-
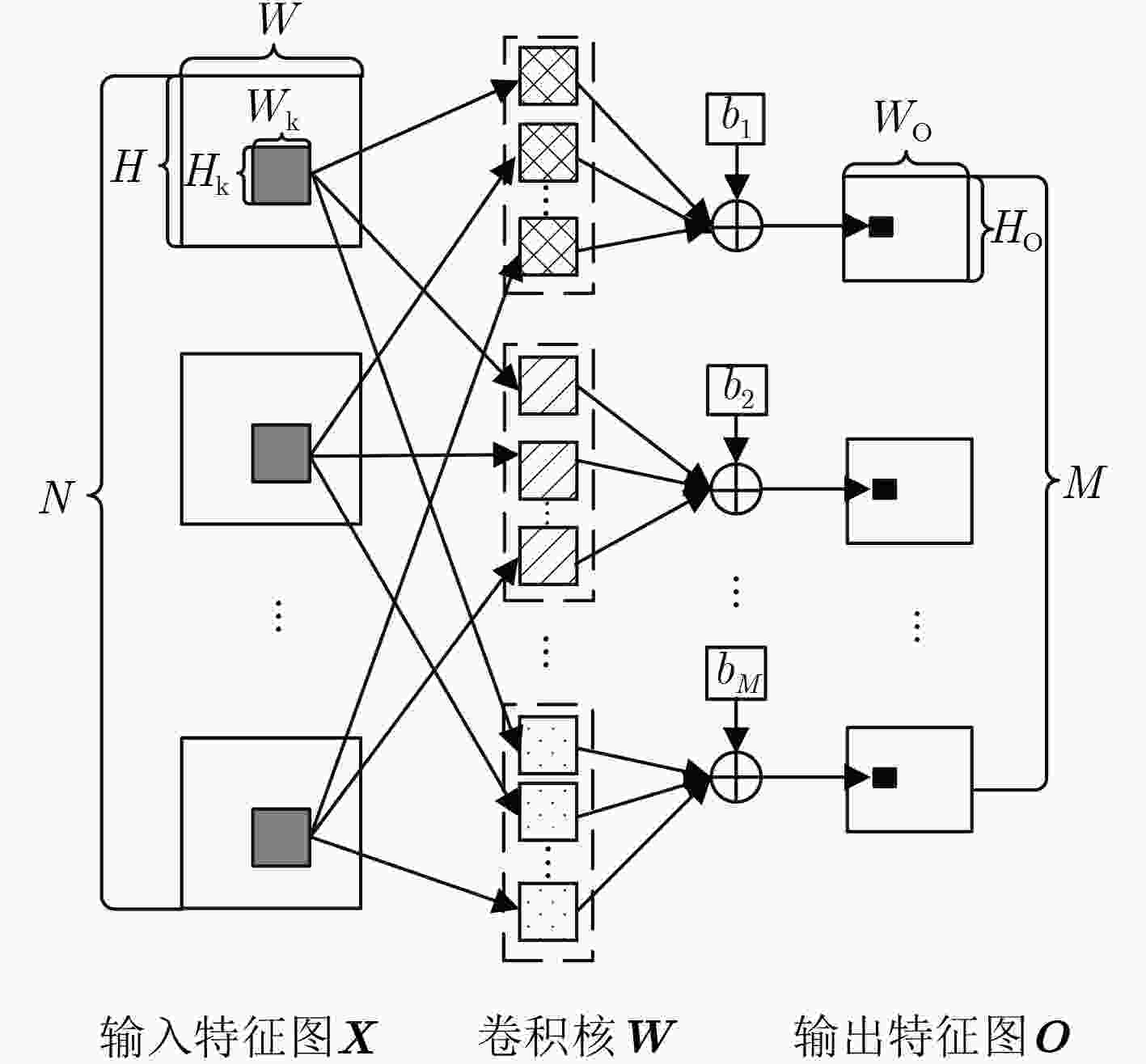
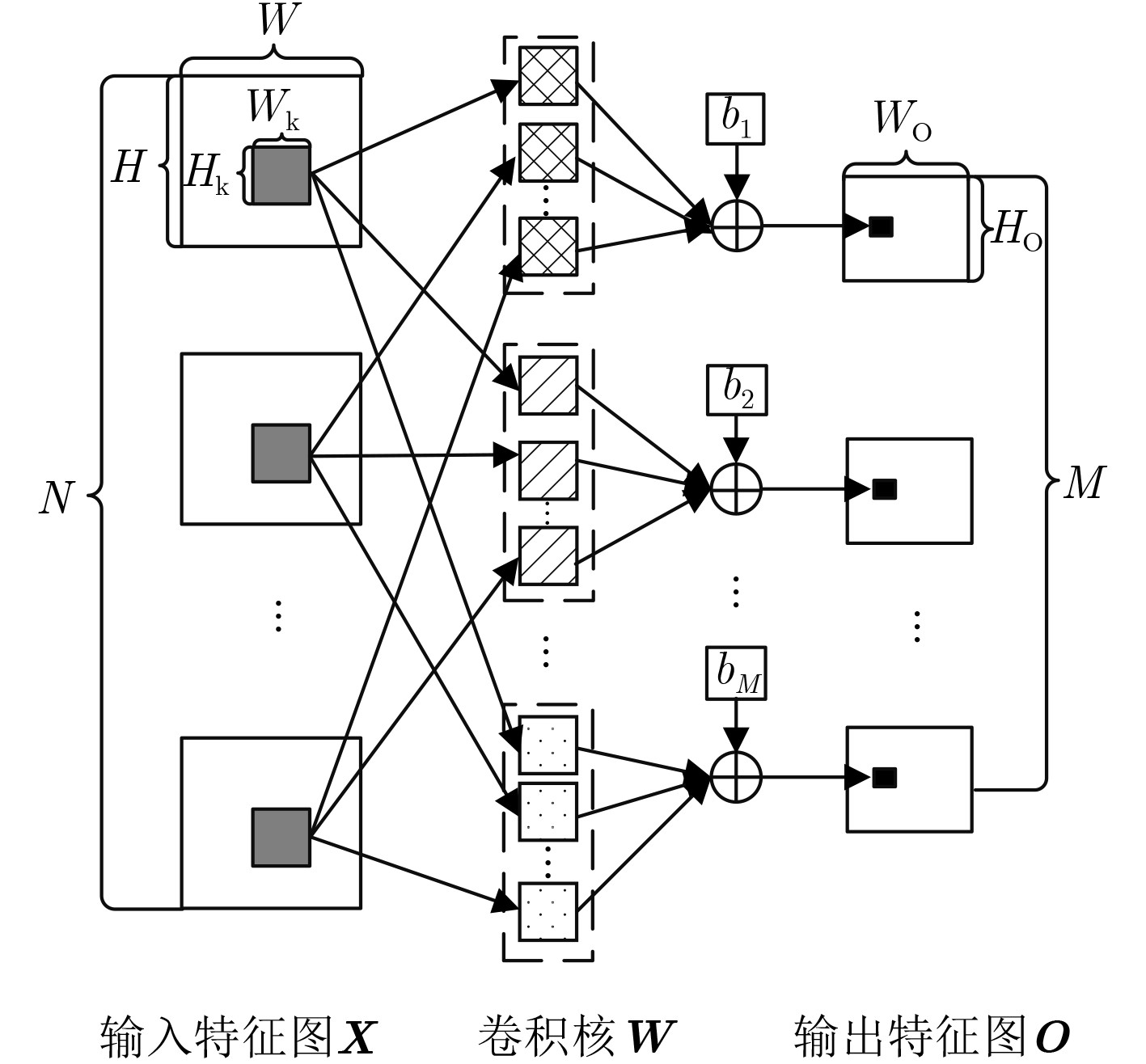
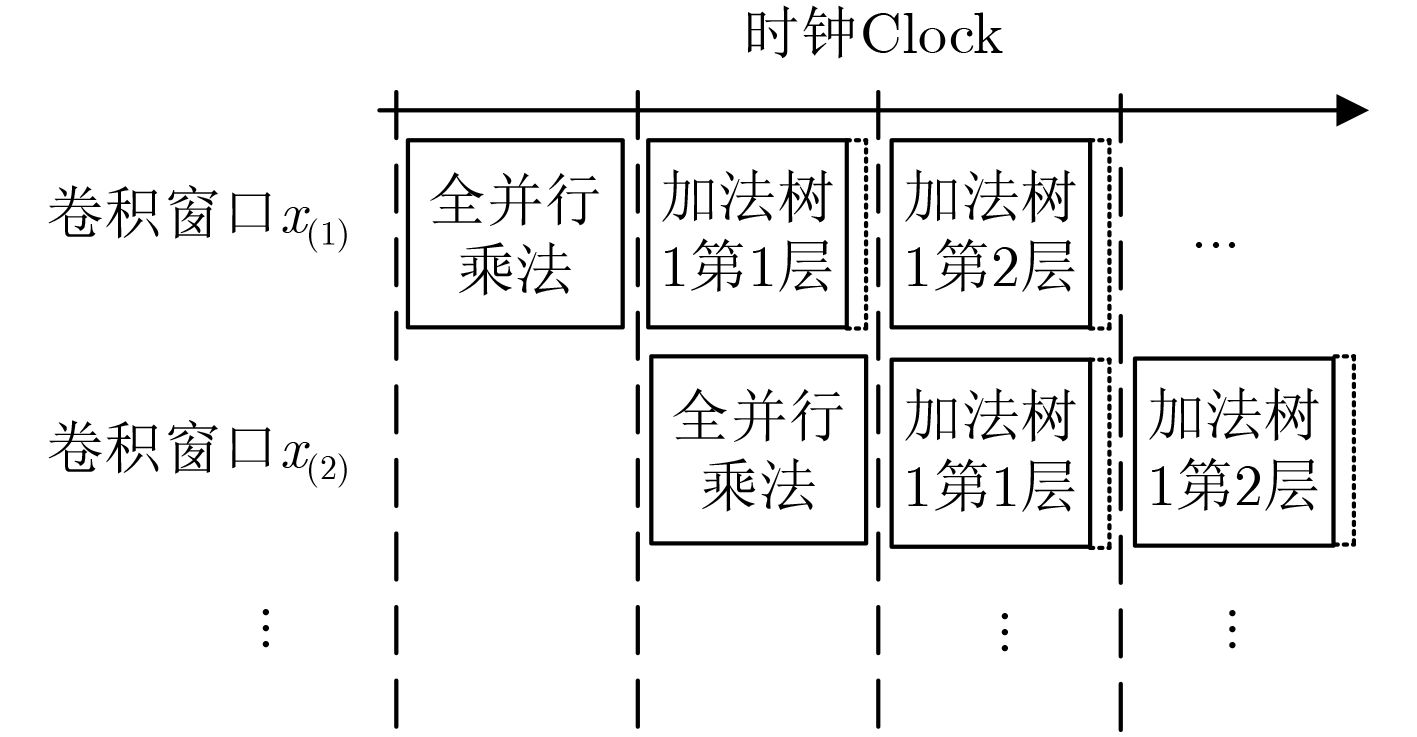
图 1 卷积层运算过程
Figure 1.
-
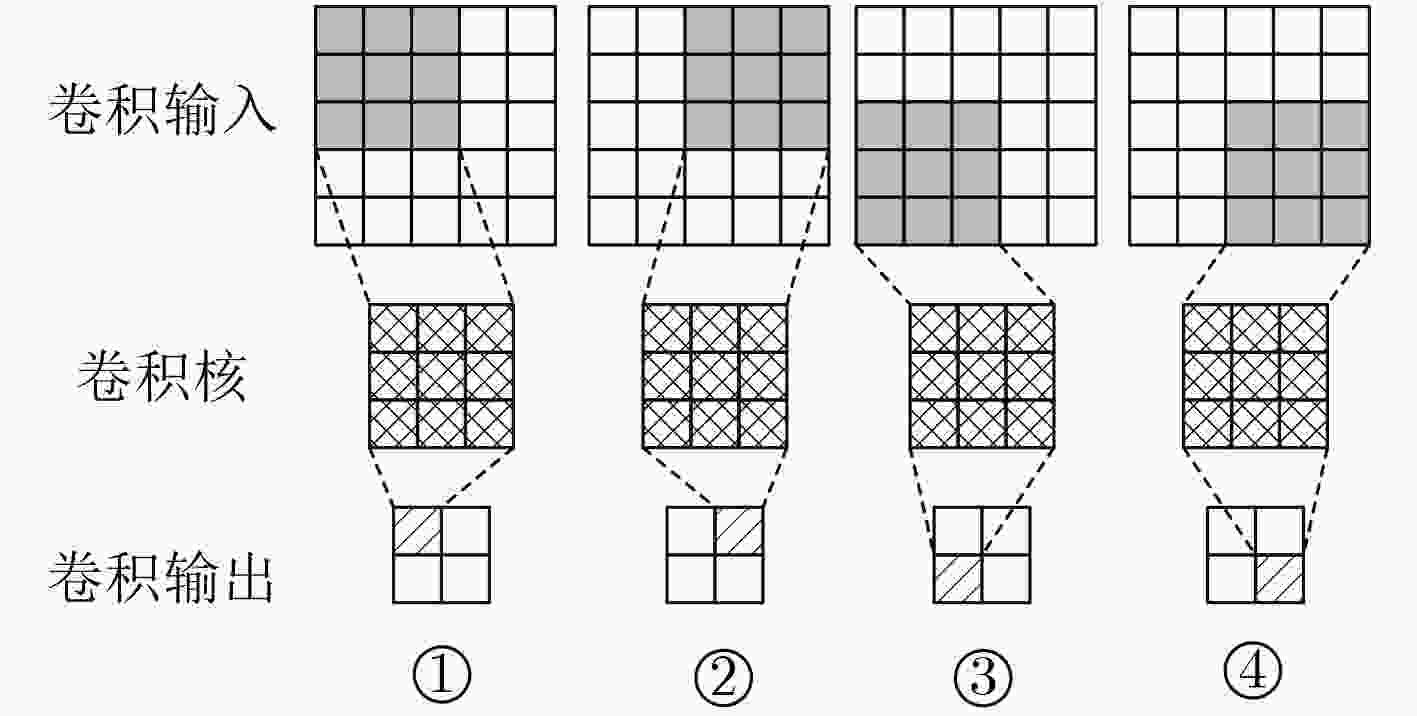
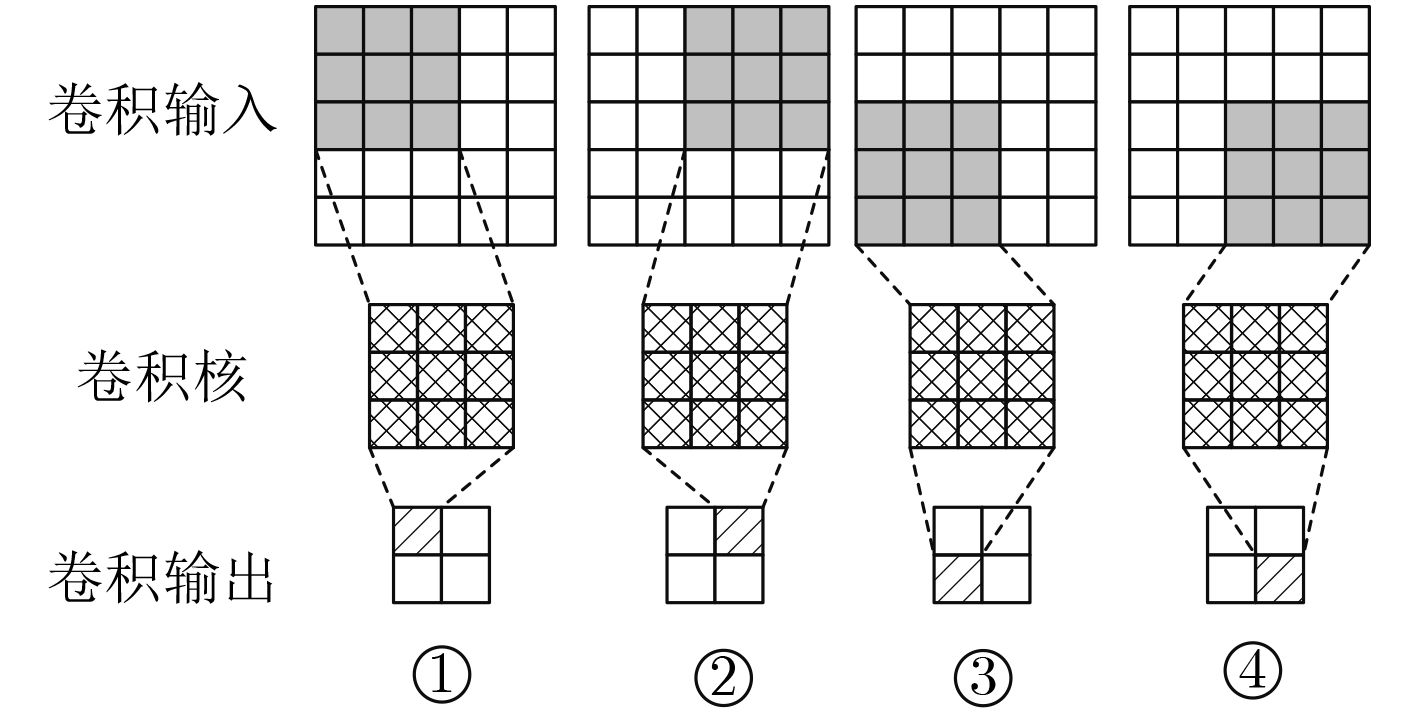
图 2 1个输入通道的卷积运算过程
Figure 2.
-

图 3 N个输入通道的卷积窗口并行计算
Figure 3.
-

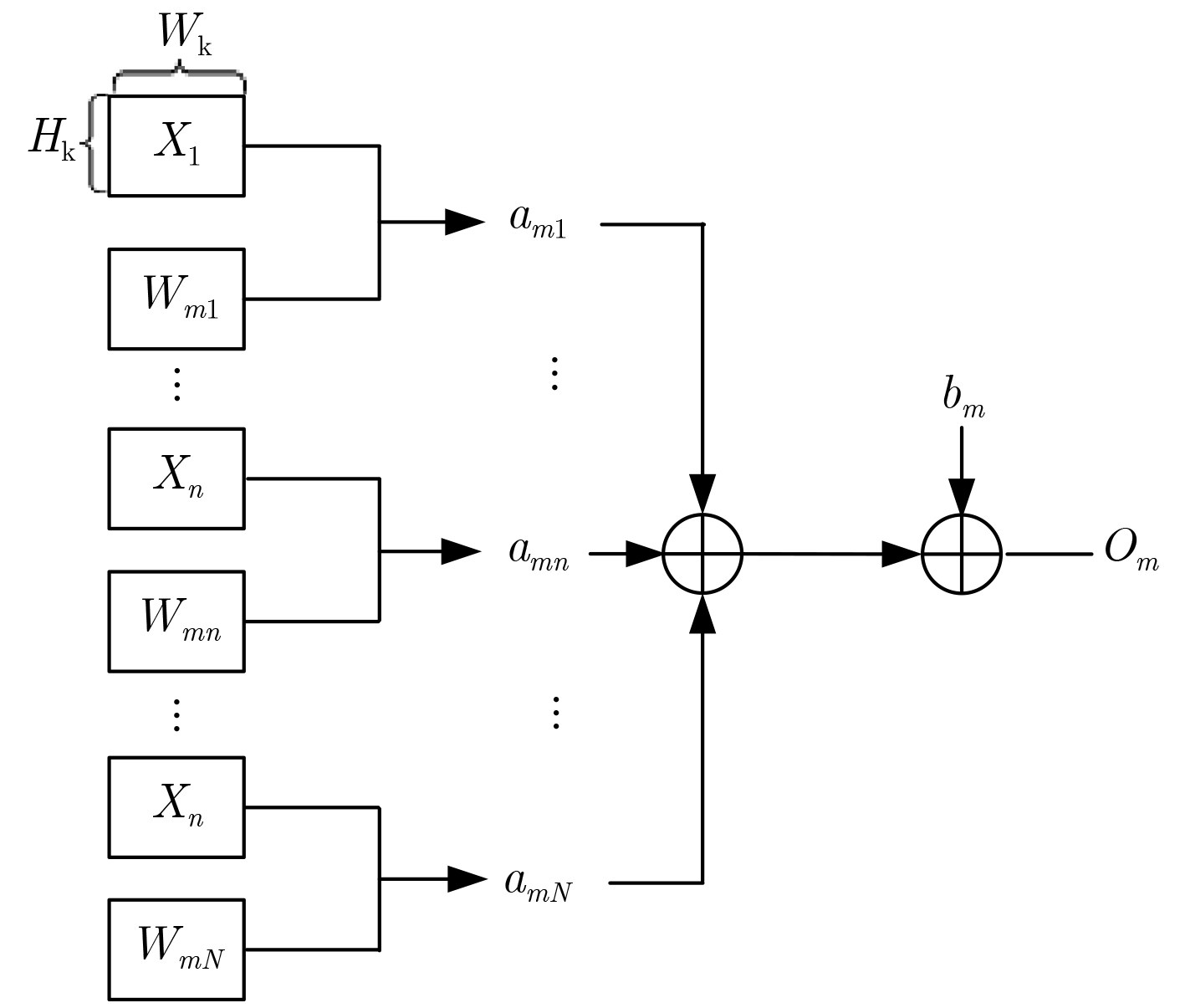
图 4 累加器并行运算
Figure 4.
-

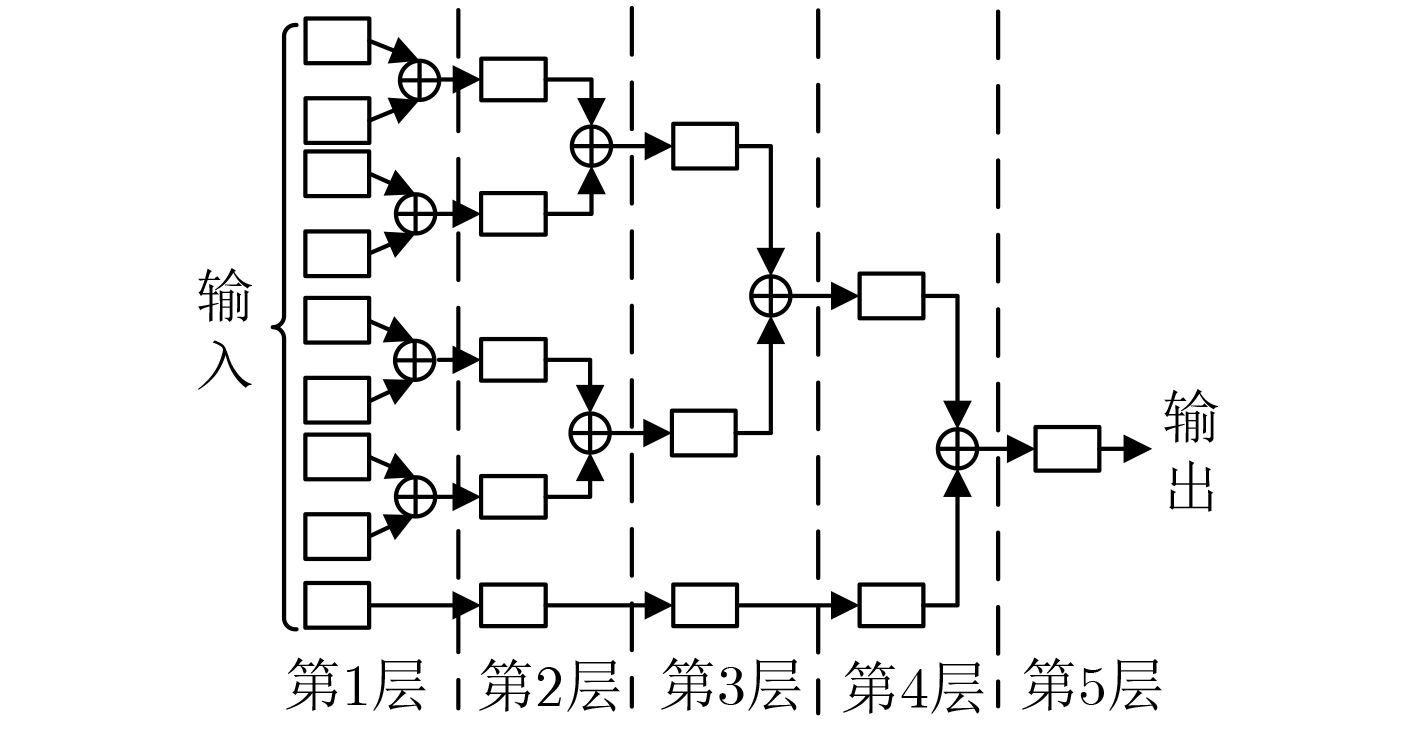
图 5 经典加法树
Figure 5.
-
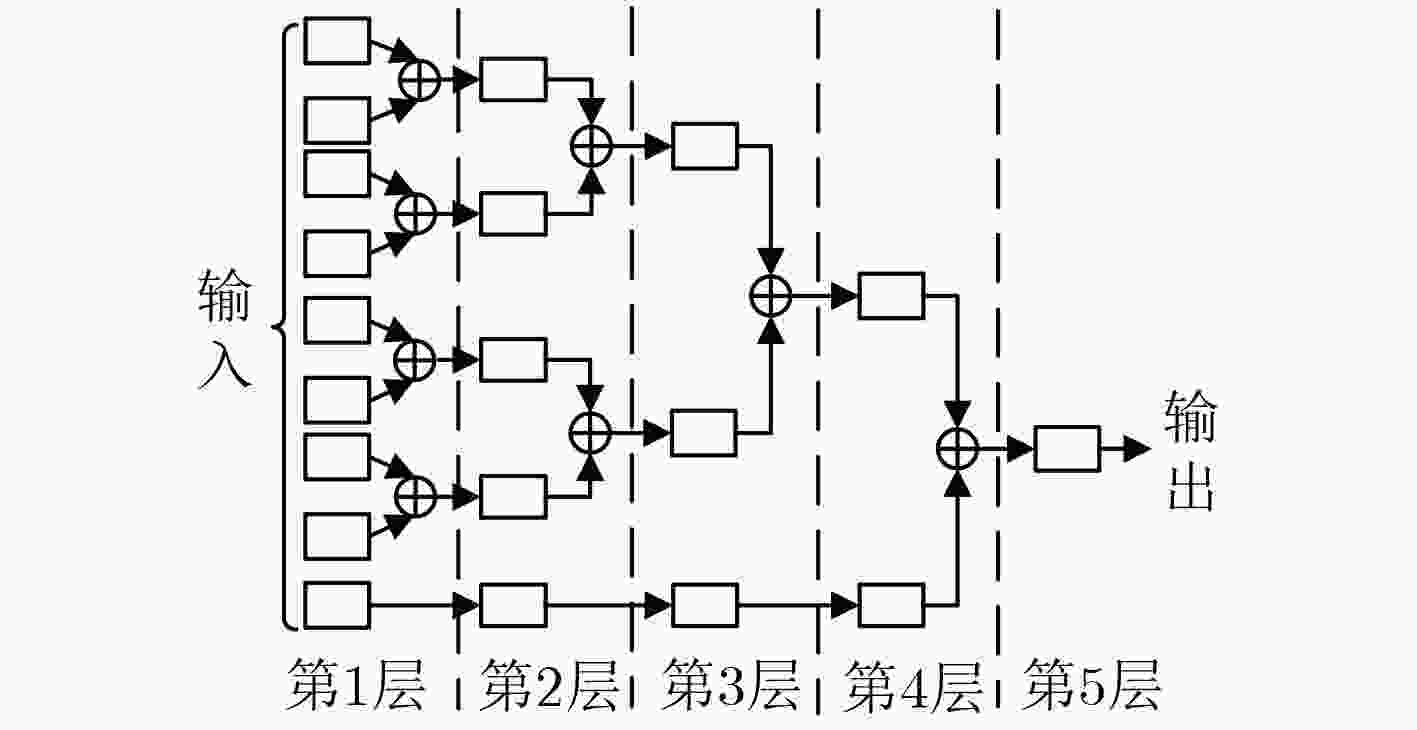
图 6 本文设计的加法树
Figure 6.
-

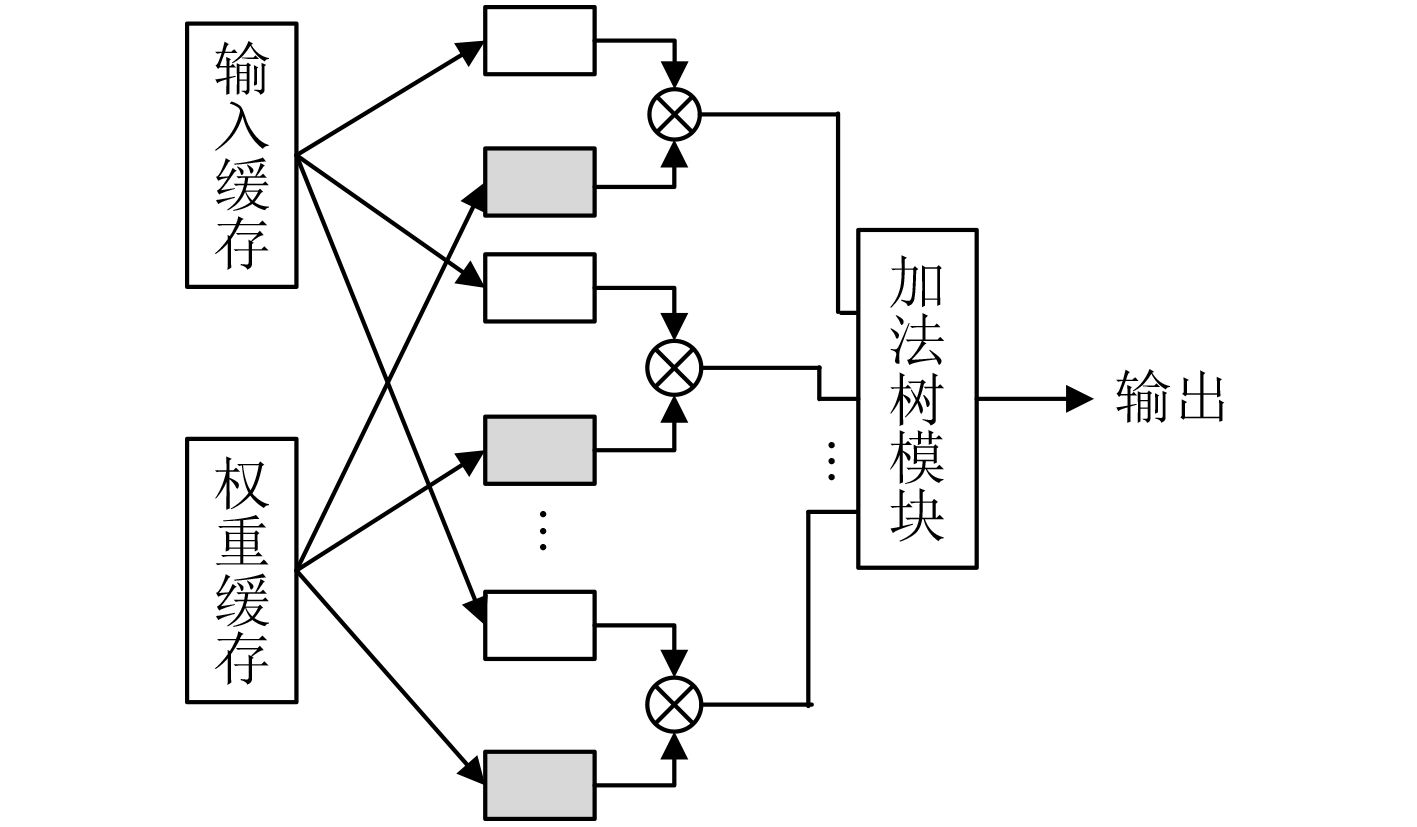
图 7 乘法-加法树模块
Figure 7.
-

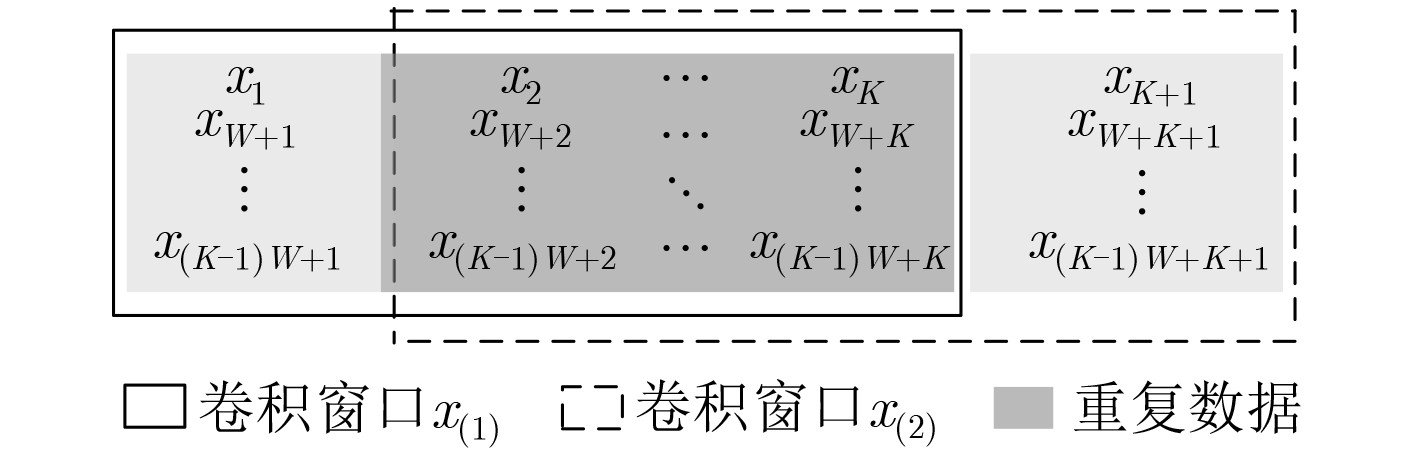
图 8 卷积窗口数据重用
Figure 8.
-

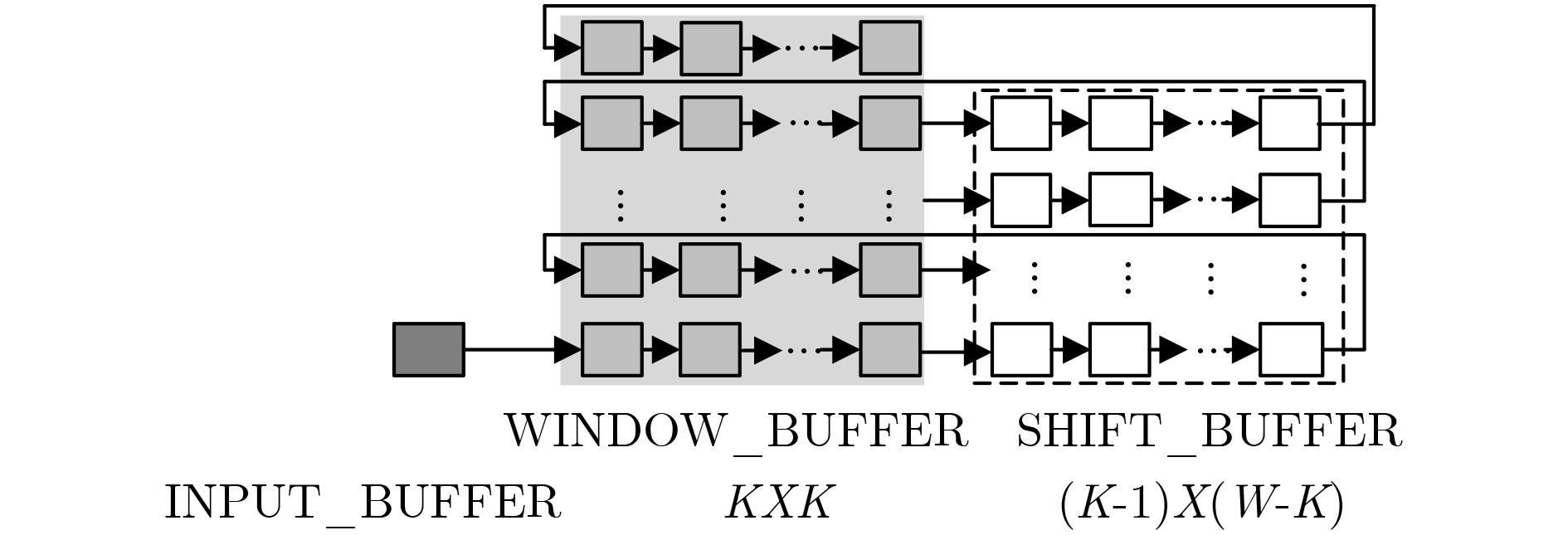
图 9 窗口缓存结构
Figure 9.
-

图 10 窗口缓存时序
Figure 10.
-

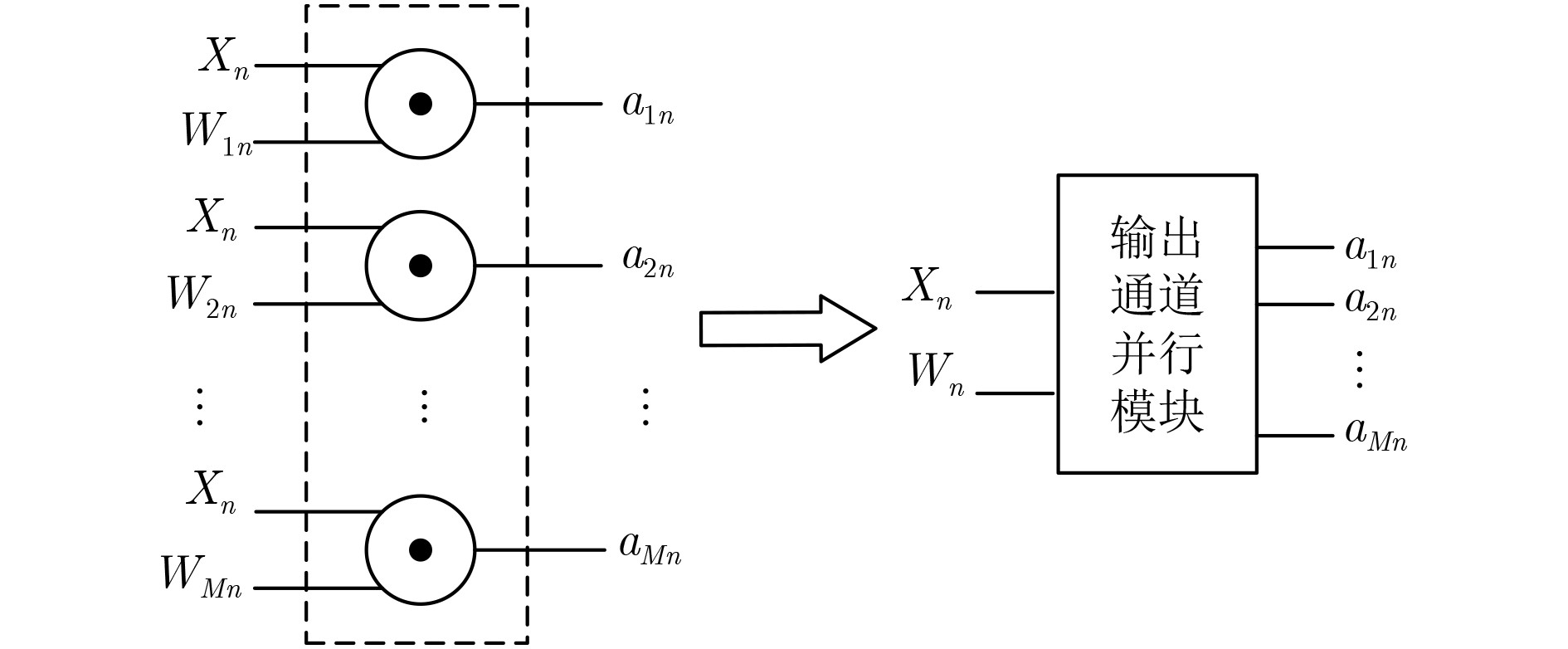
图 11 输出通道并行模块
Figure 11.
-
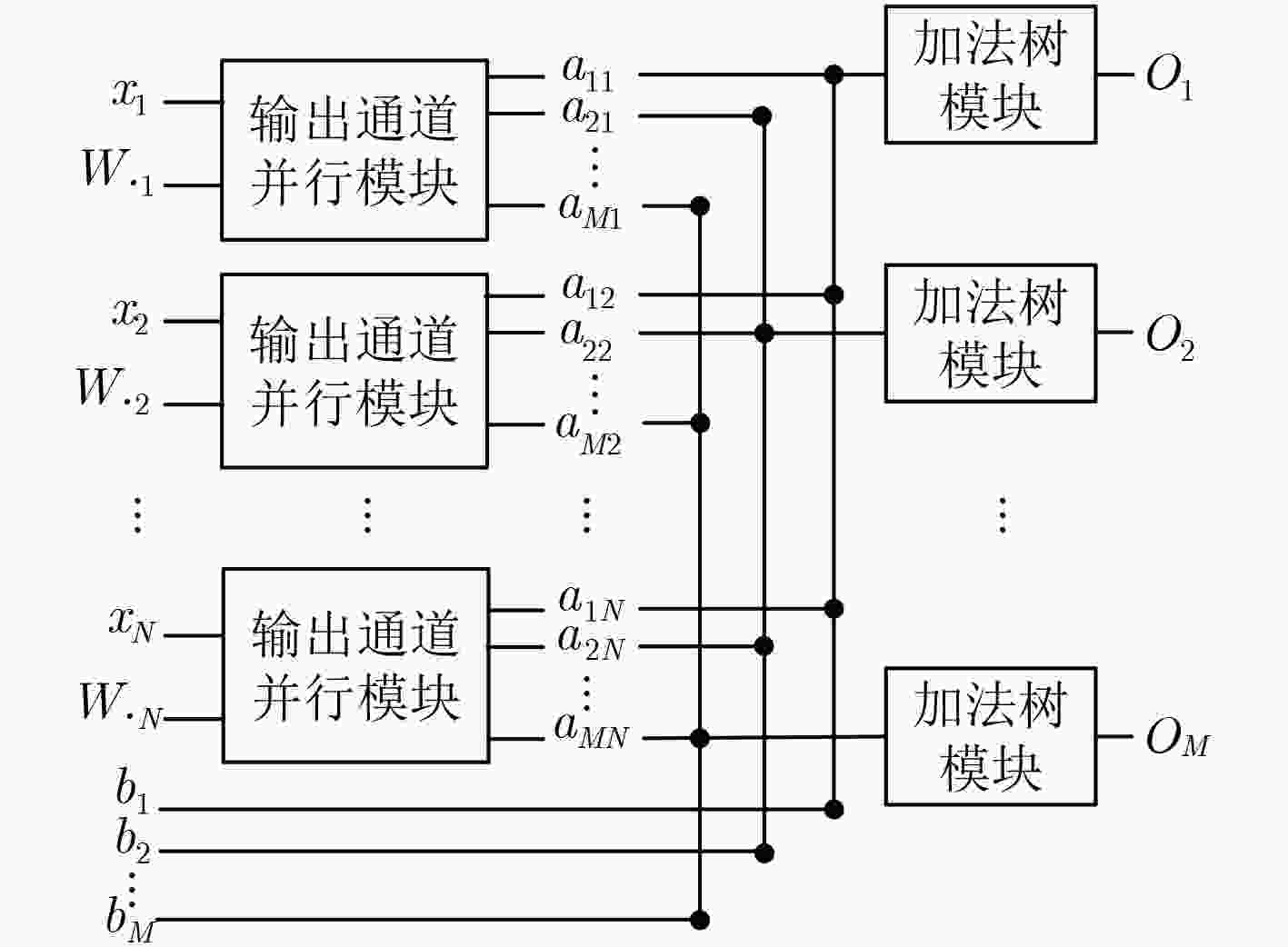
图 12 并行加速方案结构
Figure 12.
-
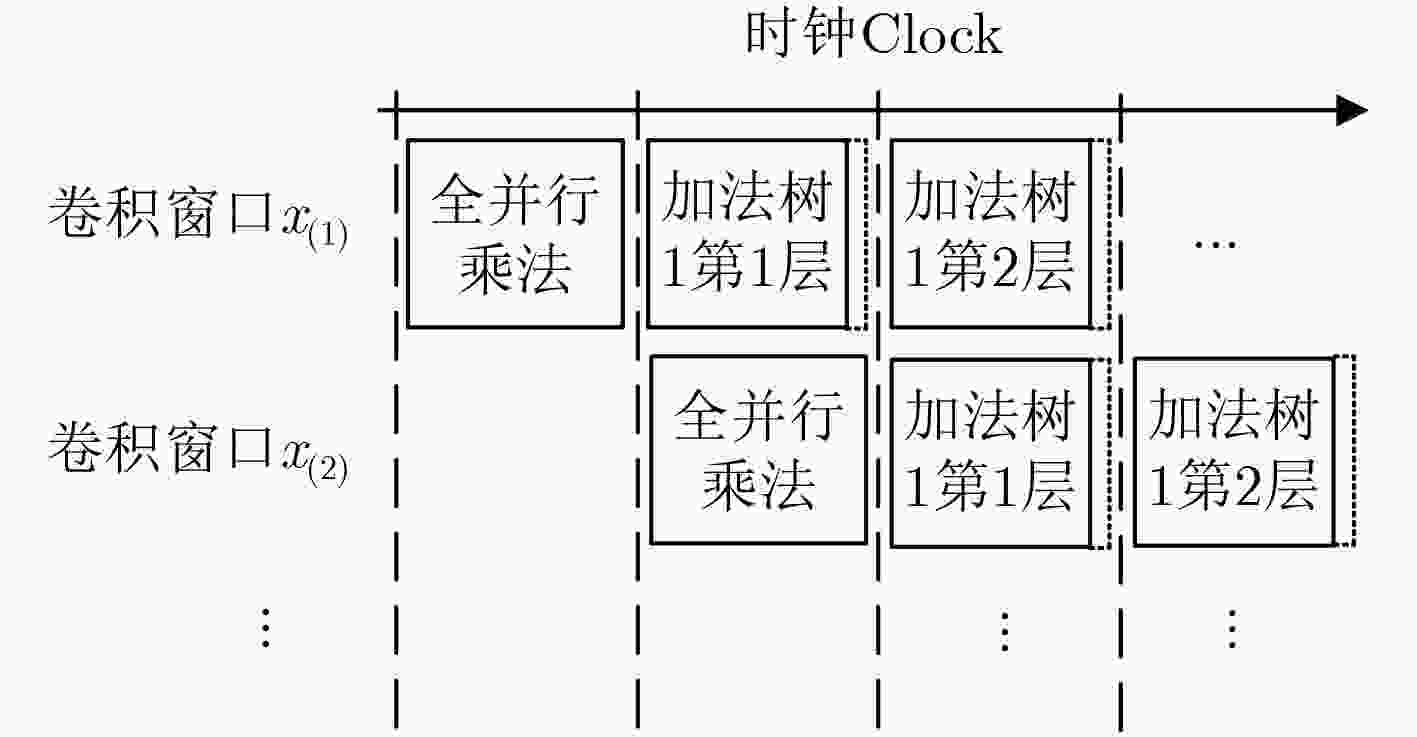
图 13 卷积窗口流水线
Figure 13.
-
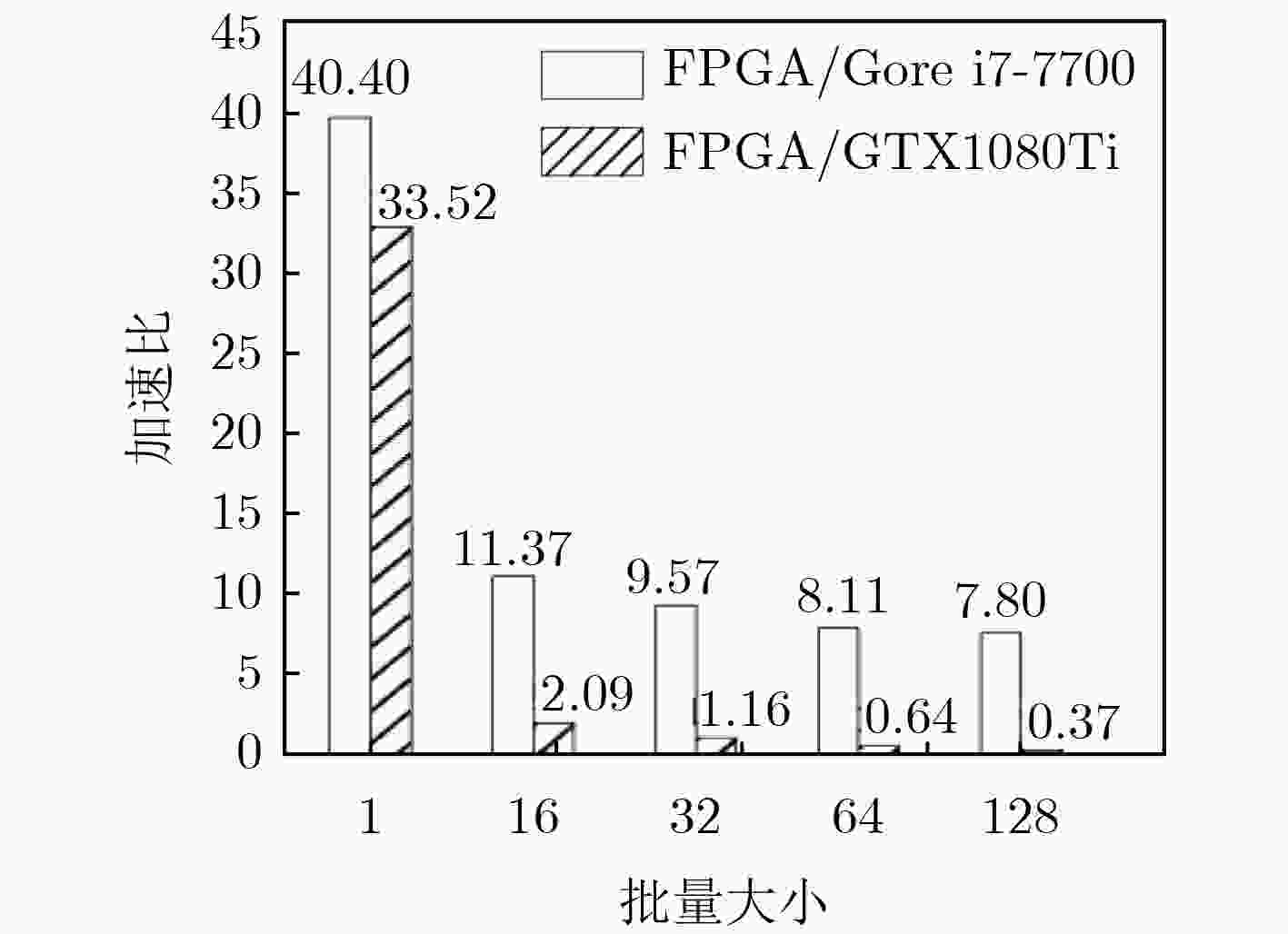
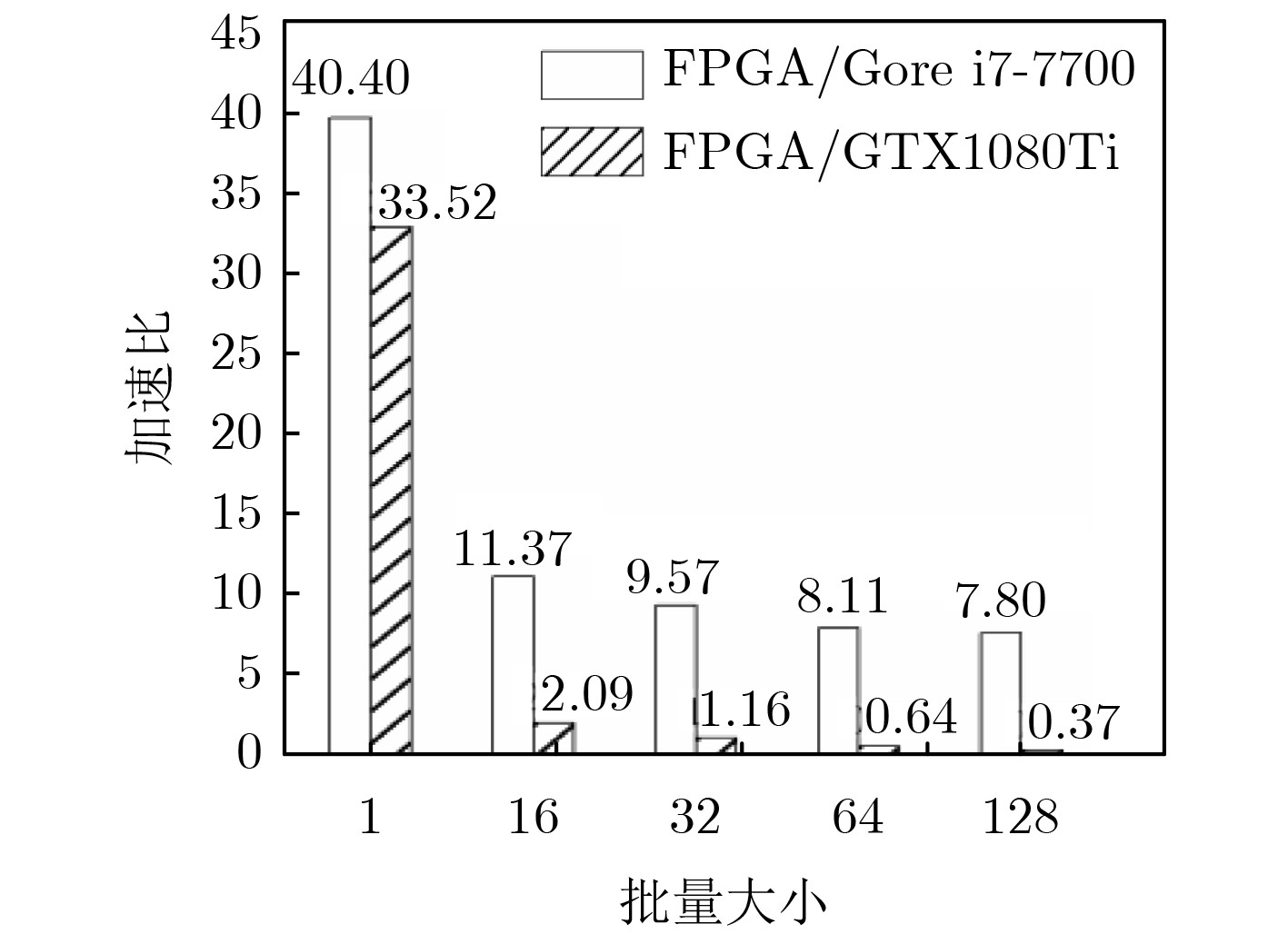
图 14 FPGA, CPU, GPU的性能对比
Figure 14.
-
层名称 层结构 参数量(个) 卷积层1 卷积核大小3×3,卷积核个数15,步长1 150 激活层1 无 0 池化层1 池化大小2×2,步长2 0 卷积层2 卷积核大小6×6,卷积核个数20,步长1 10820 激活层2 无 0 池化层2 池化大小2×2,步长2 0 全连接层 输出神经元个数10 3210 表 1 卷积神经网络结构参数
-
资源 比例(%) ALMs 89423/113560 79 Block Memory 730151/12492800 6 DSPs 342/342 100 表 2 FPGA资源消耗情况
-
表 3 与文献FPGA硬件加速对比
图共
14 个 表共
3 个