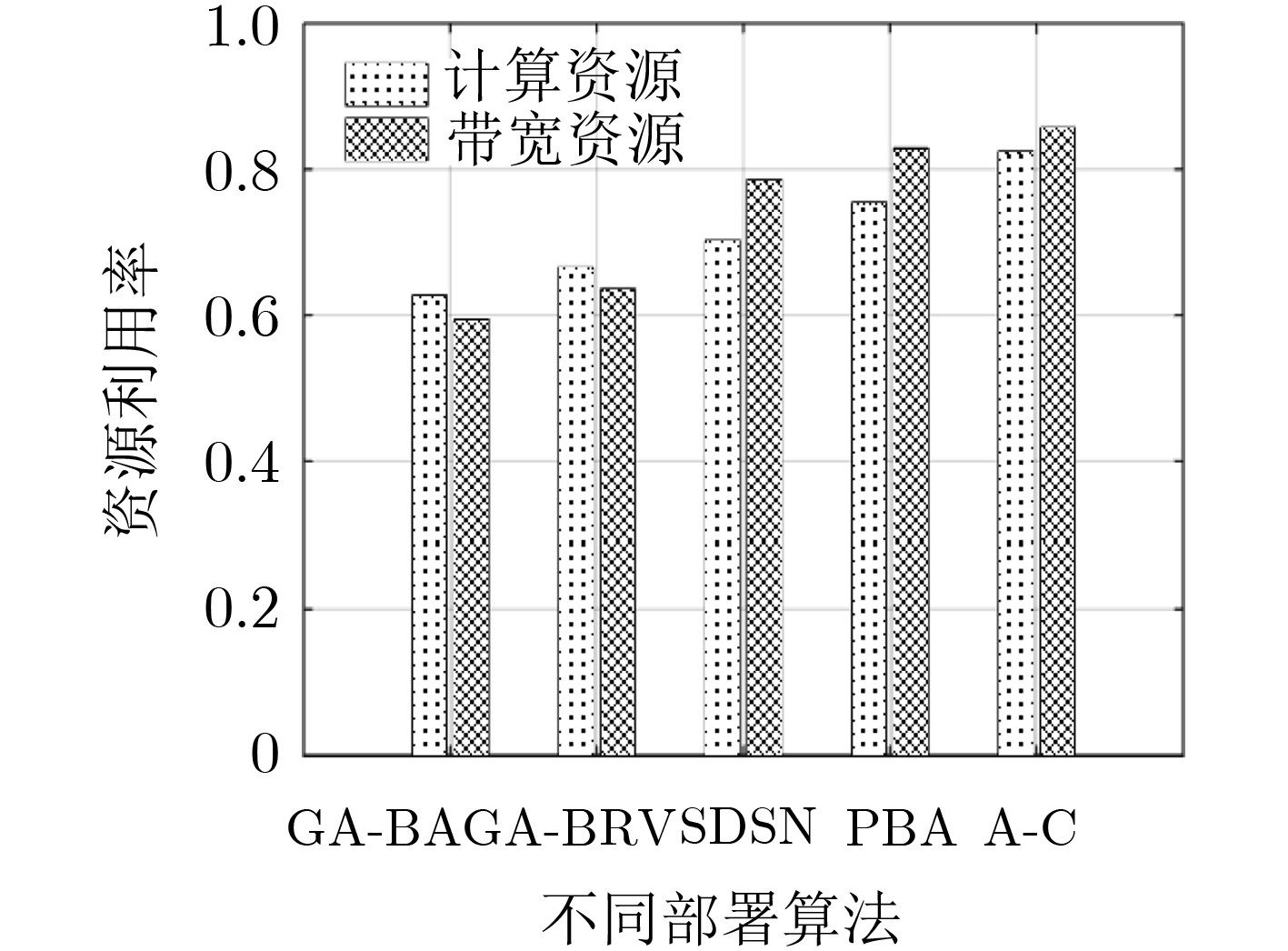
为了更好地体现本文算法的性能,对比了文献[7]中的两种蚁群算法(Genetic Algorithm, GA),文献[6]的卫星网络SFC部署算法(SFC Deployment in Satelite Network, SDSN),以及仅基于策略梯度的强化学习算法(Policy-Based Algorithm, PBA)。如图8、图9所示,本文所提基于A-C学习的SFC部署算法的系统收敛时延效果和资源利用率都明显优于其他几种方案。其中,GA方案容易陷入局部最优解,SDSN方案忽略了资源的分配与各类时延之间的关联性,PBA方案在评价策略时不如A-C算法高效且方差较大。而本文所提基于A-C学习的SFC部署算法,结合了基于值函数和基于策略梯度两种方法,使得学习过程更加高效,并且将各类时延与资源分配建立关联,使得资源的分配更为合理。
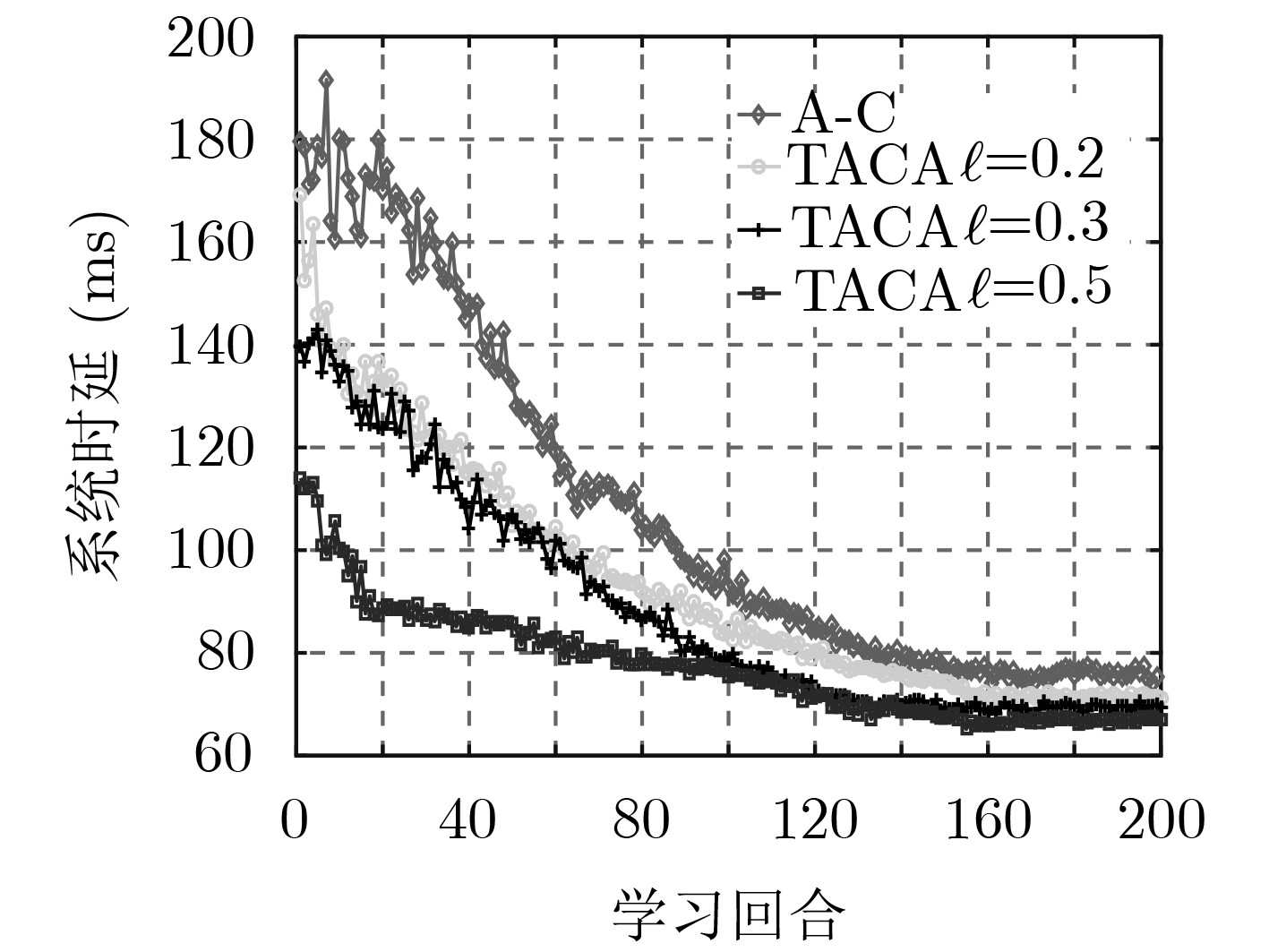
最后,保持系统中的SFC总数量仍为50,但是3个切片的SFC数量比例改为4:4:2,且调换切片1和切片2的数据包到达率设置,切片3保持不变。如图10所示,TACA由于有相似任务的外来策略知识,因此在仿真中尤其是即刚开始的学习回合中,相比于传统A-C算法,其时延曲线波动明显更小,且迁移率因子越大,其收敛速度越快,最后学习回合结束时的收敛效果也更好。
本文考虑在5G接入网DU/CU架构下,考虑实际网络中业务请求的随机性和未知性,针对SFC部署的系统端到端时延问题,提出了基于A-C学习的SFC部署方案。在该方案中,建立了以动态变化的队列长度和数据包到达率作为状态空间的MDP模型,并通过A-C学习算法求解,实现自适应动态调整SFC部署,优化系统总时延。同时,为了更进一步实现并提升该A-C学习算法在其他相似任务上的收敛性,引入迁移学习思想并提出了TACA算法。仿真结果表明,该种基于迁移A-C学习的SFC部署算法能够很好地与网络环境进行交互并适应环境的动态变化,提升整个网络的时延性能,更加高效地利用网络资源。
|
AGARWAL S, MALANDRINO F, CHIASSERINI C F, et al. VNF placement and resource allocation for the support of vertical services in 5G networks[J]. IEEE/ACM Transactions on Networking, 2019, 27(1): 433–446. doi: 10.1109/TNET.2018.2890631
|
|
史久根, 张径, 徐皓, 等. 一种面向运营成本优化的虚拟网络功能部署和路由分配策略[J]. 电子与信息学报, 2019, 41(4): 973–979. doi: 10.11999/JEIT180522
SHI Jiugen, ZHANG Jing, XU Hao, et al. Joint optimization of virtualized network function placement and routing allocation for operational expenditure[J]. Journal of Electronics &Information Technology, 2019, 41(4): 973–979. doi: 10.11999/JEIT180522
|
|
LI Defang, HONG Peilin, XUE Kaiping, et al. Virtual network function placement considering resource optimization and SFC requests in cloud datacenter[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29(7): 1664–1677. doi: 10.1109/TPDS.2018.2802518
|
|
PEI Jianing, HONG Peilin, and LI Defang. Virtual network function selection and chaining based on deep learning in SDN and NFV-Enabled networks[C]. 2018 IEEE International Conference on Communications Workshops, Kansas City, USA, 2018: 1–6. doi: 10.1109/ICCW.2018.8403657.
|
|
CAI Yibin, WANG Ying, ZHONG Xuxia, et al. An approach to deploy service function chains in satellite networks[C]. NOMS 2018–2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, China, 2018: 1–7. doi: 10.1109/NOMS.2018.8406159.
|
|
QU Long, ASSI C, and SHABAN K. Delay-aware scheduling and resource optimization with network function virtualization[J]. IEEE Transactions on Communications, 2016, 64(9): 3746–3758. doi: 10.1109/TCOMM.2016.2580150
|
|
陈前斌, 杨友超, 周钰, 等. 基于随机学习的接入网服务功能链部署算法[J]. 电子与信息学报, 2019, 41(2): 417–423. doi: 10.11999/JEIT180310
CHEN Qianbin, YANG Youchao, ZHOU Yu, et al. Deployment algorithm of service function chain of access network based on stochastic learning[J]. Journal of Electronics &Information Technology, 2019, 41(2): 417–423. doi: 10.11999/JEIT180310
|
|
PHAN T V, BAO N K, KIM Y, et al. Optimizing resource allocation for elastic security VNFs in the SDNFV-enabled cloud computing[C]. 2017 International Conference on Information Networking, Da Nang, Vietnam, 2017: 163–166. doi: 10.1109/ICOIN.2017.7899497.
|
|
XIA Weiwei and SHEN Lianfeng. Joint resource allocation using evolutionary algorithms in heterogeneous mobile cloud computing networks[J]. China Communications, 2018, 15(8): 189–204. doi: 10.1109/CC.2018.8438283
|
|
ZHU Zhengfa, PENG Jun, GU Xin, et al. Fair resource allocation for system throughput maximization in mobile edge computing[J]. IEEE Access, 2018, 6: 5332–5340. doi: 10.1109/ACCESS.2018.2790963
|
|
MAO Yuyi, ZHANG Jun, and LETAIEF K B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices[J]. IEEE Journal on Selected Areas in Communications, 2016, 34(12): 3590–3605. doi: 10.1109/JSAC.2016.2611964
|
|
MEHRAGHDAM S, KELLER M, and KARL H. Specifying and placing chains of virtual network functions[C]. The 3rd IEEE International Conference on Cloud Networking, Luxembourg, Luxembourg, 2014: 7–13. doi: 10.1109/CloudNet.2014.6968961.
|
|
HAGHIGHI A A, HEYDARI S S, and SHAHBAZPANAHI S. MDP modeling of resource provisioning in virtualized content-delivery networks[C]. The 25th IEEE International Conference on Network Protocols, Toronto, Canada, 2017: 1–6. doi: 10.1109/ICNP.2017.8117600.
|
|
GRONDMAN I, BUSONIU L, LOPES G A D, et al. A survey of actor-critic reinforcement learning: Standard and natural policy gradients[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews)
|
|
LEE D H and LEE J J. Incremental receptive field weighted actor-critic[J]. IEEE Transactions on Industrial Informatics, 2013, 9(1): 62–71. doi: 10.1109/TII.2012.2209660
|
|
LI Rongpeng, ZHAO Zhifeng, CHEN Xianfu, et al. TACT: A transfer actor-critic learning framework for energy saving in cellular radio access networks[J]. IEEE Transactions on Wireless Communications, 2014, 13(4): 2000–2011. doi: 10.1109/TWC.2014.022014.130840
|
|
KOUSHI A M, HU Fei, and KUMAR S. Intelligent spectrum management based on transfer actor-critic learning for rateless transmissions in cognitive radio networks[J]. IEEE Transactions on Mobile Computing, 2018, 17(5): 1204–1215. doi: 10.1109/TMC.2017.2744620
|
| 1. | 母军臣,何洪辉. 基于强化学习的激光导航无人车路径跟踪控制. 沈阳工业大学学报. 2024(02): 206-211 .  | |
| 2. | 陈前斌,麻世庆,段瑞吉,唐伦,梁承超. 基于迁移深度强化学习的低轨卫星跳波束资源分配方案. 电子与信息学报. 2023(02): 407-417 .  本站查看 本站查看 | |
| 3. | 黄新林,郑人华. 基于强化学习的802.11ax上行链路调度算法. 电子与信息学报. 2022(05): 1800-1808 . 本站查看 | |
| 4. | 周楠,张平,郑征,陈明昊,樊冰. 基于机器学习的电力通信网带宽分配算法. 电网与清洁能源. 2021(05): 67-73 . | |
| 5. | 陆旭,陈影,许中平,王伟,刘文龙,陈明昊. 面向电力-通信网融合与时延优化的服务功能链部署方法. 电力系统保护与控制. 2021(22): 43-50 . | |
| 6. | 宿帅,朱擎阳,魏庆来,唐涛,阴佳腾. 基于DQN的列车节能驾驶控制方法. 智能科学与技术学报. 2020(04): 372-384 . |

Figures(10) / Tables(1)
Lun TANG, Xiaoyu HE, Xiao WANG, Qianbin CHEN. Deployment Algorithm of Service Function Chain Based on Transfer Actor-Critic Learning[J]. Journal of Electronics & Information Technology, 2020, 42(11): 2671-2679. doi: 10.11999/JEIT190542

| 输入:高斯策略πθ(s,a)∼N(μ(s),σ2),以及其梯度∇θlnπθ(s,a),状态分布dπ(s),学习率εa,t和εc,t,折扣因子β |
| (1) for epsoide=0,1,2,···,Epmax do |
| (2) 初始化:策略参数向量θt,状态-动作值函数参数向量ωt,状态值函数参数向量υt,初始状态s0∼dπ(s),本地部署策略πnθ(s,a),外 来迁移部署策略πeθ(s,a) |
| (3) for 回合每一步t=0,1,···,Tdo |
| (4) 由式(20)得到整体部署策略,遵循整体策略πθ(s,a)选择动作a(t),进行VNF放置和资源分配,而后更新环境状态s(t+1),并得到立即 奖励Rt=−τ(t) |
| (5) end for |
| (6) 评论家过程: |
| (a) 计算相容特征:由式(10)得处于状态s的基函数向量,结合式(14),式(15)得相容特征 |
| (b) 相容近似:由式(11)得状态-动作值函数近似,由式(16)得状态值函数近似 |
| (c) TD误差计算:由式(12),式(17)分别得状态-动作值函数、状态值函数的TD误差 |
| (d) 更新评论家参数:由式(13)得状态-动作值函数参数向量更新,由式(18)得状态值函数参数向量更新 |
| (7) 演员过程: |
| (a) 计算优势函数 |
| (b) 重写策略梯度:代入优势函数由式(19)得策略梯度 |
| (c) 更新演员参数:由式(8)得策略参数向量更新 |
| (8) end for |
 下载:
下载:





























































































































































































































 DownLoad:
DownLoad: