

Adaptive Attention Mechanism Fusion for Real-Time Semantic Segmentation in Complex Scenes
-
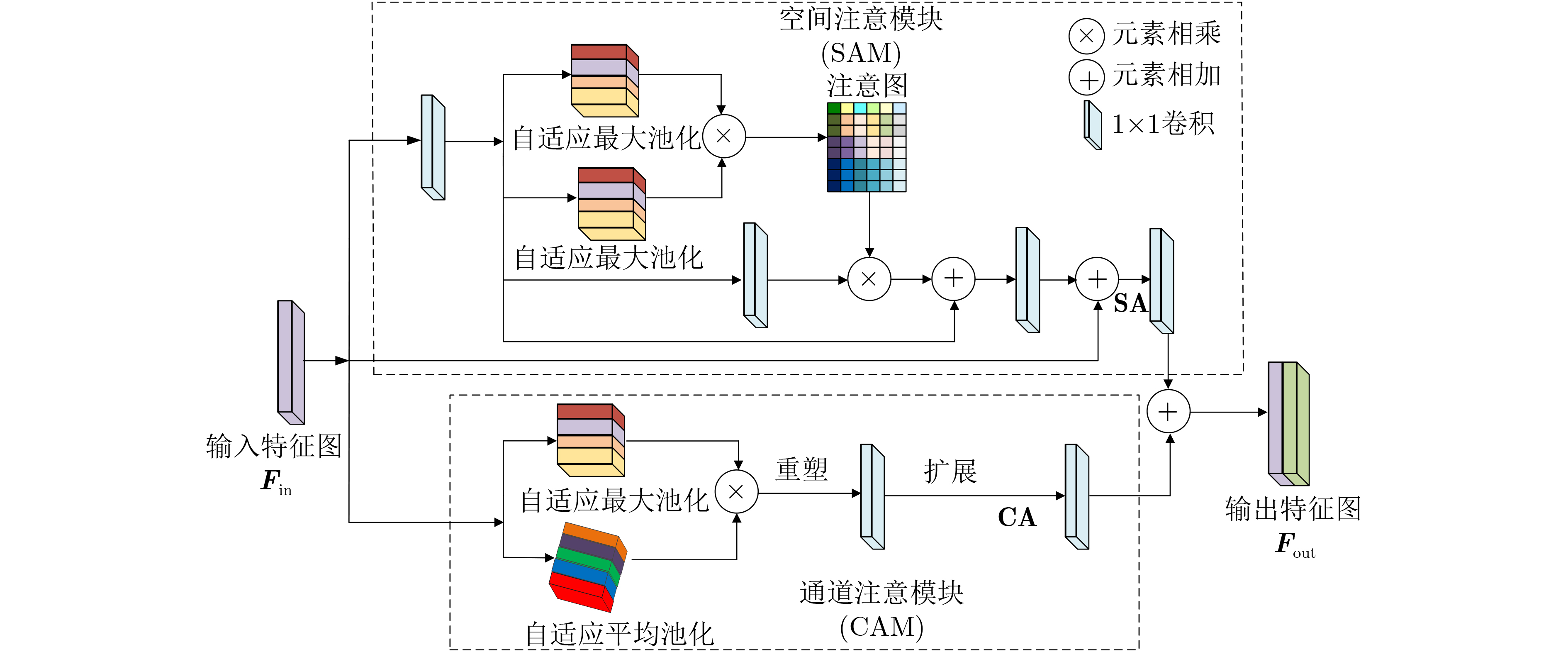
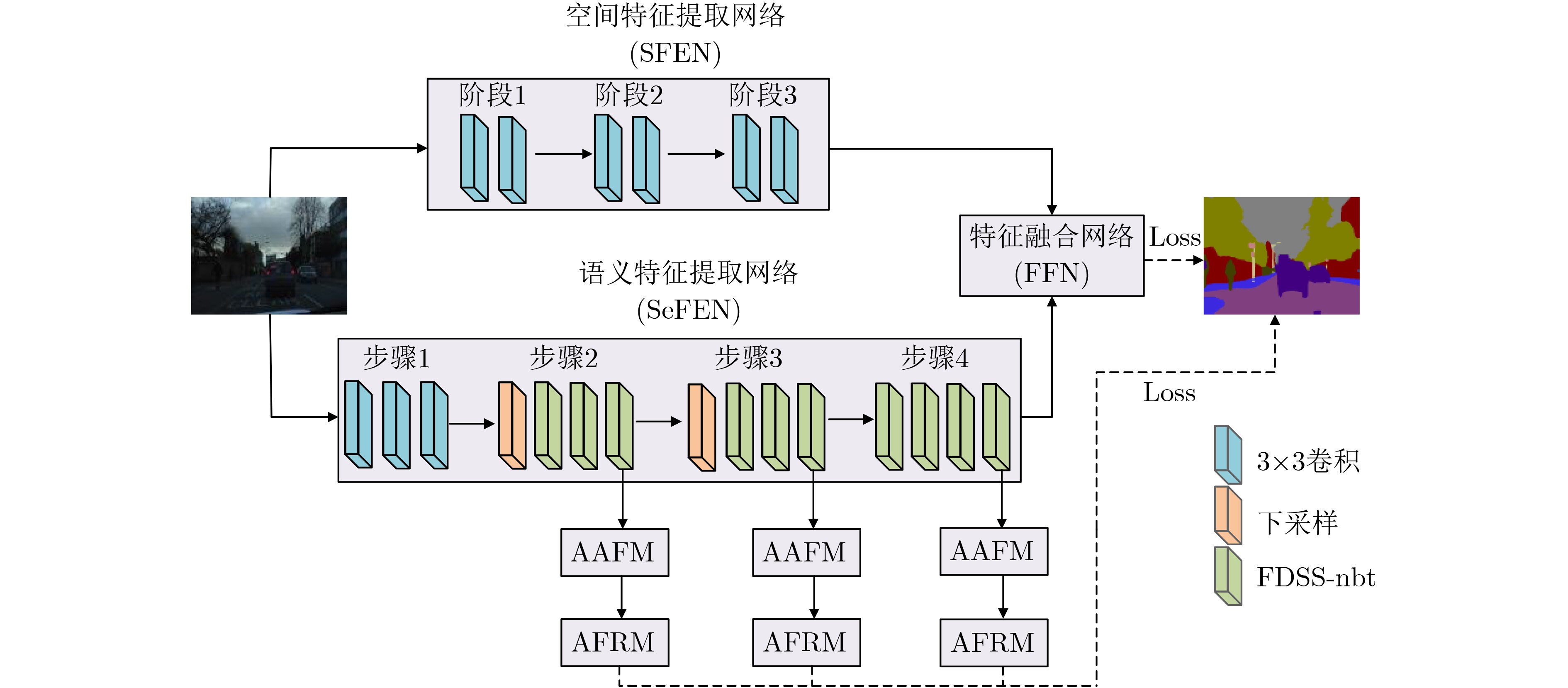
摘要: 实现高准确度和低计算负担是卷积神经网络(CNN)实时语义分割面临的严峻挑战。针对复杂城市街道场景目标种类众多、光照变化大等特点,该文设计了一种高效的实时语义分割自适应注意力机制融合网络(AAFNet)分别提取图像空间细节和语义信息,再经过特征融合网络(FFN)获得准确语义图像。AAFNet采用扩展的深度可分离卷积(DDW)可增大语义特征提取感受野,提出自适应平均池化(Avp)和自适应最大池化(Amp)构成自适应注意力机制融合模块(AAFM),可细化目标边缘分割效果并降低小目标的漏分率。最后在复杂城市街道场景Cityscapes和CamVid数据集上分别进行了语义分割实验,所设计的AAFNet以32帧/s(Cityscapes) 和52帧/s (CamVid)的推理速度获得73.0%和69.8%的平均分割精度(mIoU),且与扩展的空间注意力网络(DSANet)、多尺度上下文融合网络(MSCFNet)以及轻量级双边非对称残差网络(LBARNet)相比,AAFNet平均分割精度最高。
-
关键词:
- 卷积神经网络 /
- 复杂城市街道场景 /
- 扩展的深度可分离卷积 /
- 自适应注意力机制融合 /
- 分割精度
Abstract: Realizing high accuracy and low computational burden is a serious challenge faced by Convolutional Neural Network (CNN) for real-time semantic segmentation. In this paper, an efficient real-time semantic segmentation Adaptive Attention mechanism Fusion Network(AAFNet) is designed for complex urban street scenes with numerous types of targets and large changes in lighting. Image spatial details and semantic information are respectively extracted by the network, and then, through Feature Fusion Network(FFN), accurate semantic images are obtained. Dilated Deep-Wise separable convolution (DDW) is adopted by AAFNet to increase the receptive field of semantic feature extraction, an Adaptive Attention mechanism Fusion Module (AAFM) is proposed, which combines Adaptive average pooling(Avp) and Adaptive max pooling(Amp) to refine the edge segmentation effect of the target and reduce the leakage rate of small targets. Finally, semantic segmentation experiments are performed on the Cityscapes and CamVid datasets for complex urban street scenes. The designed AAFNet achieves 73.0% and 69.8% mean Intersection over Union (mIoU) at inference speeds of 32 fps (Cityscapes) and 52 fps (CamVid). Compared with Dilated Spatial Attention Network (DSANet), Multi-Scale Context Fusion Network (MSCFNet), and Lightweight Bilateral Asymmetric Residual Network (LBARNet), AAFNet has the highest segmentation accuracy. -
表 1 空间特征提取网络结构参数
阶段 卷积核 步长 输入通道数 输出通道数 阶段1 3×3 2 3 32 3×3 1 32 32 阶段2 3×3 2 32 64 3×3 1 64 64 阶段3 3×3 2 64 128 3×3 1 128 128  下载: 导出CSV
下载: 导出CSV
表 2 语义特征提取网络结构参数
步骤 操作类型 扩张率 输入通道数 输出通道数 步骤1 3×3卷积 – 3 32 3×3卷积 – 32 32 3×3卷积 – 32 32 步骤2 下采样 – 32 64 3×FDSS-nbt – 64 64 步骤3 下采样 – 64 128 FDSS-nbt 1 128 128 FDSS-nbt 3 128 128 FDSS-nbt 6 128 128 FDSS-nbt 12 128 128 步骤4 FDSS-nbt 3 128 128 FDSS-nbt 6 128 128 FDSS-nbt 12 128 128 FDSS-nbt 24 128 128
下载: 导出CSV
表 3 CamVid数据集上AAFM消融实验结果
消融模块 SFEN SeFEN AAFM mIoU(%) Parameters fps GFLOPs 基线 √ √ × 67.9 2.2M 73 9.29 AAFNet √ √ √ 69.8 2.4M 52 9.98
下载: 导出CSV
表 4 Cityscapes数据集上AAFM消融实验结果
消融模块 SFEN SeFEN AAFM mIoU(%) Parameters fps GFLOPs 基线 √ √ × 69.7 2.2M 52 28.25 AAFNet √ √ √ 73.0 2.4M 32 30.34
下载: 导出CSV
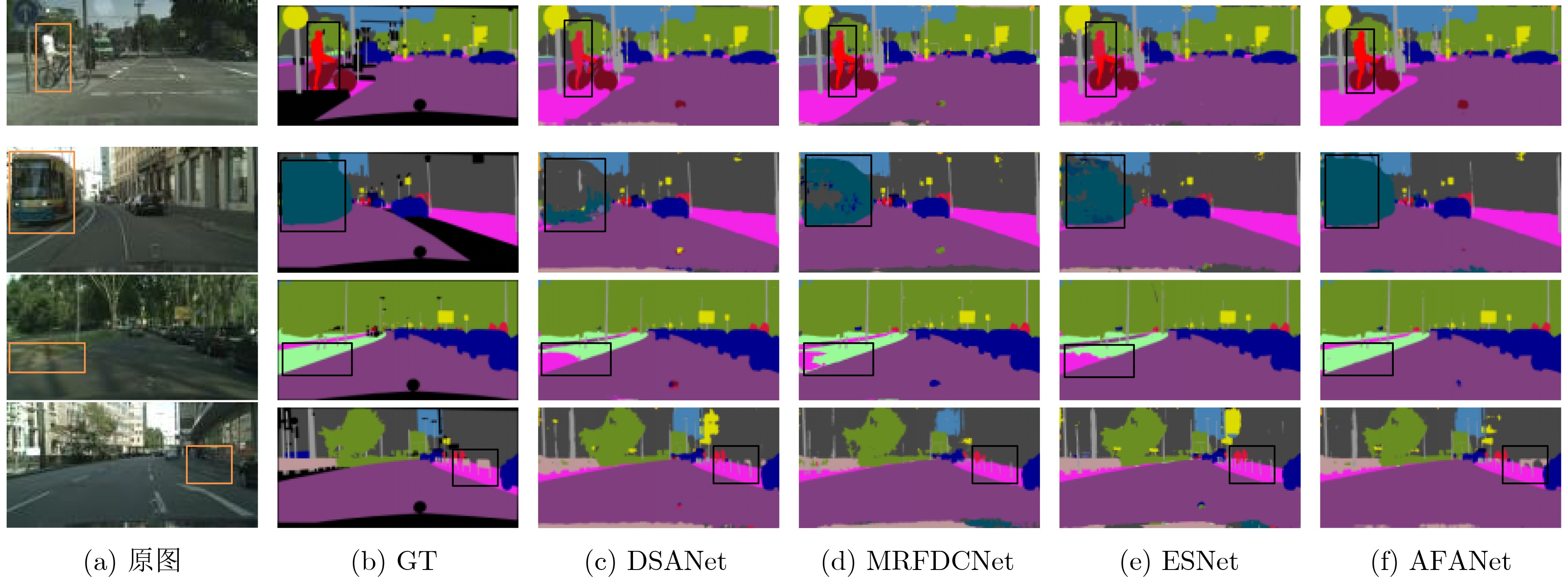
表 5 CamVid数据集上各网络单个类别IoU与mIoU对比结果(%)
网络名称 sky fence pole road sign tree ENet 91.0 21.7 25.6 91.9 28.5 67.9 ERFNet 91.7 36.4 35.9 93.8 41.1 72.9 CGNet 91.1 36.3 28.4 94.3 42.9 72.2 ESNet 91.3 39.2 36.6 94.5 42.2 71.8 DSANet 91.5 45.8 34.5 94.5 47.2 76.4 RGPNet[21] 91.2 51.4 46.8 90.6 62.5 77.3 PCNet 91.4 40.2 34.0 95.1 44.8 74.5 AAFNet 91.6 43.7 34.9 95.2 50.6 76.0 网络名称 sidewalk building car pedstrin bicyclist mIoU ENet 75.0 72.3 76.1 37.7 41.1 57.2 ERFNet 79.8 79.9 82.3 54.7 58.3 66.1 CGNet 80.8 78.0 79.9 55.2 55.1 64.9 ESNet 81.8 78.5 80.6 55.1 56.0 66.1 DSANet 80.9 82.9 84.2 60.4 64.6 69.3 RGPNet[21] 70.7 85.8 87.0 67.6 67.2 69.2 PCNet 81.7 82.3 80.5 56.8 55.3 67.0 AAFNet 82.8 83.2 85.2 60.1 64.1 69.8
下载: 导出CSV
表 6 Cityscapes数据集上各网络单个类别IoU与mIoU对比结果(%)
网络名称 road sidewalk building wall fence pole traffic light traffic sign vegetation terrain ERFNet 97.9 82.1 90.7 45.2 50.4 59.0 62.6 68.4 91.9 69.4 CGNet 95.5 78.7 88.1 40.0 43.0 54.1 59.8 63.9 89.6 67.6 ESNet 98.1 80.4 92.4 48.3 49.2 61.5 62.5 72.3 92.5 61.5 AGLNet[22] 97.8 80.1 91.0 51.3 50.6 58.3 63.0 68.5 92.3 71.3 DSANet 96.8 78.5 91.2 50.5 50.8 59.4 64.0 71.7 92.6 70.0 MSCFNet 97.7 82.8 91.0 49.0 52.5 61.2 67.1 71.4 92.3 70.2 MRFDCNet[23] 98.2 83.7 91.5 50 53.9 59.6 66.6 70.7 92.4 70.4 PCNet 98.3 84.4 91.4 48.4 52.6 57.1 63.8 69.7 92.3 70.0 AAFNet 98.5 87.9 91.9 43.8 56.6 64.0 68.4 76.1 92.6 62.2 网络名称 sky person rider car truck bus train motorcycle bicycle mIoU ERFNet 94.2 78.5 59.8 93.4 52.3 60.8 53.7 49.9 64.2 69.7 CGNet 92.9 77.9 54.9 90.2 44.1 59.5 25.2 47.3 60.2 64.8 ESNet 94.4 76.6 53.2 94.4 62.5 74.3 52.4 45.5 71.4 70.7 AGLNet[22] 94.2 80.1 59.6 93.8 48.4 68.1 42.1 52.4 67.8 70.1 DSANet 94.5 81.8 61.9 92.9 56.1 75.6 50.6 50.9 66.8 71.4 MSCFNet 94.3 82.7 62.7 94.1 50.9 66.1 51.9 57.6 70.2 71.9 MRFDCNet[23] 94.7 82 63.0 94.4 55.5 70.6 57.3 59 70.4 72.8 PCNet 94.6 80.6 61.5 94.5 61.2 73.9 63.2 57.3 69.3 72.9 AAFNet 94.0 82.9 58.3 94.2 62.4 73.9 48.6 57.2 73.8 73.0
下载: 导出CSV
表 7 CamVid数据集上各网络参数量、推理速度和计算复杂度对比结果
网络名称 ENet ERFNet CGNet ESNet DSANet SegNet LBARNet AAFNet Parameters 0.36M 2.07M 0.49M 1.66M 3.12M 29.45M 0.6M 2.42M fps 75 71 64 71 42 17 72 52 GFLOPs 1.39 8.83 2.3 8.0 12.51 29.21 - 9.98 mIoU 57.2 66.1 64.9 66.1 69.3 60.1 67.2 69.8
下载: 导出CSV
表 8 Cityscapes数据集上各网络参数量、推理速度和计算复杂度对比结果
网络名称 输入尺寸 GFLOPs Parameters(M) fps mIoU 显卡型号 ENet 512×1 024 4.35 0.4 44 58.3 TITAN Xp ERFNet 512×1 024 28.86 2.1 32 69.7 TITAN Xp CGNet 512×1 024 7.01 0.5 35 64.8 TITAN Xp ESNet 512×1 024 24.35 1.06 54 70.7 TITAN Xp PSPNet[24] 512×1 024 514.56 65.47 7 80.2 TITAN Xp SegNet 512×1 024 326.26 29.45 18 - TITAN Xp DABNet[25] 512×1 024 10.46 0.76 84 70.1 TITAN Xp AGLNet 512×1 024 13.88 1.12 43 70.1 TITAN Xp DSANet 512×1 024 38.0 3.12 33 71.4 TITAN Xp ICNet 512×1 024 40.37 12.87 30 70.6 TITAN Xp RGPNet 1 024×2 048 - 17.8 38 - RTX 2080Ti MRFDCNet 512×1 024 14.04 1.07 47 72.8 TITAN Xp BAFF 512×1 024 15.96 0.82 - 68.0 TITAN Xp MHANet[26] 512×1 024 14.25 5.42 203 71.9 RTX 2080Ti LBARNet 512×1 024 - 0.6 72 70.8 GTX 3090 AAFNet 512×1 024 30.34 2.42 32 73.0 TITAN Xp
下载: 导出CSV
-
[1] HAO Shijie, ZHOU Yuan, and GUO Yanrong. A brief survey on semantic segmentation with deep learning[J]. Neurocomputing, 2020, 406: 302–321. doi: 10.1016/j.neucom.2019.11.118. [2] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. doi: 10.1109/TPAMI.2016.2644615. [3] BADRINARAYANAN V, KENDALL A, and CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481–2495. doi: 10.17863/CAM.17966. [4] CHEN Wenlin, WILSON J T, TYREE S, et al. Compressing neural networks with the hashing trick[C]. The 32nd International Conference on Machine Learning, Lille, France, 2015: 2285–2294. doi: 10.5555/3045118.3045361. [5] HAN Song, MAO Huizi, and DALLY W J. Deep compression: Compressing deep neural network with pruning, trained quantization and Huffman coding[C]. 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2016: 3–7. [6] WU Jiaxiang, LENG Cong, WANG Yuhang, et al. Quantized convolutional neural networks for mobile devices[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA, 2016: 4820–4828. doi: 10.1109/CVPR.2016.521. [7] ROMERA E, ALVAREZ J M, BERGASA L M, et al. ERFNet: Efficient residual factorized ConvNet for real-time semantic segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19(1): 263–272. doi: 10.1109/TITS.2017.2750080. [8] WANG Yu, ZHOU Quan, XIONG Jian, et al. ESNet: An efficient symmetric network for real-time semantic segmentation[C]. Second Chinese Conference on Pattern Recognition and Computer Vision, Xi’an, China, 2019: 41–52. doi: 10.1007/978-3-030-31723-2_4. [9] GAO Guangwei, XU Guoan, YU Yi, et al. MSCFNet: A lightweight network with multi-scale context fusion for real-time semantic segmentation[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(12): 25489–25499. doi: 10.1109/TITS.2021.3098355. [10] PASZKE A, CHAURASIA A, KIM S, et al. ENet: A deep neural network architecture for real-time semantic segmentation[EB/OL].https://arxiv.org/pdf/:1606.02147.pdf, 2016. [11] ZHAO Hengshuang, QI Xiaojuan, SHEN Xiaoyong, et al. ICNet for real-time semantic segmentation on high-resolution images[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 418–434. doi: 10.1007/978-3-030-01219-9_25. [12] WU Tianyi, TANG Sheng, ZHANG Rui, et al. CGNet: A light-weight context guided network for semantic segmentation[J]. IEEE Transactions on Image Processing, 2021, 30: 1169–1179. doi: 10.1109/TIP.2020.3042065. [13] LV Qingxuan, SUN Xin, CHEN Changrui, et al. Parallel complement network for real-time semantic segmentation of road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(5): 4432–4444. doi: 10.1109/TITS.2020.3044672. [14] 黄庭鸿, 聂卓赟, 王庆国, 等. 基于区块自适应特征融合的图像实时语义分割[J]. 自动化学报, 2021, 47(5): 1137–1148. doi: 10.16383/j.aas.c180645.HUANG Tinghong, NIE Zhuoyun, WANG Qingguo, et al. Real-time image semantic segmentation based on block adaptive feature fusion[J]. Acta Automatica Sinica, 2021, 47(5): 1137–1148. doi: 10.16383/j.aas.c180645. [15] HU Xuegang and ZHOU Baoman. LBARNet: Lightweight bilateral asymmetric residual network for real-time semantic segmentation[J]. Computers & Graphics, 2023, 116: 1–12. doi: 10.1016/j.cag.2023.07.039. [16] ZHAO Hengshuang, ZHANG Yi, LIU Shu, et al. PSANet: Point-wise spatial attention network for scene parsing[C]. 15th European Conference on Computer Vision, Munich, Germany, 2018: 270–286. doi: 10.1007/978-3-030-01240-3_17. [17] FU Jun, LIU Jing, TIAN Haijie, et al. Dual attention network for scene segmentation[C]. The IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Alamitos, USA, 2019: 3141–3149. doi: 10.1109/CVPR.2019.00326. [18] ELHASSAN M A M, HUANG Chenxi, YANG Chenhui, et al. DSANet: Dilated spatial attention for real-time semantic segmentation in urban street scenes[J]. Expert Systems with Applications, 2021, 183: 115090. doi: 10.1016/j.eswa.2021.115090. [19] 王囡, 侯志强, 蒲磊, 等. 空洞可分离卷积和注意力机制的实时语义分割[J]. 中国图象图形学报, 2022, 27(4): 1216–1225. doi: 10.11834/jig.200729.WANG Nan, HOU Zhiqiang, PU Lei, et al. Real-time semantic segmentation analysis based on cavity separable convolution and attention mechanism[J]. Journal of Image and Graphics, 2022, 27(4): 1216–1225. doi: 10.11834/jig.200729. [20] 高翔, 李春庚, 安居白. 基于注意力和多标签分类的图像实时语义分割[J]. 计算机辅助设计与图形学学报, 2021, 33(1): 59–67. doi: 10.3724/SP.J.1089.2021.18233.GAO Xiang, LI Chungeng, and AN Jubai. Real-time image semantic segmentation based on attention mechanism and multi-label classification[J]. Journal of Computer-Aided Design & Computer Graphics, 2021, 33(1): 59–67. doi: 10.3724/SP.J.1089.2021.18233. [21] ARANI E, MARZBAN S, PATA A, et al. RGPNet: A real-time general purpose semantic segmentation[C]. IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, USA, 2021: 3008–3017. doi: 10.1109/WACV48630.2021.00305. [22] ZHOU Quan, WANG Yu, FAN Yawen, et al. AGLNet: Towards real-time semantic segmentation of self-driving images via attention-guided lightweight network[J]. Applied Soft Computing, 2020, 96: 106682. doi: 10.1016/j.asoc.2020.106682. [23] WANG Xiaotian and CAO Weiqun. MRFDCNet: Multireceptive field dense connection network for real-time semantic segmentation[J]. Mobile Information Systems, 2022, 2022: 6100292. doi: 10.1155/2022/6100292. [24] ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 6230–6239. doi: 10.1109/CVPR.2017.660. [25] LI Gen, JIANG Shenlu, YUN I, et al. Depth-wise asymmetric bottleneck with point-wise aggregation decoder for real-time semantic segmentation in urban scenes[J]. IEEE Access, 2020, 8: 27495–27506. doi: 10.1109/ACCESS.2020.2971760. [26] WANG Xizhong, LIU Rui, DONG Jing, et al. Lightweight real-time image semantic segmentation network based on multi-resolution hybrid attention mechanism[J]. Wireless Communications and Mobile Computing, 2022, 2022: 3215083. doi: 10.1155/2022/3215083. -

 下载:
下载:


图(4) / 表(8)
计量
- 文章访问数: 99
- HTML全文浏览量: 47
- PDF下载量: 26
- 被引次数: 0
